0.0.71
September 10, 2025
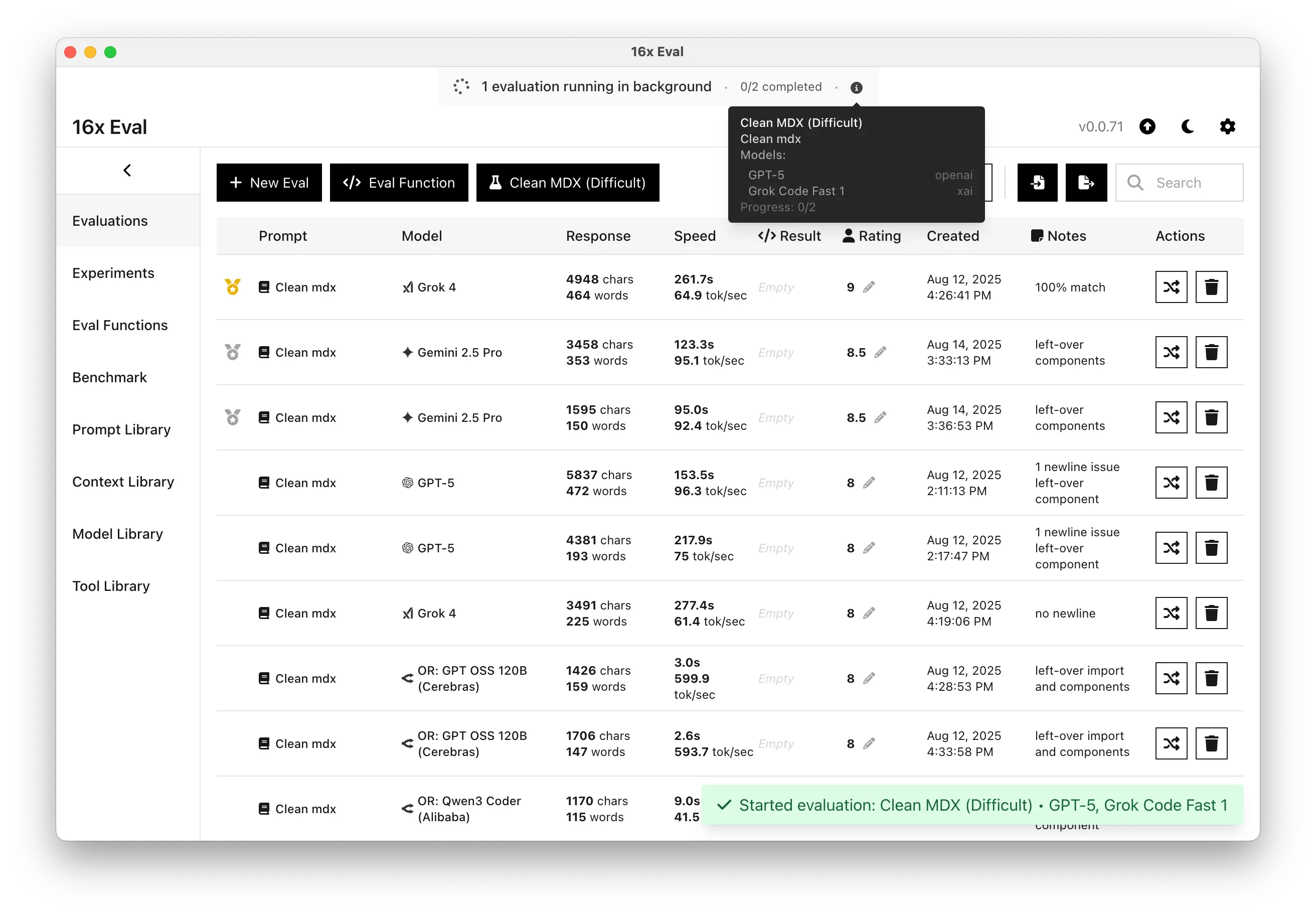
- Added support for background evaluation to run evaluations in the background without blocking the UI.
