Extracting structured data from tables within images is a challenging task for vision models. It requires not just recognizing text and numbers but also understanding the table's layout to correctly associate data points. We introduced a new task to test this specific capability.
In this post, we take a look at how various models performed on this image table data extraction task. Our evaluation results show a clear divide. Gemini 2.5 Pro and Claude Sonnet 4 handled the task perfectly, GPT-5 with high reasoning effort and Gemini 2.5 Flash gave decent results, while other leading models struggled significantly.
Evaluation Setup
The task required models to extract performance data for four specific models from a table in an image of Fiction.LiveBench benchmark. The image we used is reproduced below:
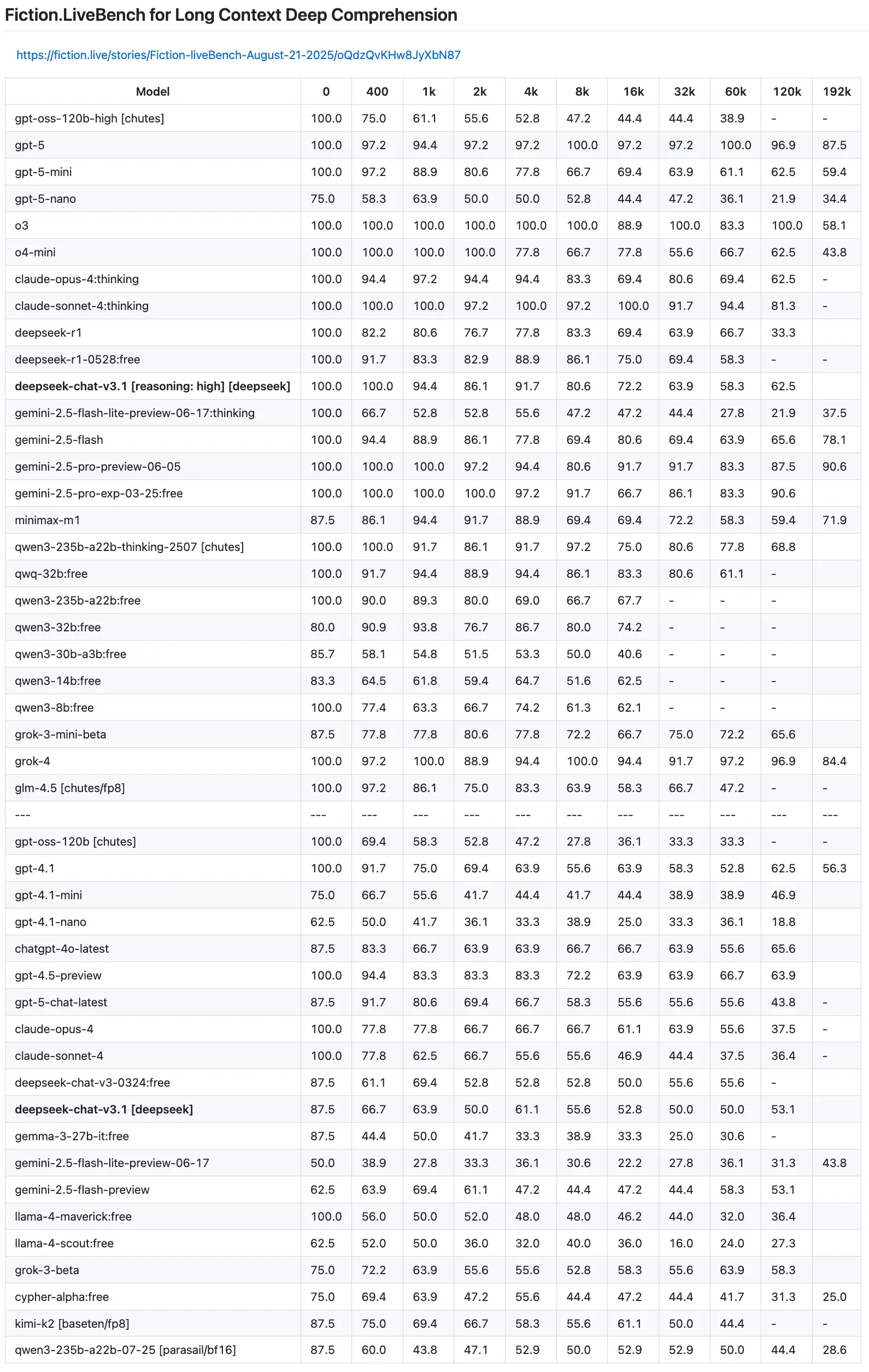
We crafted the prompt to be explicit about the required data and the desired output format:
Extract the Fiction.LiveBench performance data from the table in the image and return it in a structured format.
