The Simplest Way to
Test Models and Prompts
Create your own custom evals to test models and prompts for your use case.
No sign-up. No login. No coding. Just evals.
Workspace for model eval and prompt engineering
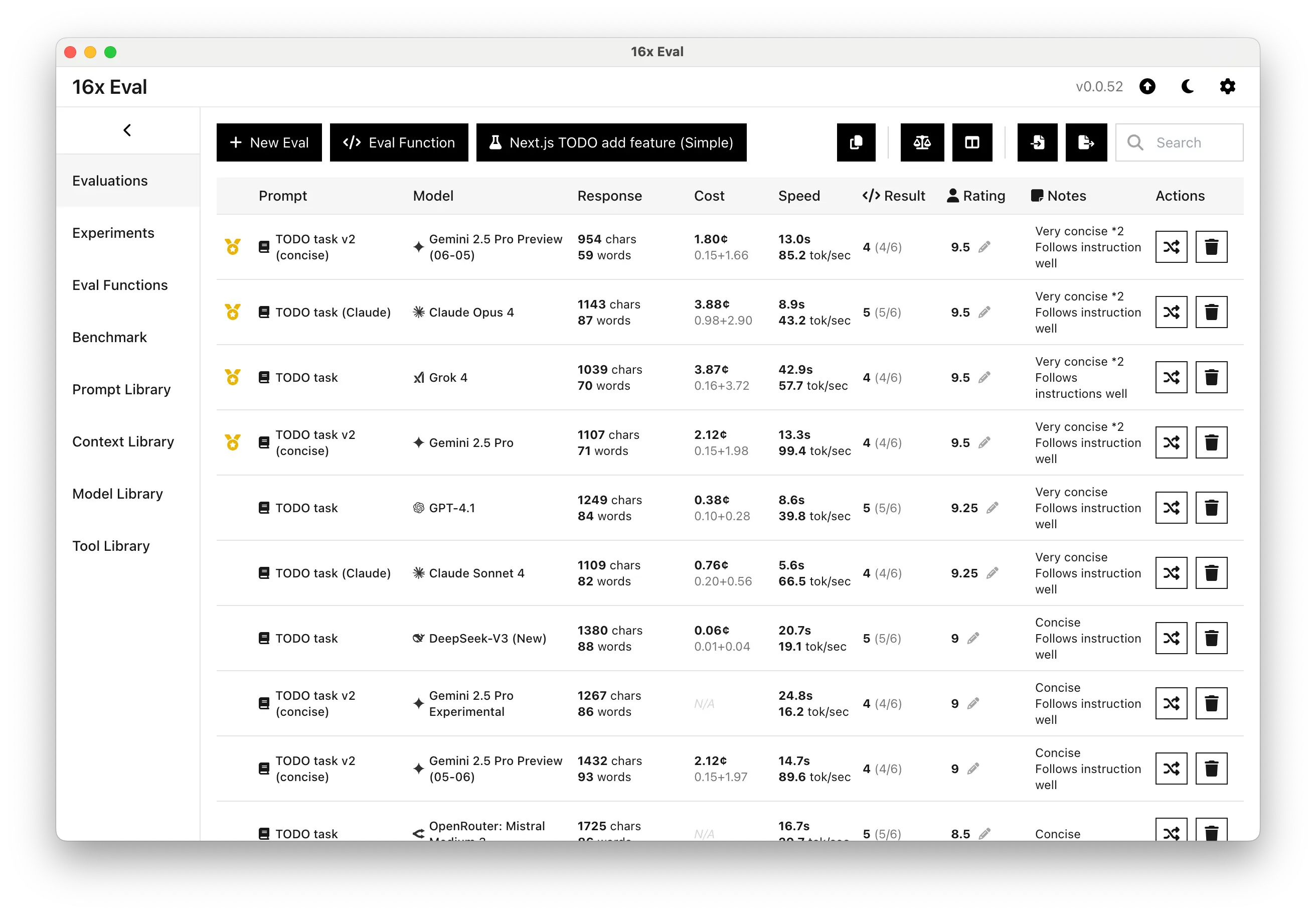
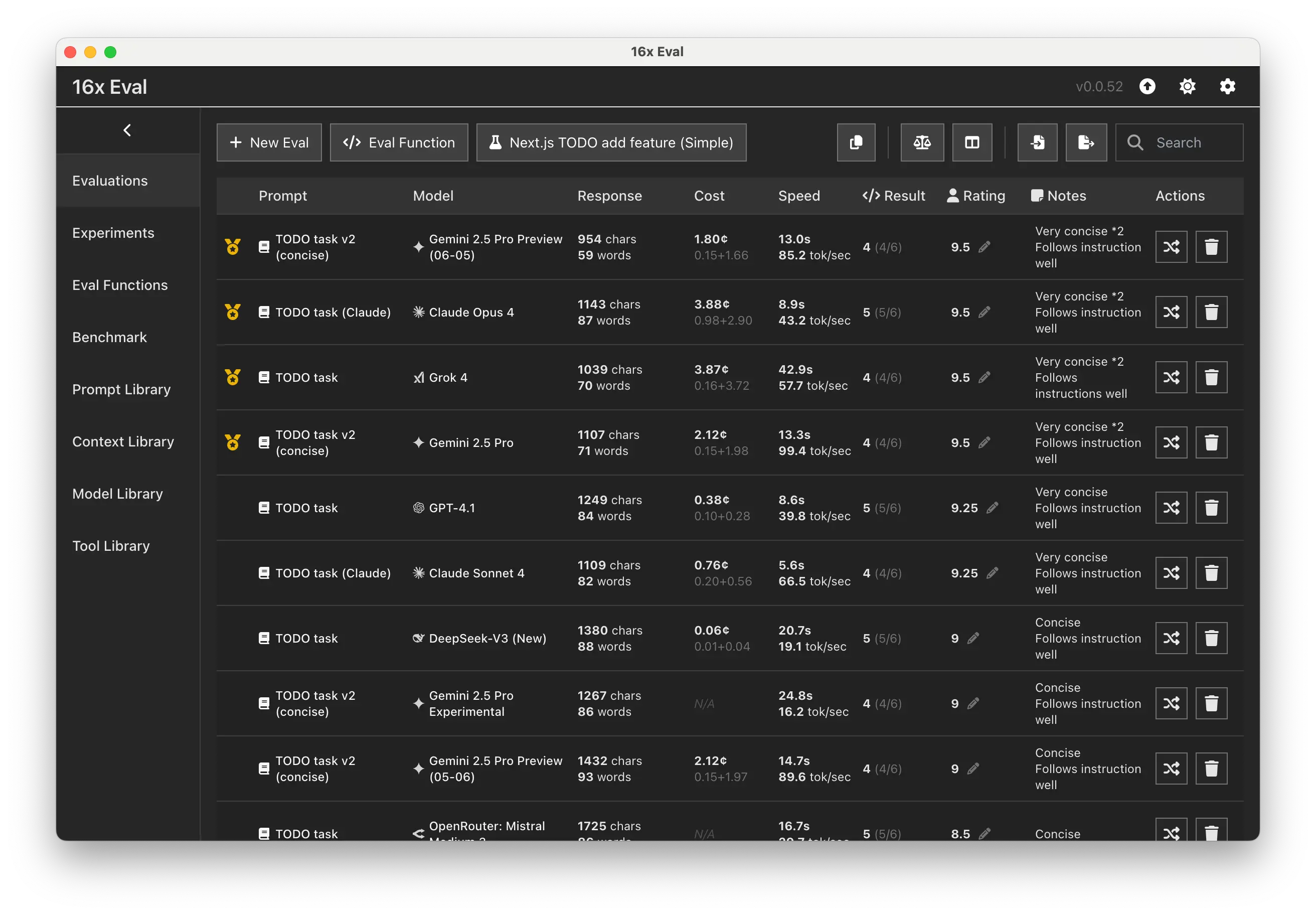
Manage your prompts, contexts, and models in one place, locally on your machine. Test out different combinations and use cases with a few clicks.
Prompt Evaluation
Model Evaluation
Evaluation Function
Rubrics & Human Rating
BYOK API Integrations
Cost Tracking
Experiment Management
Tool Call Support
16x Eval Video Demo
Learn how 16x Eval works in this video demo.