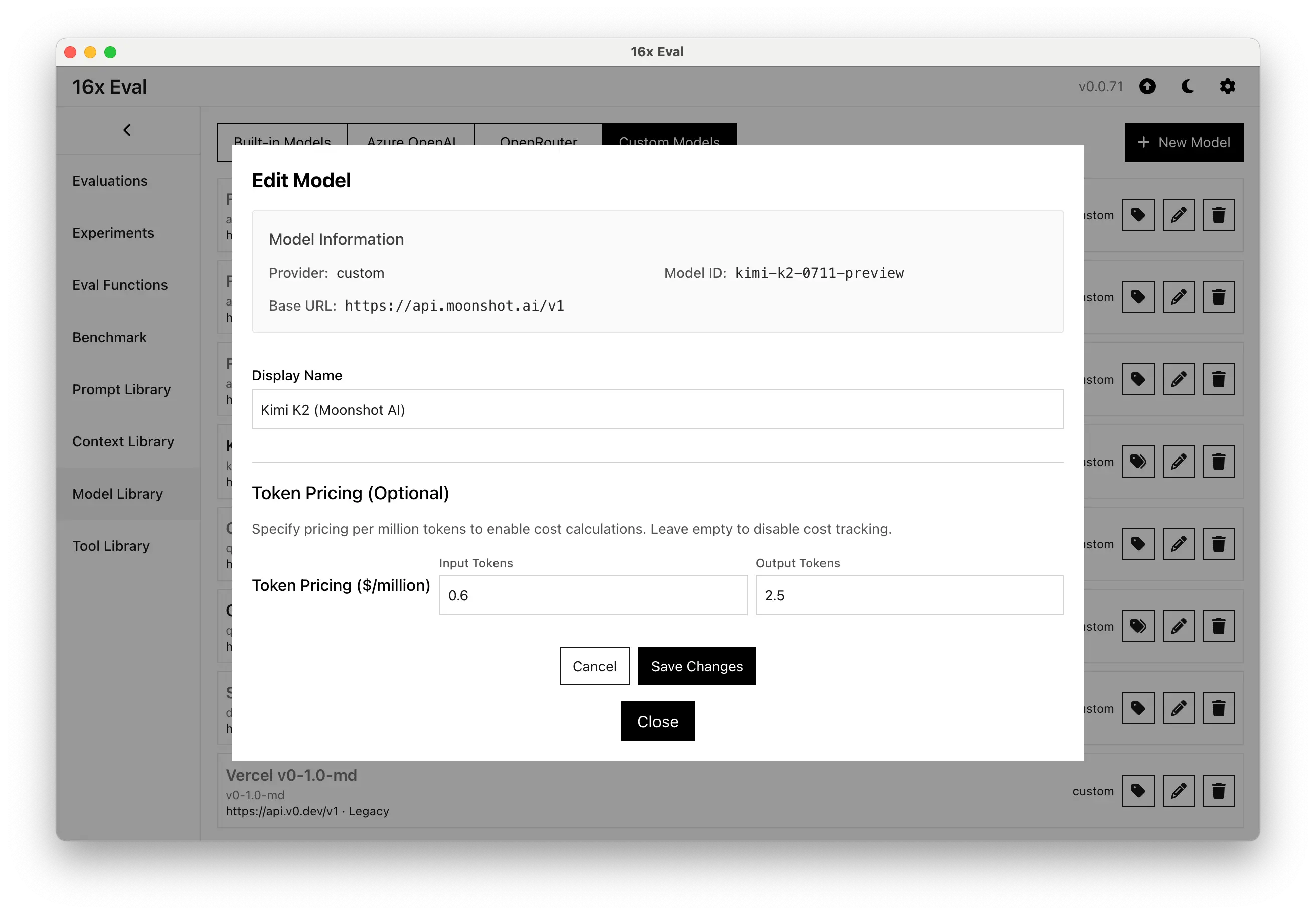
- Added support for custom model cost configuration to track costs for custom models and OpenRouter models.
- Added support for OpenRouter reasoning effort parameter for compatible models.
- Various bug fixes and UI/UX improvements.
