
Many people rely on public benchmarks and leaderboards to choose the "best" AI model. While these rankings seem helpful, they often do not reflect how a model will perform on your specific, real-world tasks.
People who solely rely on benchmarks miss a critical insight: Performance on real-world tasks depends on the combination of the model, the prompt, the context, and the task.
In this post, we will take a look at the limitations of generic benchmarks and explain why a personalized evaluation strategy is more effective. You will learn how to move beyond simple rankings to find the right AI for your needs.
The Issues with Generic Benchmarks
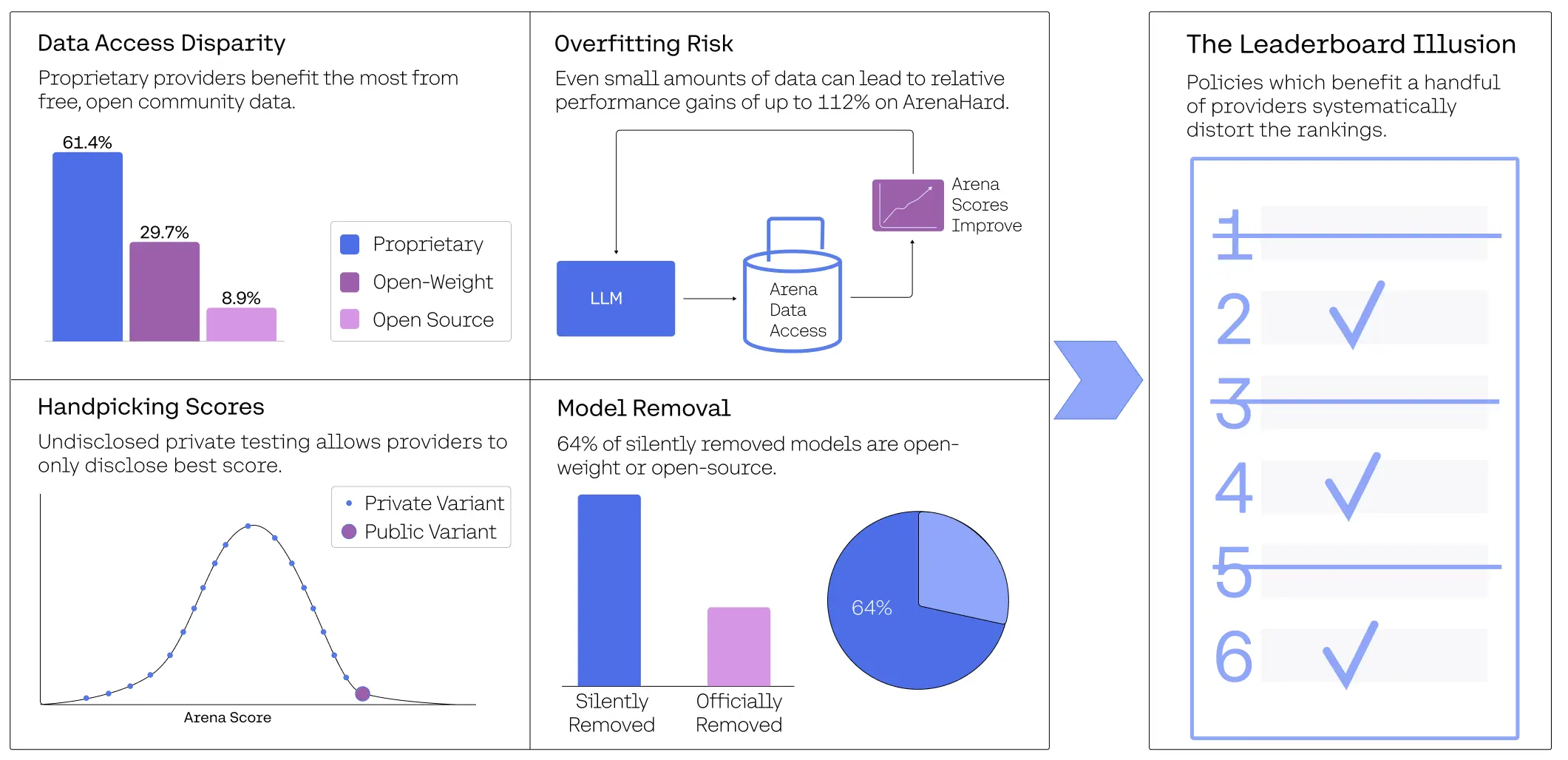
While benchmarks play a central role in measuring AI progress, they come with significant limitations. A paper titled The Leaderboard Illusion highlights systematic issues like selective reporting and private testing that can distort rankings on Chatbot Arena. These practices can create a playing field where scores do not accurately represent a model's general capabilities.
Another issue with popular benchmarks is that the data is "leaked" into the training data of the models. This means that the models may have been trained on data on which they are later being tested (contamination), and therefore they are likely to perform well on the benchmarks. This is particularly problematic for benchmarks that rely on old public data that were present before the models' training cut-off date.
For example, Aider's polyglot benchmark uses 225 challenging Exercism coding exercises, but some of the Exercism problems were created between 2021 and 2023 and publicly available on GitHub, before the training cut-off date of the newer models like GPT-5 (Sep 2024) and Claude Sonnet 4 (Mar 2025).
Many popular "vibe checks" also target the wrong things by focusing on artificial puzzles instead of real-world use cases. For example, asking an AI to count letters in the word "strawberry" is a common test. However, this primarily shows the model's limitation on tasks involving characters due to tokenization, rather than a practical skill you would use in an application.
Similarly, questions like "which is bigger: 9.9 or 9.11" are ambiguous without context. The answer changes depending on whether you are talking about math, software versions, or book chapters. Hence it does not measure a model's ability to handle real tasks with proper context.
The Prompt and Model Compatibility Puzzle
Finding the right AI setup is like solving a jigsaw puzzle. The prompt, the context, and the model must all fit together perfectly to get the desired outcome for a specific task. A great prompt for one model might perform poorly on a different one, even if it is just a newer version from the same provider.