Run Evaluations across Multiple Models
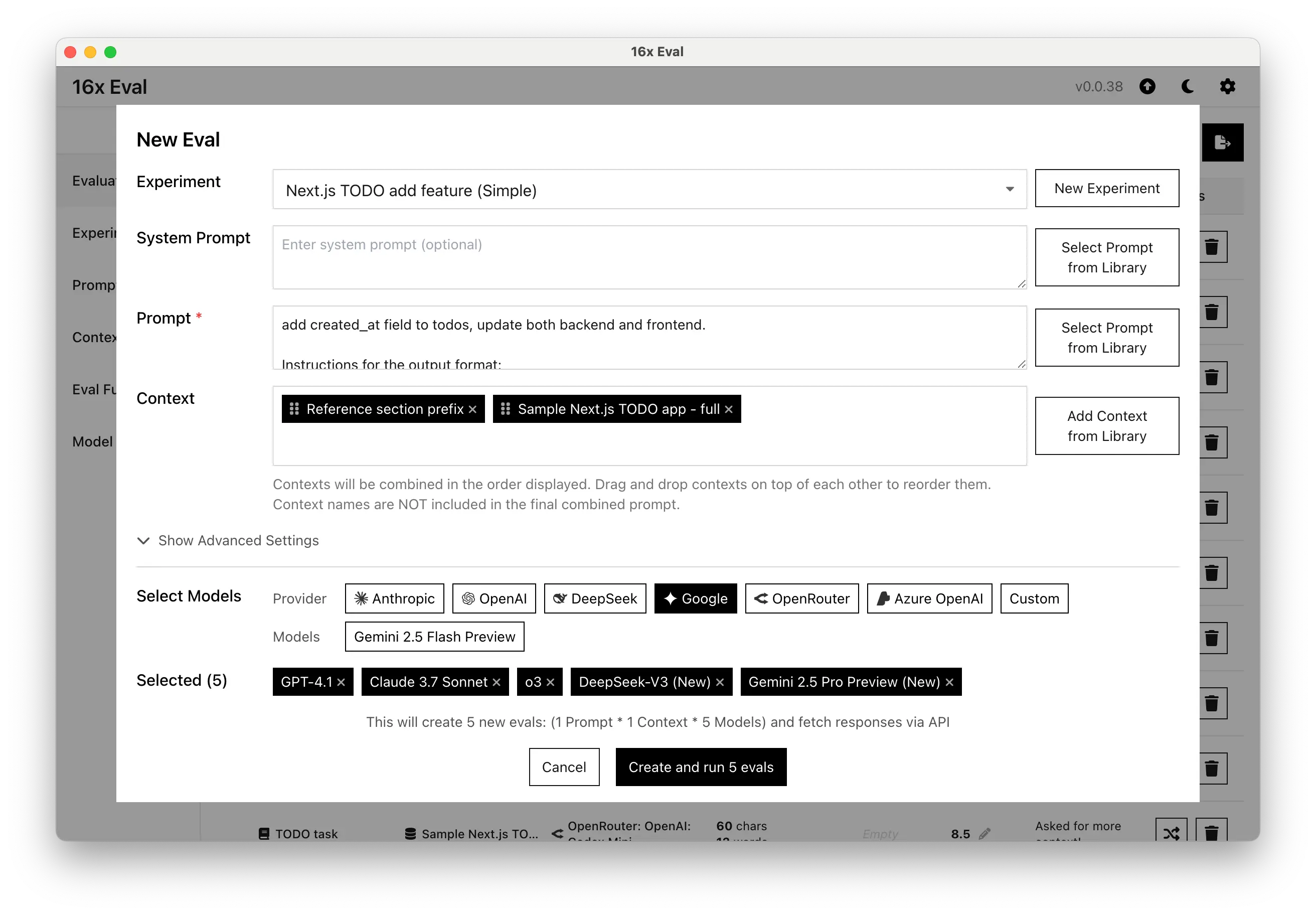
Run Evaluations across Multiple Models
Create new evaluations by specifying prompt, context and models. Multiple contexts will be combined together and added to the final prompt.
You can select multiple models to evaluate the same prompt and context in parallel.
Adjust advanced settings like prompt structure and temperature for more control over your evaluations.
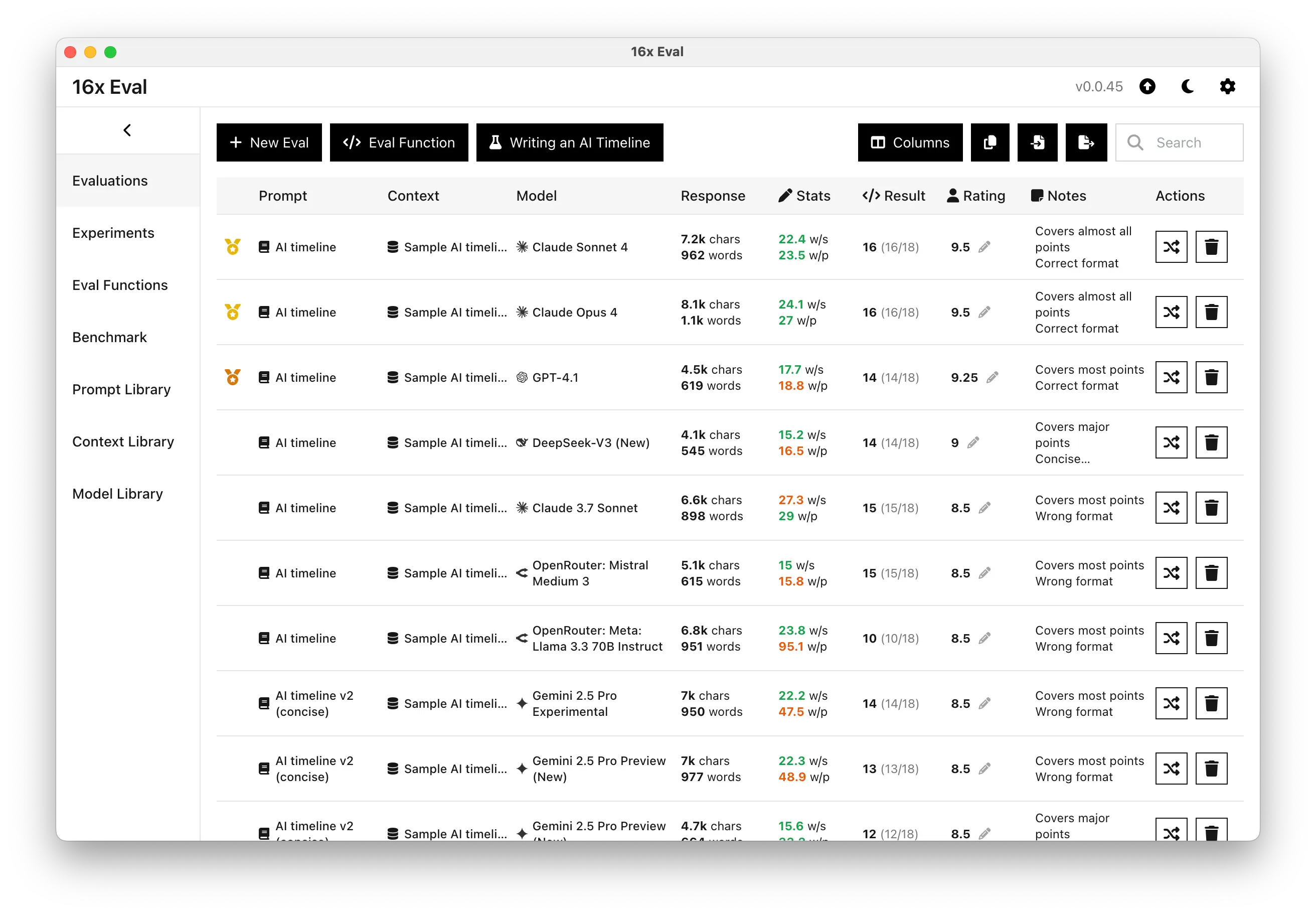
View and Compare Evaluation Results
View and Compare Evaluation Results
Analyze your evaluation results with comprehensive metrics including cost tracking, reasoning tokens, and performance statistics. Add personal notes to annotate your results.
Compare results from different prompt variations and models in a friendly table format. Use medal rankings and sorting by cost, speed, and rating to easily identify which combinations perform best for your specific use cases.