Extract the data from following 4 models for 8k, 32k and 192k:
- gpt-5
- deepseek-chat-v3.1 [reasoning: high] [deepseek]
- claude-sonnet-4:thinking
- claude-sonnet-4
Sample response format:
```
- gpt-oss-120b-high [chutes]: 47.2, 44.4, -
- gpt-4.1: 55.6, 58.3, 56.3
```
We send the prompt and the image to the models via the official API of the respective providers. We use default parameters for each model, including temperature and verbosity. For GPT-5, we test with both medium reasoning effort (default) and high reasoning effort.
Each model is given two attempts to complete the task, higher rating will be used as final rating. Ratings are assigned to the responses based on our evaluation rubrics, which is reproduced below:
Criteria:
- All 4 models are correctly extracted: 9.5/10
- 3 models are correctly extracted: 8/10
- 2 models are correctly extracted: 6/10
- 1 model is correctly extracted: 3/10
- 0 models are correctly extracted: 1/10
Additional instructions for variance:
- Each model is given two tries for this task. The higher rating will be used.
Top Performers: Gemini 2.5 Pro and Claude Sonnet 4
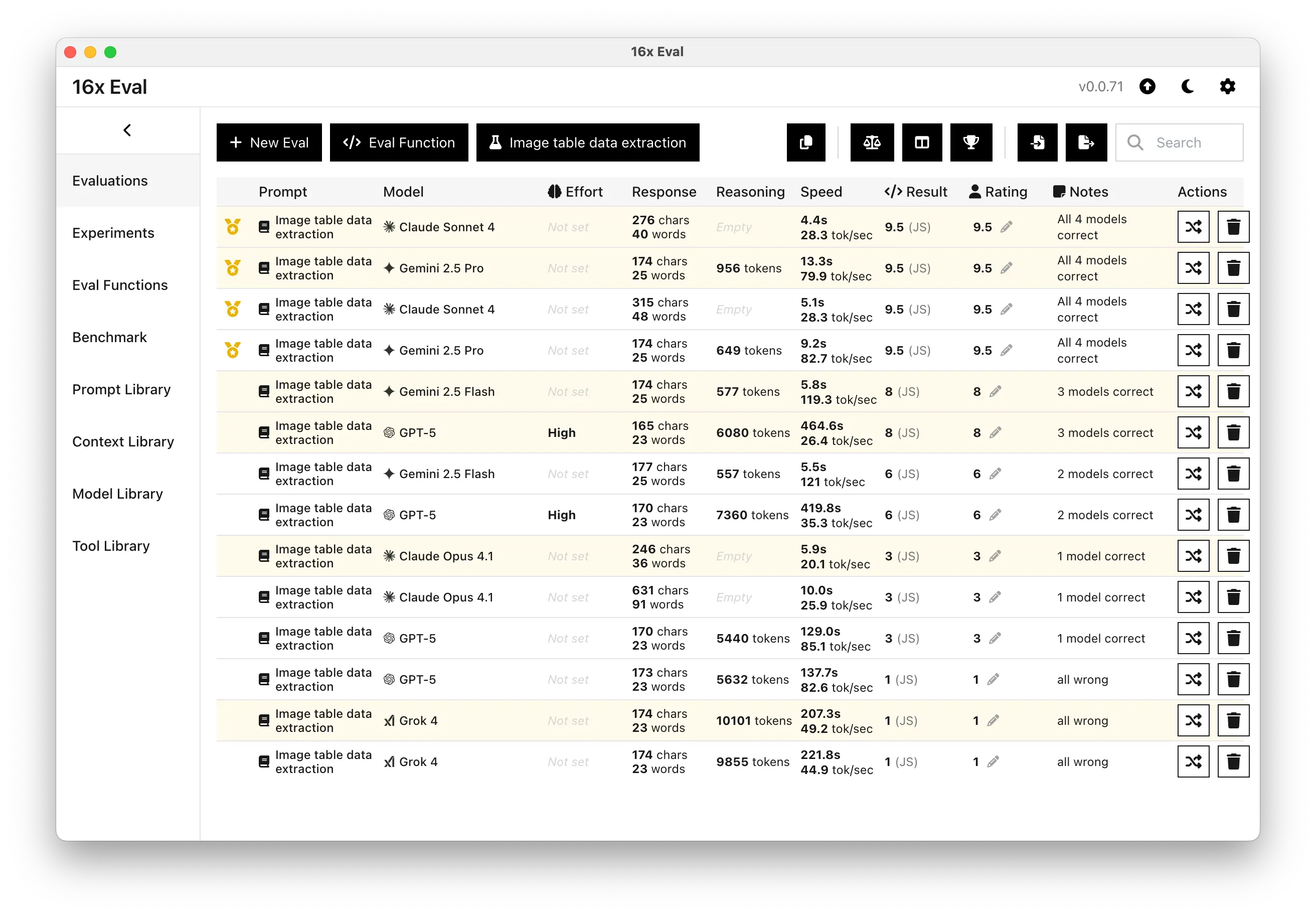
Gemini 2.5 Pro and Claude Sonnet 4 were the standout performers in this evaluation. Both models achieved a score of 9.5 out of 10 on both of their attempts. They successfully identified and extracted all the required data points from the table image.
This perfect performance shows their strong capabilities in processing complex visual information and adhering to structured output formats. Their success highlights a proficiency in tasks that blend vision with precise data handling.