For example, in our testing, newer Claude models like Claude Sonnet 4 tend to output full code instead of only the changes. Stronger prompts are required to get the desired output. Gemini 2.5 Pro tends to give verbose output by default, but becomes concise with direct instruction like "Be concise."
This compatibility challenge exists because models from different providers have distinct characteristics. Each model requires a tailored approach to prompting to achieve the best results.
The styling instructions required for different types of tasks can also be different. For example, the instructions used for a coding task ("Be concise." for example) might not be suitable for a writing task due to the different context of the tasks, even if you are using the same model.
Success depends on finding the right prompt-model combination for your specific use case. Relying on a generic "best" model without testing it with your own prompts is unlikely to yield optimal results. It is the synergy between all the components that truly drives performance.
Factors Beyond Model Quality
A model's performance is not only about its raw intelligence or its ranking on a leaderboard. Several other factors can also influence the outcome. For example, simple adjustments to settings like temperature can dramatically reduce errors and improve the quality of the output for tasks that require high degree of accuracy.

Technical constraints also play a critical role in a model's suitability for a task. You need to consider factors like context window limits, token constraints, latency, and throughput. A model might be highly capable, but if it is too slow for your application or cannot handle the amount of context you need, it is not the right choice.
One particular example is reasoning models like Grok 4 and GPT-5 (high reasoning effort), which come with trade-offs between speed and quality. They are often slower than non-reasoning models due to the additional reasoning tokens they need to generate before outputting the final response.
Furthermore, a model's support for tool calls and function calling can also be important. Models that support tool calls might not have the same level of support in terms of the model's ability to pick the right tool or use the correct parameters.
These capabilities are not always captured in benchmarks that focus solely on text generation or reasoning. Evaluating a model requires looking at the complete picture, including all the technical and functional requirements of your project.
Building Your Own Evaluation
The core argument for personalized evaluation is simple: A model's benchmark score is meaningless if it cannot solve your specific problems. Instead of relying on external rankings, you should create evaluations tailored to your own real use cases. This ensures that you are testing for what actually matters to your application.
This approach is directly supported by model providers. For example, Anthropic recommends that users create benchmark tests specific to their use case. This involves testing with your actual prompts and data to compare how different models handle accuracy, quality, and edge cases for your tasks.
As captured by Anthropic's researcher Amanda Askell: write your tests first, then find the prompts that pass them.

This method shifts the goal from finding the single "best" model to finding the most effective tool for the job you need to do.
16x Eval is a desktop app designed to help you run systematic evaluations of LLMs on your own tasks.

You can use it to test how different models perform with different prompts and check the various metrics like response length, speed, and cost, helping you understand a model's capabilities and find the best prompt-model combination for your work.