Side-by-Side Results Comparison
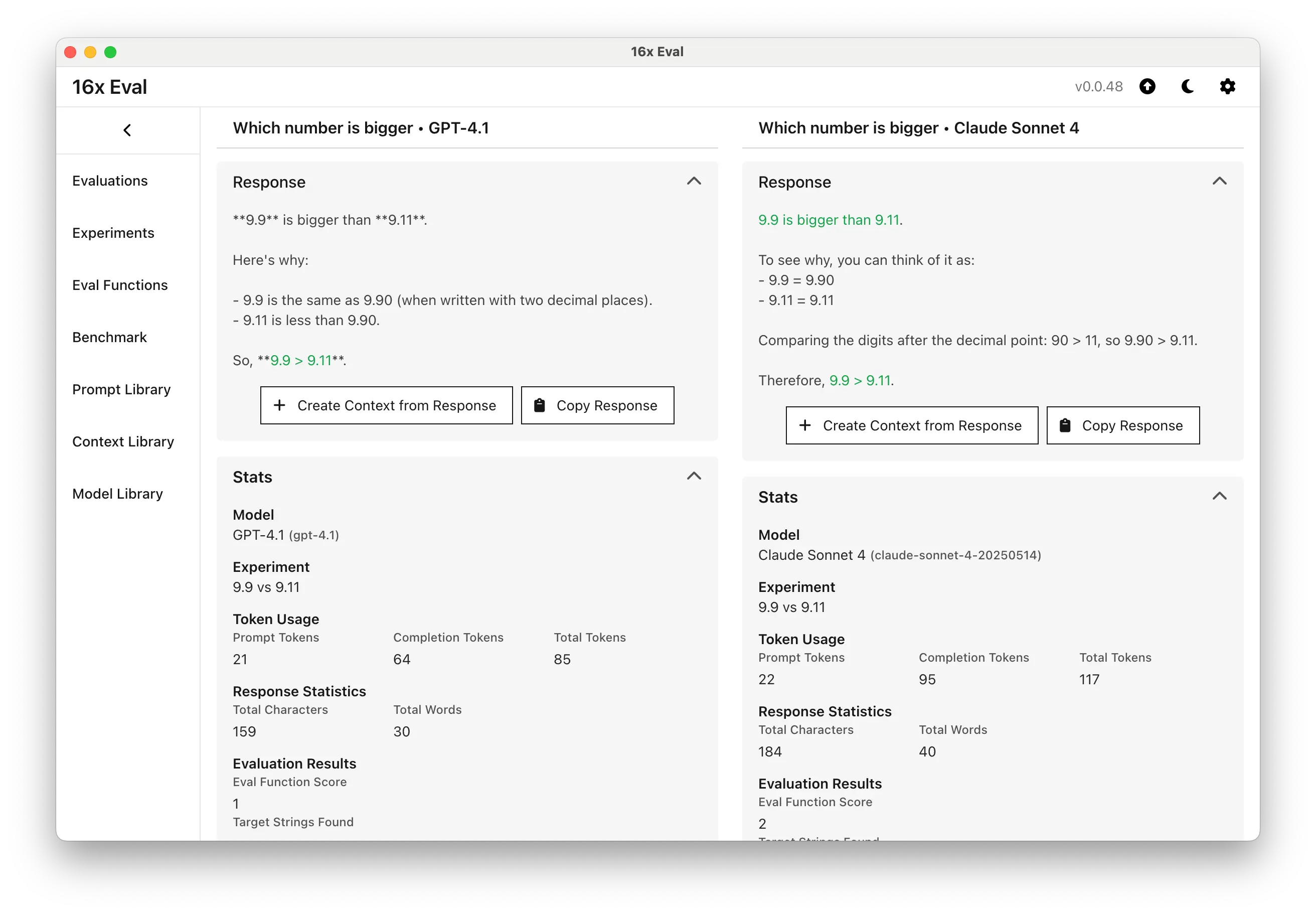
Side-by-Side Results Comparison
Compare different results side-by-side with the details on the prompt, context and model. Evaluate responses and metrics to understand how different models handle your specific use cases.
Perfect for A/B testing prompts, comparing model performance, and making informed decisions about which model works best for your evaluation tasks.
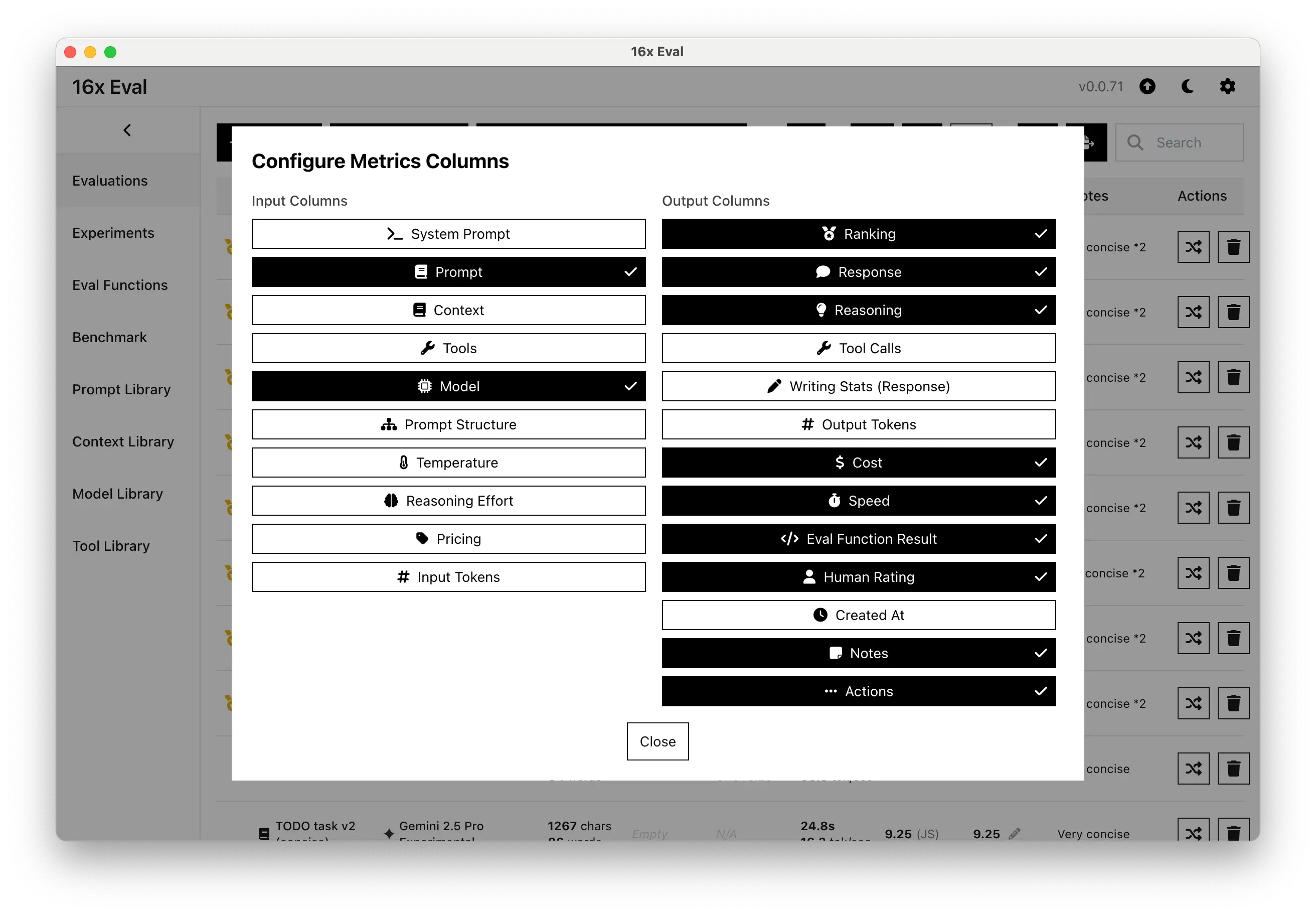
Customizable Columns for Metrics
Customizable Columns for Metrics
Tailor your evaluation table to your specific needs with customizable columns. Show or hide columns based on which metrics is most important to you.
For example, you can track input and output token statistics, prompt structure, evaluation function scores, price, cost, and throughput.
Organize and view your eval data in ways that make sense for your evaluation workflow.