Image Table Data Extraction Task Performance Comparison
Mixed and Poor Performance from Other Models
Other models did not manage to extract all data correctly. Gemini 2.5 Flash and GPT-5 on high reasoning effort delivered decent results. Both models scored 8/10 and 6/10 separately on two attempts.
The performance of other top-tier models was surprisingly low:
- Claude Opus 4.1 managed to extract one correct data point on both attempts, receiving a score of 3/10.
- GPT-5 on medium reasoning effort managed to extract one correct data point in one attempt, while failed to extract any correct data in the other attempt, receiving a final score of 3/10.
- Grok 4 failed this task completely, scoring just 1/10 for providing no correct data on both attempts.
Here's the detailed performance of the top models on the image table data extraction task:
Comparison with Other Image Tasks
With the addition of this new task, we now have 3 tasks in our image analysis evaluation set. Here is a summary of model performance across three different image tasks:
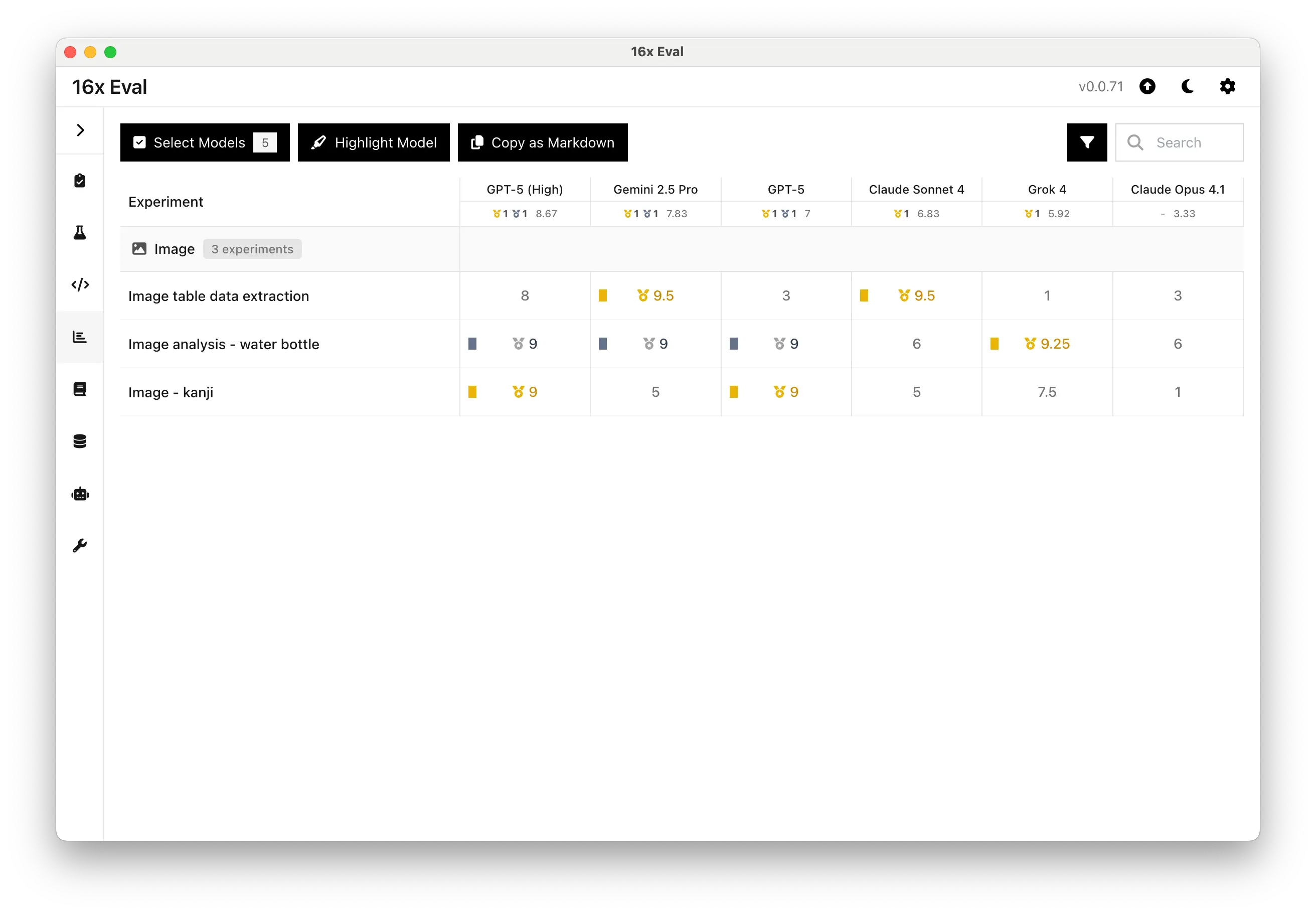
| Experiment | GPT-5 (High) | Gemini 2.5 Pro | GPT-5 | Claude Sonnet 4 | Grok 4 | Claude Opus 4.1 |
|---|---|---|---|---|---|---|
| Average Rating of 3 Image Tasks | 8.67 | 7.83 | 7 | 6.83 | 5.92 | 3.33 |
| --- | --- | --- | --- | --- | --- | --- |
| Image table data extraction | 8 | 9.5 | 3 | 9.5 | 1 | 3 |
| Image analysis - water bottle | 9 | 9 | 9 | 6 | 9.25 | 6 |
| Image - kanji | 9 | 5 | 9 | 5 | 7.5 | 1 |
Based on the results across all three tasks, we observed that high performance on one image task does not guarantee success in other image tasks:
- Gemini 2.5 Pro did well on 2 of the 3 tasks, but performed poorly on kanji image task.
- GPT-5 on medium reasoning effort has a good average rating for other image tasks, but performed poorly on image table data extraction task.
- Claude Sonnet 4 did poorly on other image tasks, but performed well on image table data extraction task.
We do note that GPT-5 to high reasoning effort did consistently well on all tasks, though not the top model for image table data extraction task. It is the overall top model for image analysis tasks.
The variation in performance highlights how a model's strengths can vary depending on the nature of the visual challenge, whether it is extracting data from a table or understanding the context of an image.
This evaluation was conducted using 16x Eval, a desktop application that helps you systematically test and compare AI models.

16x Eval makes it easier to run targeted evaluations like this one, allowing you to understand the specific strengths and weaknesses of different models for your use cases.
16x Model Evaluation Methodology
All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
We use default parameters from the provider's API for each model, unless explicitly stated otherwise. This includes temperature, verbosity, reasoning effort, and other parameters.
Prompt variations are used on a best-effort basis to perform style control across models.