Simple Evaluation Functions
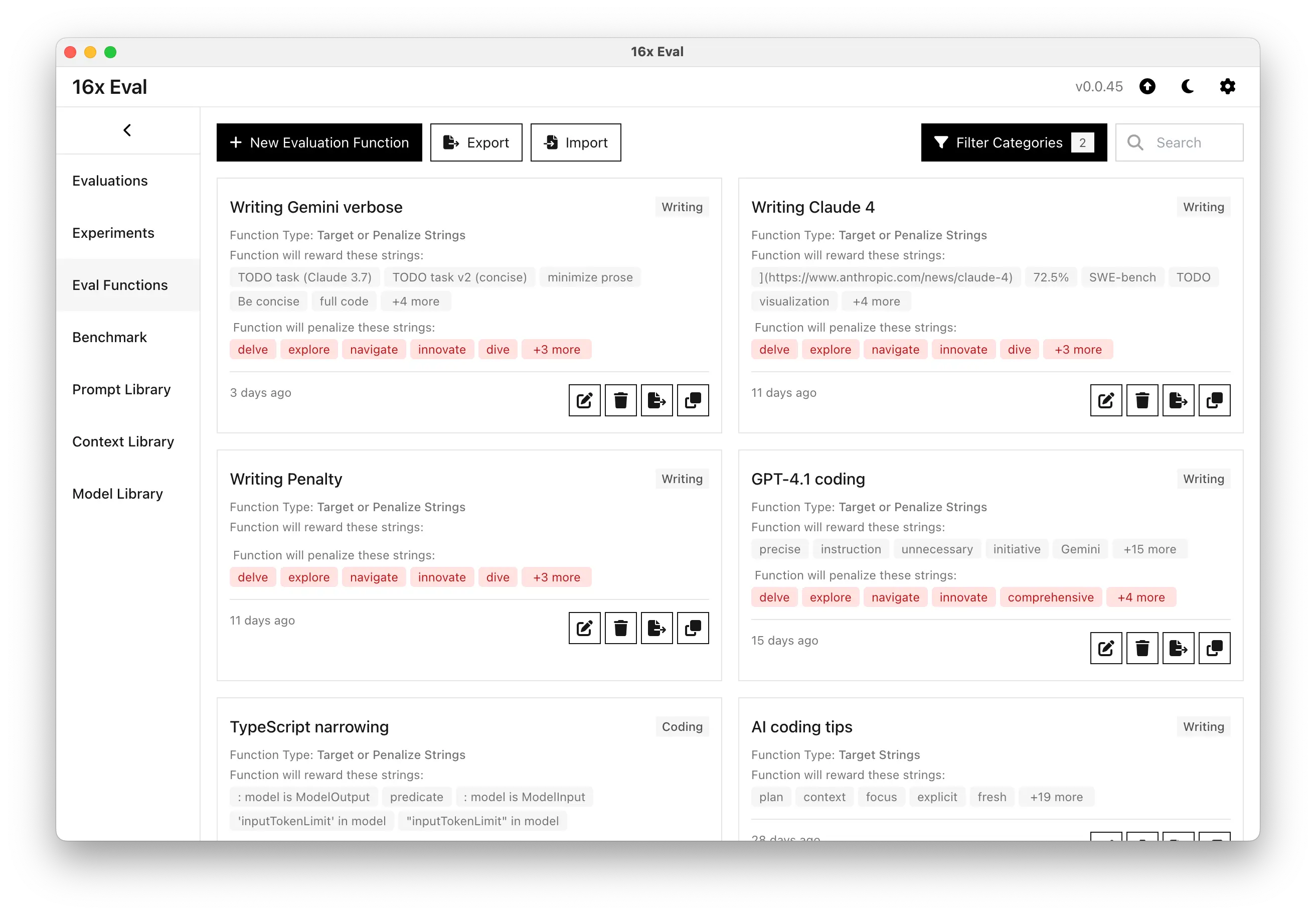
Simple Evaluation Functions
Create custom evaluation criteria using simple target and penalty strings to automatically score AI model responses.
Define target strings that should be included and penalty strings that should be avoided. Responses are automatically scored based on your criteria.
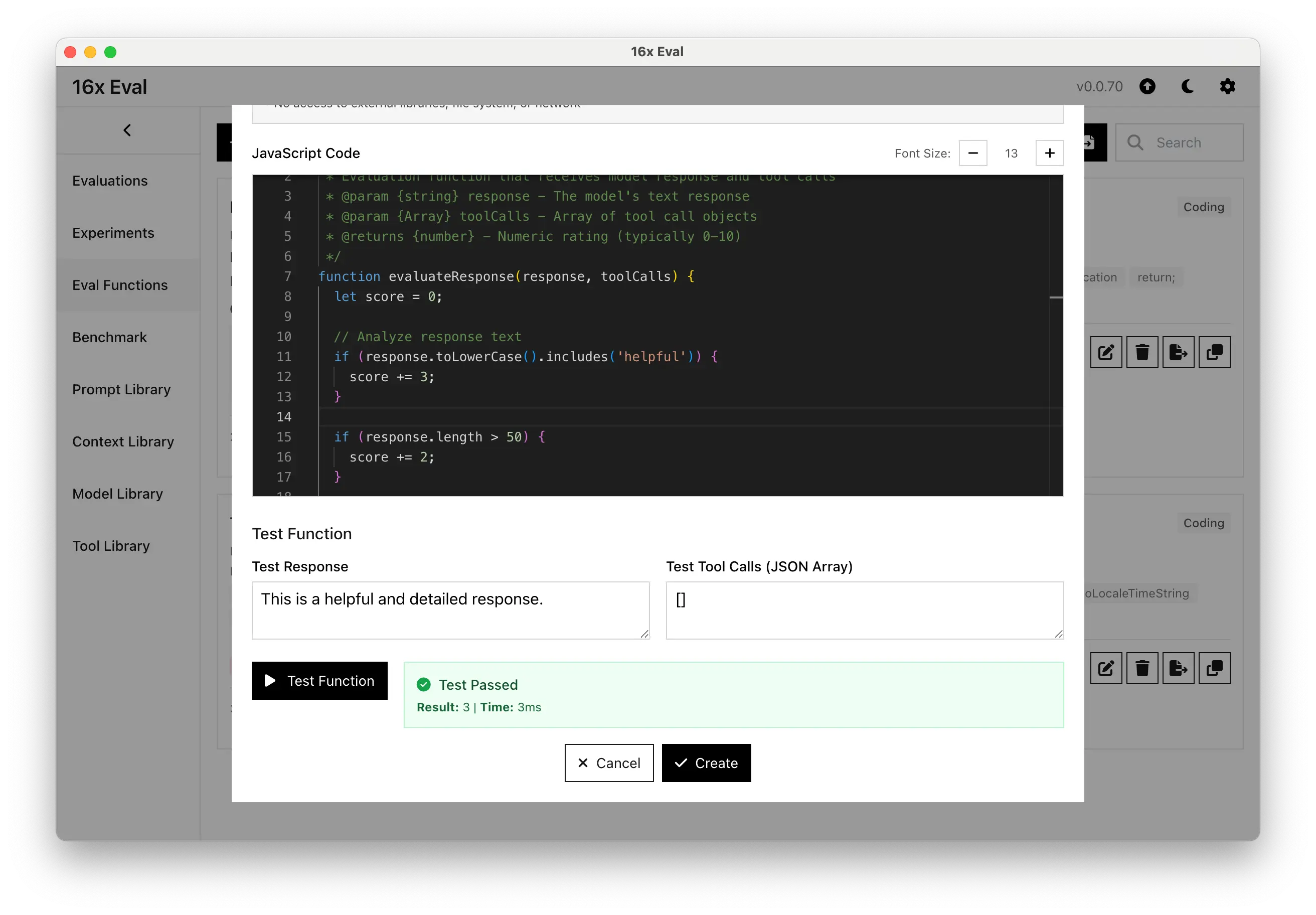
JavaScript Evaluation Functions
JavaScript Evaluation Functions
Write your own custom JavaScript functions to evaluate AI model responses with complete flexibility and control.
Perfect for complex evaluation logic, tool call validation, and advanced scoring algorithms that go beyond simple string matching.
Rubrics for Consistent Human Rating
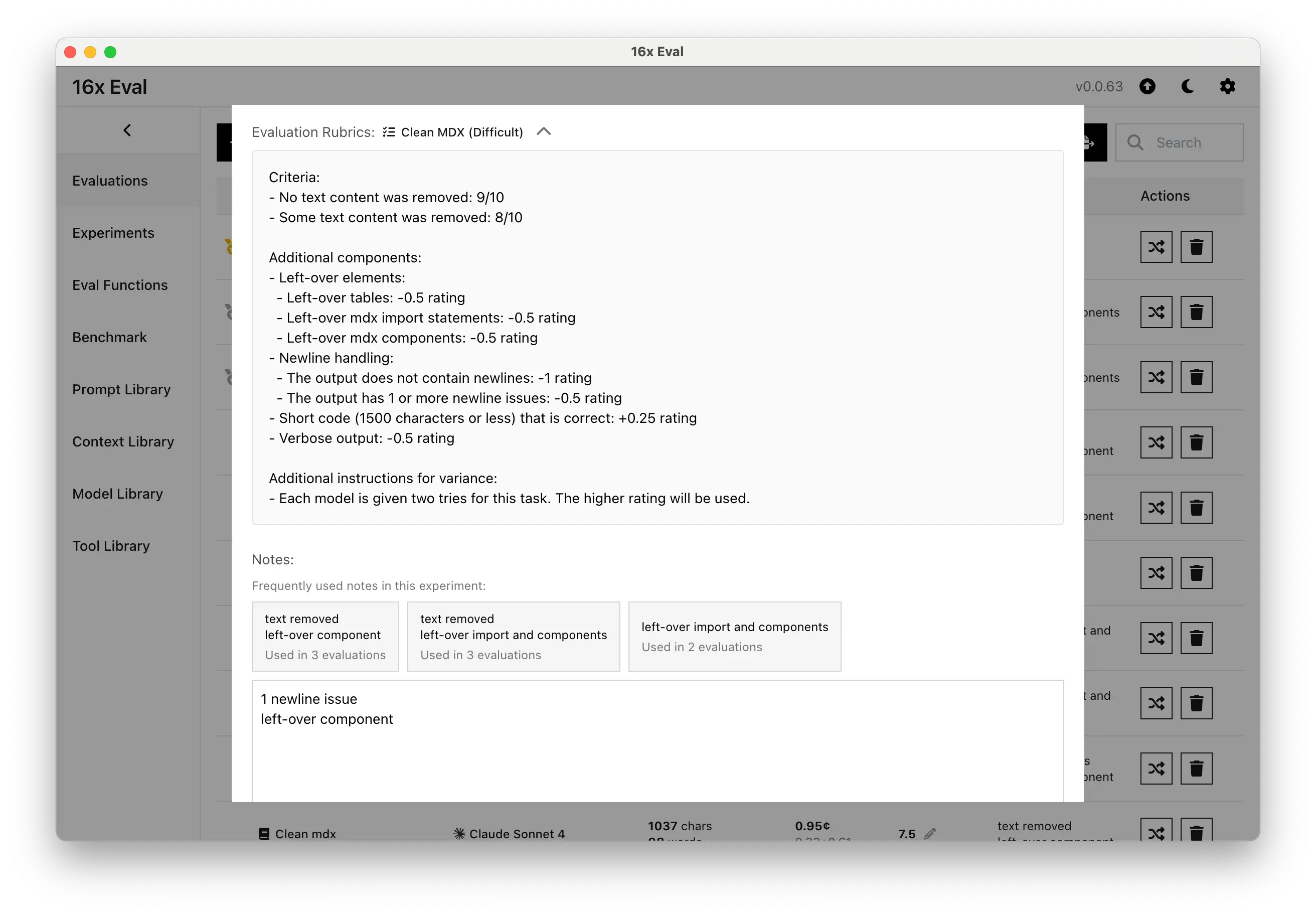
Rubrics for Consistent Human Rating
Define evaluation criteria with experiment rubrics to ensure consistent assessment across all your evaluations. Set clear standards for what constitutes good performance.
Add notes to your evaluations with suggested notes from experiment history. Track insights, observations, and learnings systematically to improve your prompt engineering workflow.
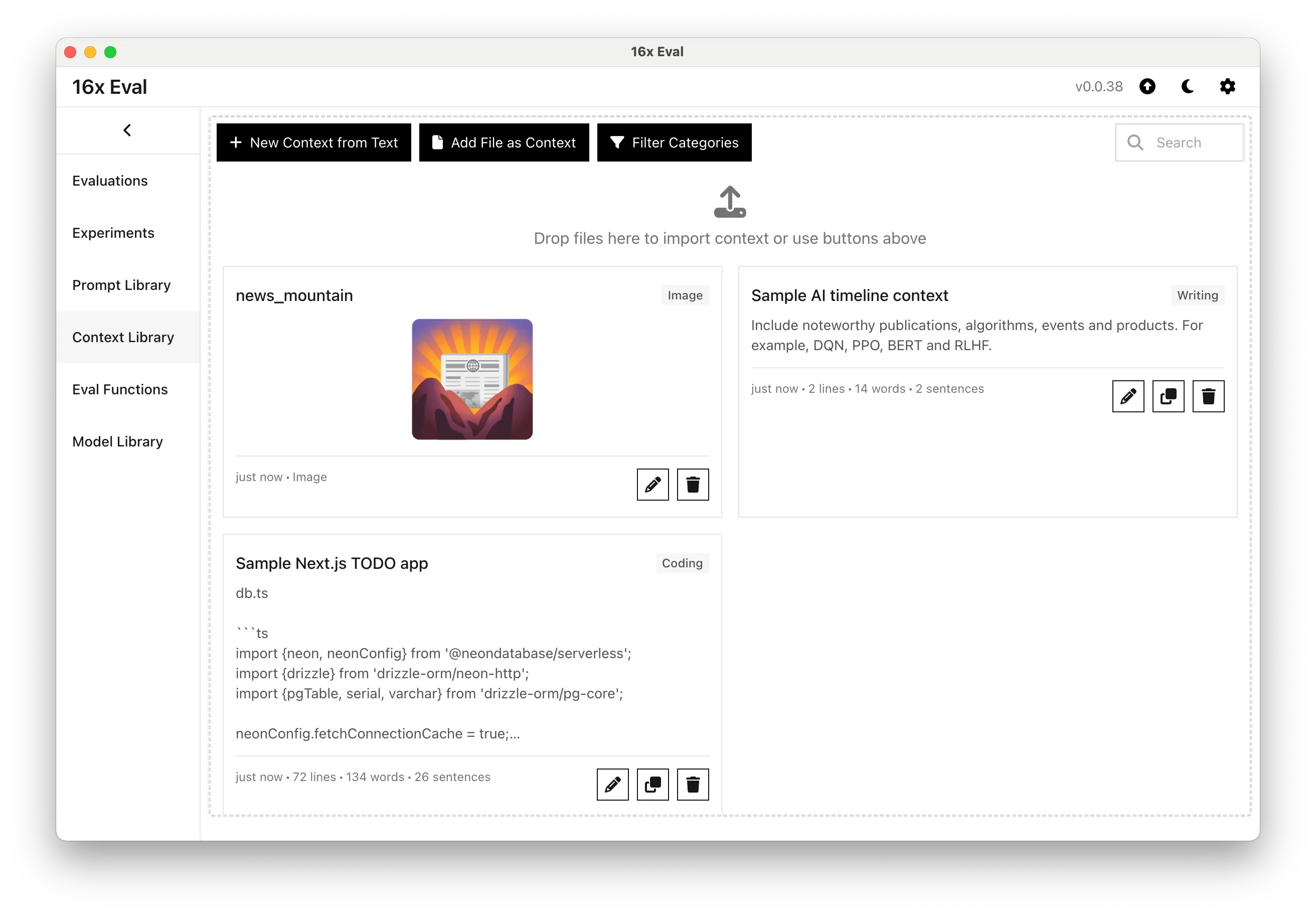
All Prompts and Contexts in One Place
All Prompts and Contexts in One Place
Import and manage both text and image contexts for your evaluations. Use the drag and drop interface to easily add new prompts and contexts or import them from files.
Organize your prompts and contexts into categories to make them easier to find, or archive them to keep them out of the way.
Organize Evaluations into Experiments
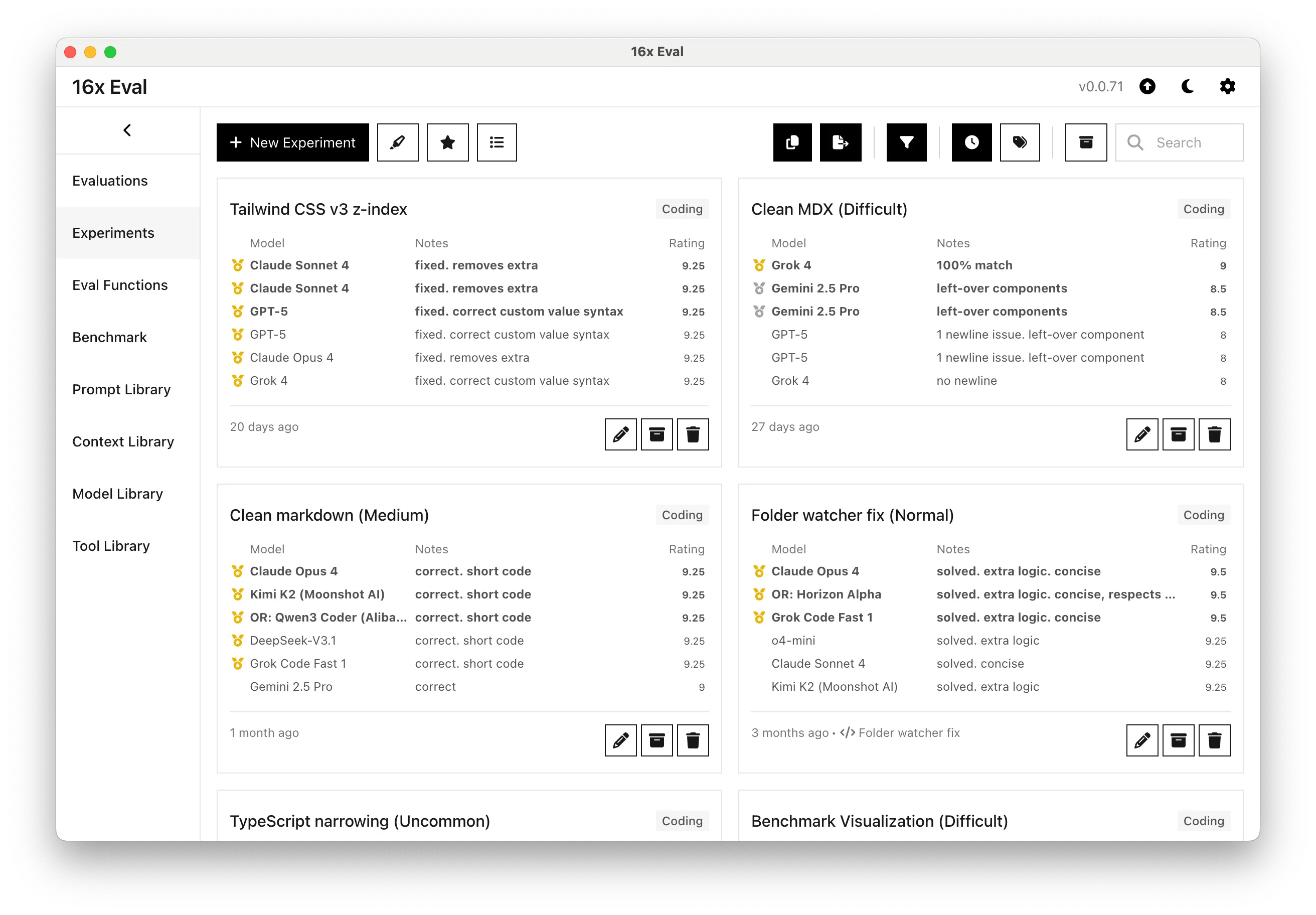
Organize Evaluations into Experiments
Group evaluations into experiments to organize and categorize your testing for different use cases (coding, writing, question answering, etc).
Experiments support categories, archiving, and linking with evaluation functions to automatically enable the right functions for your specific use case.
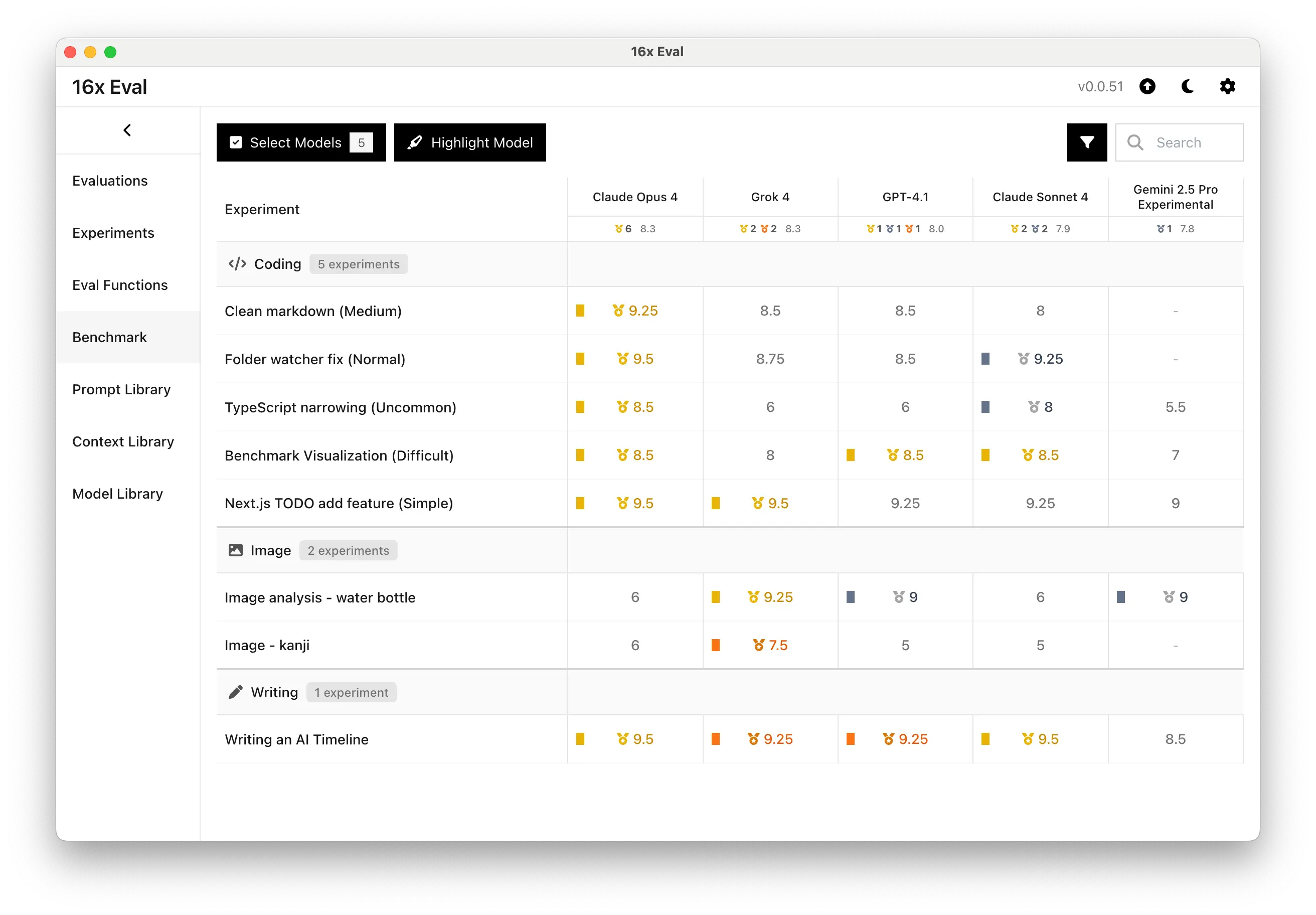
Compare Models with Benchmark Page
Compare Models with Benchmark Page
View and compare model performance at a glance across different categories of tasks with the benchmark page.
Select models and categories to create your own local benchmark for your own use cases.
Built-in Models and Custom Models
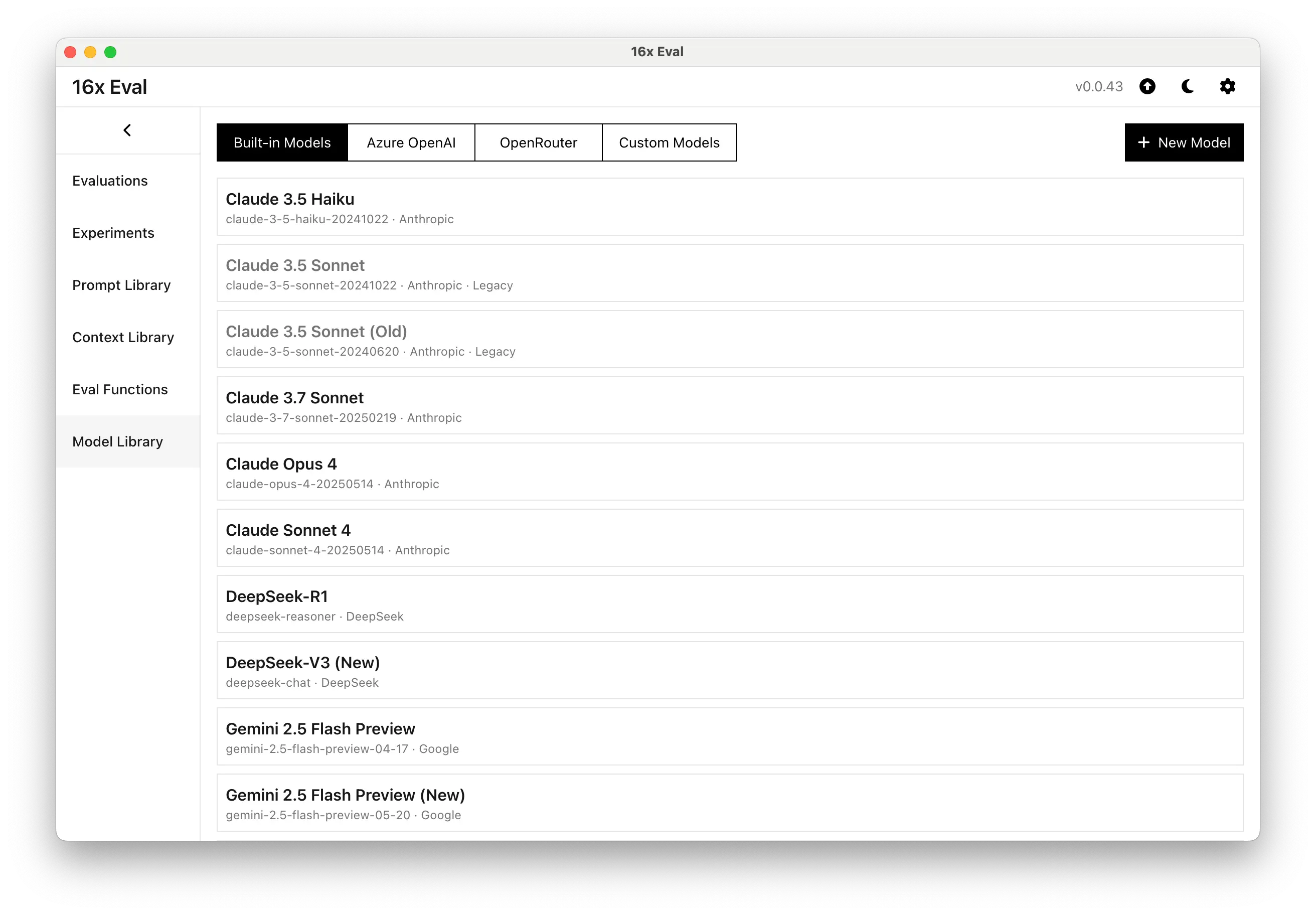
Built-in Models and Custom Models
16x Eval has built-in support for top models from various providers like OpenAI, Anthropic, Google, DeepSeek, Azure OpenAI, OpenRouter, and xAI.
We also support any other providers that offers OpenAI API compatibility, such as locally running Ollama or Fireworks.
16x Eval is a BYOK (Bring Your Own Key) application. You'll need to provide your own API keys these providers to use the application.
16x Eval Use Cases
See how 16x Eval fits into your different use cases.
Coding Task Evaluation
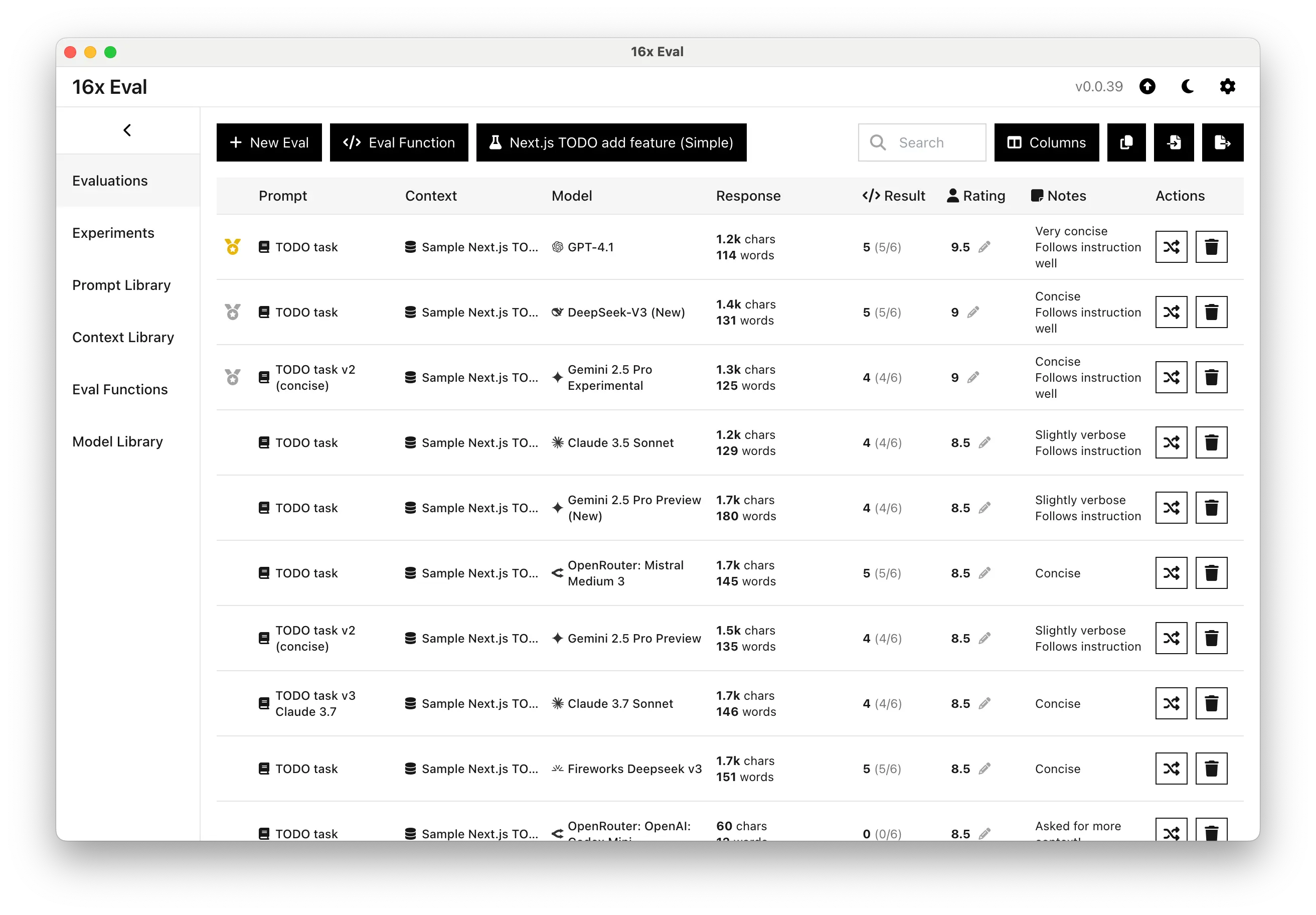
Coding experiment with prompt to add a feature to a TODO app
Evaluate and compare AI models for coding tasks. Perfect for developers who want to assess the quality and accuracy of AI-generated code.
- Compare multiple models
- Test different prompts
- Custom evaluation functions
- Response rating system
- Add notes to each response
- Various token statistics
Writing Task Evaluation
Watch a video demo of writing task evaluation
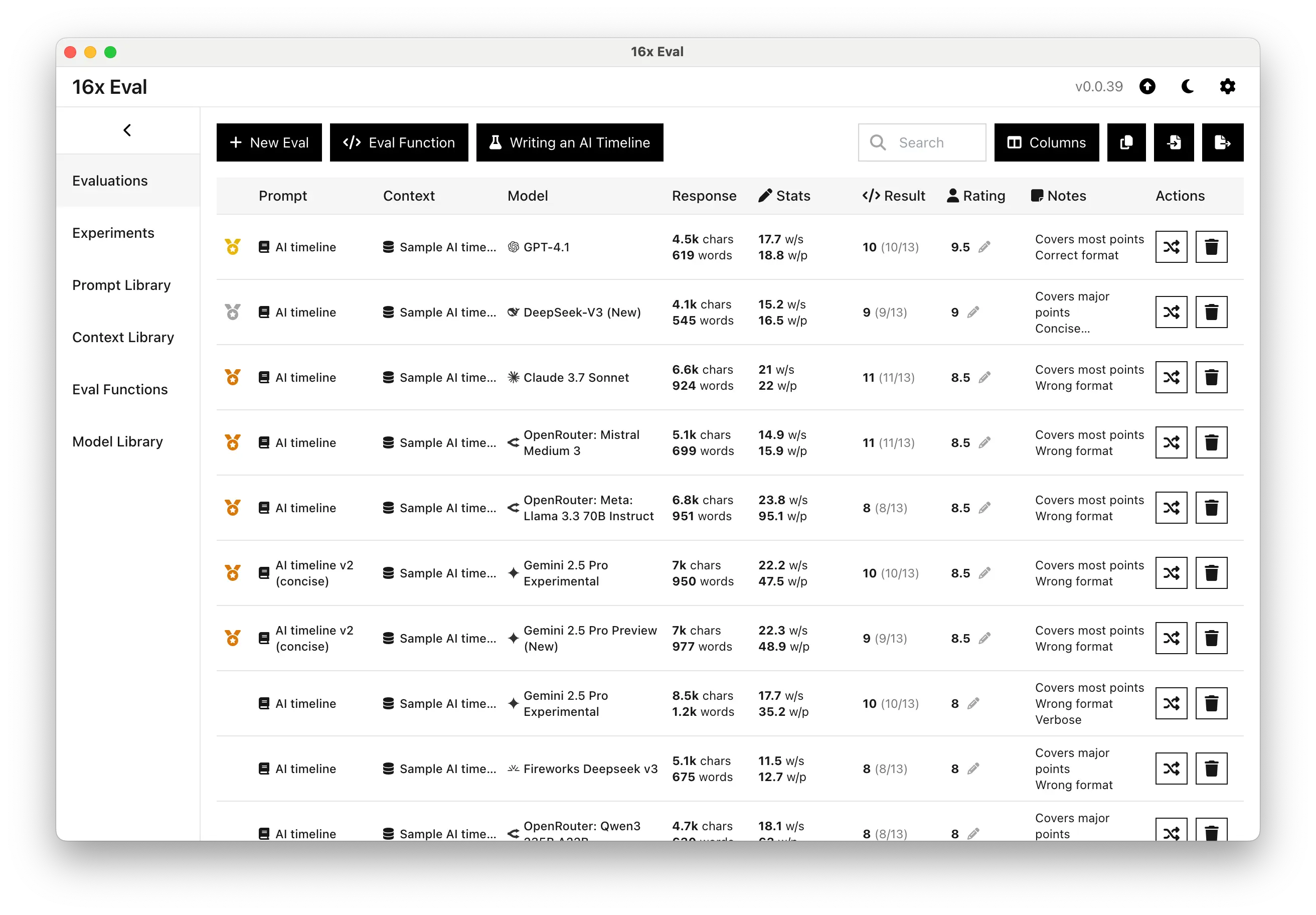
Writing experiment with prompt to write an AI timeline
Compare AI models for writing tasks. Ideal for content creators, writers, and AI builders using AI-assisted workflows for writing.
- Compare multiple models
- Test different prompts
- Highlight target text and penalty text
- Writing statistics (words per sentence and paragraph)
- Custom evaluation functions
- Add notes to each response
Image Analysis Task Evaluation
Watch a video demo of image analysis task evaluation
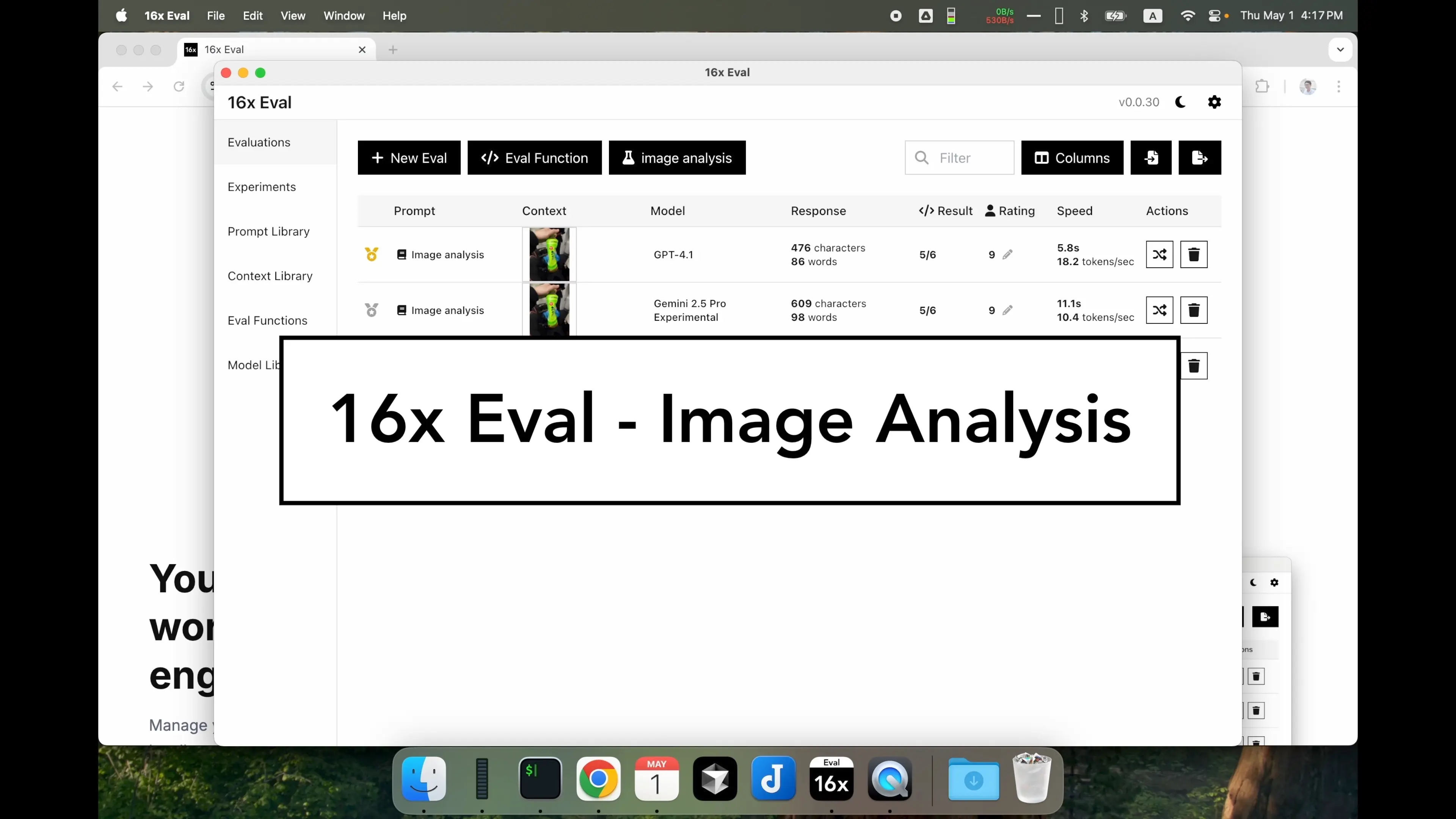
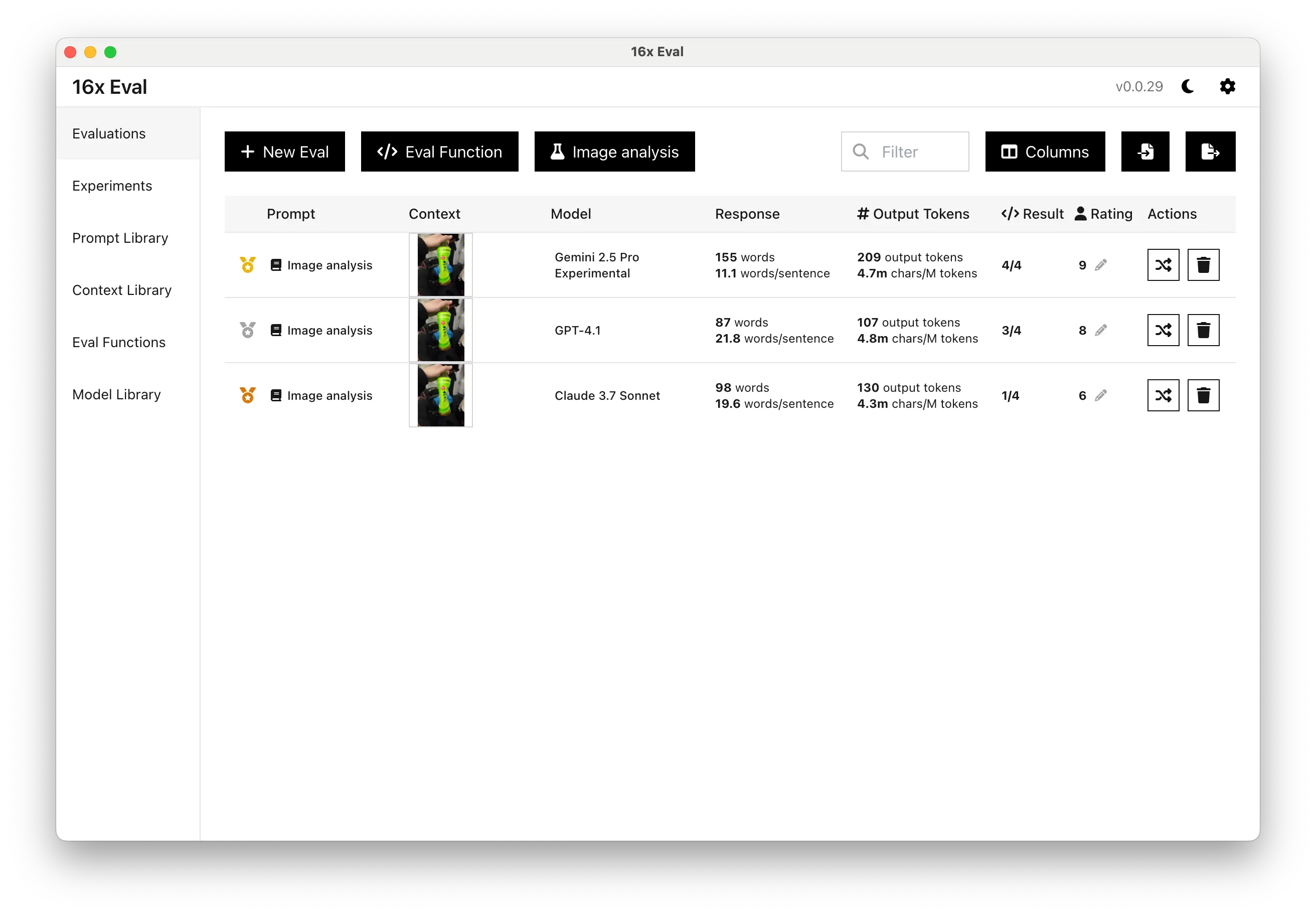
Image analysis experiment with prompt "Explain what happened in the image."
Evaluate AI models for image analysis tasks. Great for AI builders and researchers assessing how different AI models interpret and analyze visual content.
- Visual content analysis
- Multiple model comparison
- Custom evaluation criteria
- Response rating system