0.0.70
September 5, 2025
- Improved reasoning effort display on evaluation page and benchmark page.
- Included reasoning effort when copying evaluation or benchmark as markdown.
0.0.69
September 4, 2025
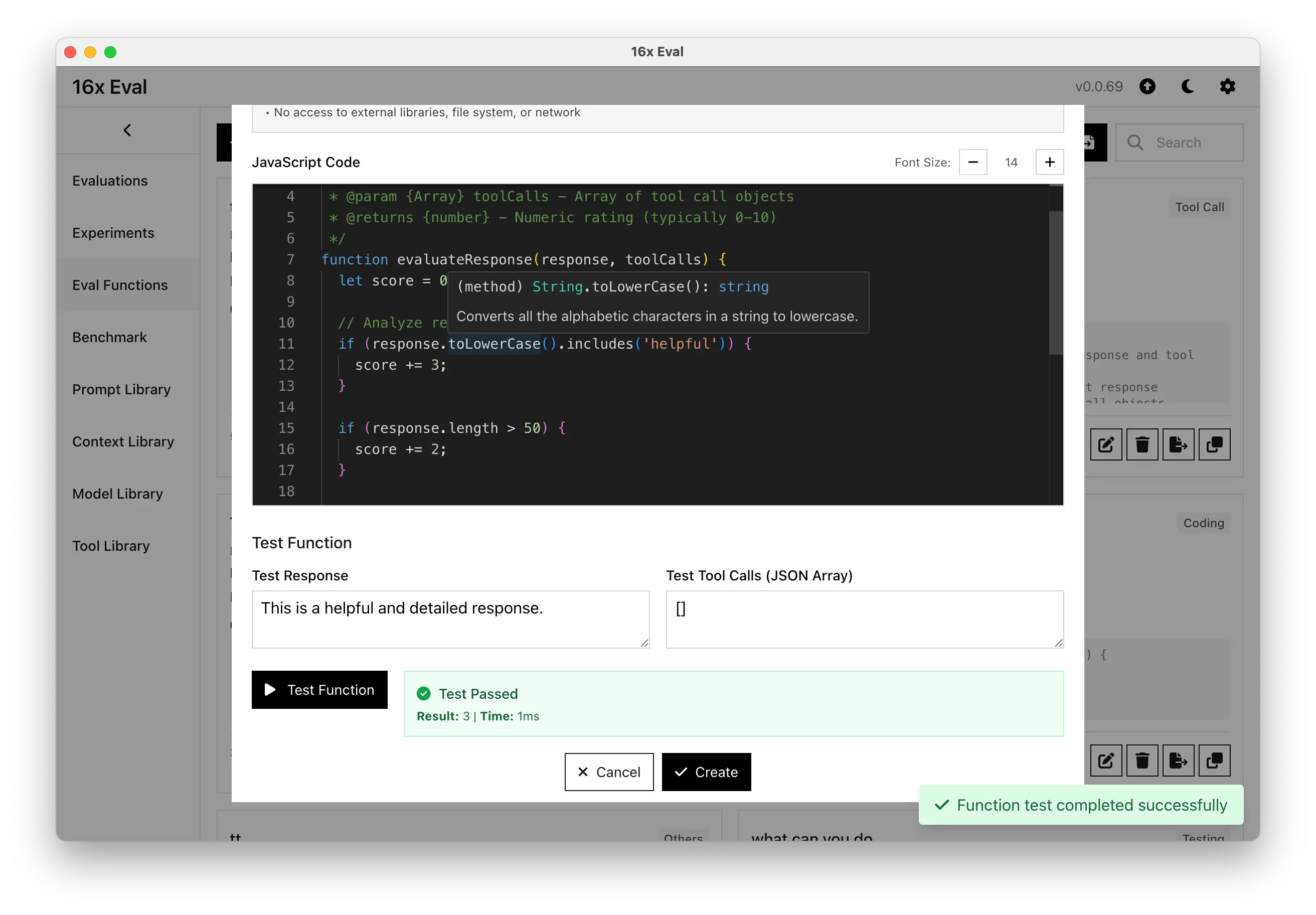
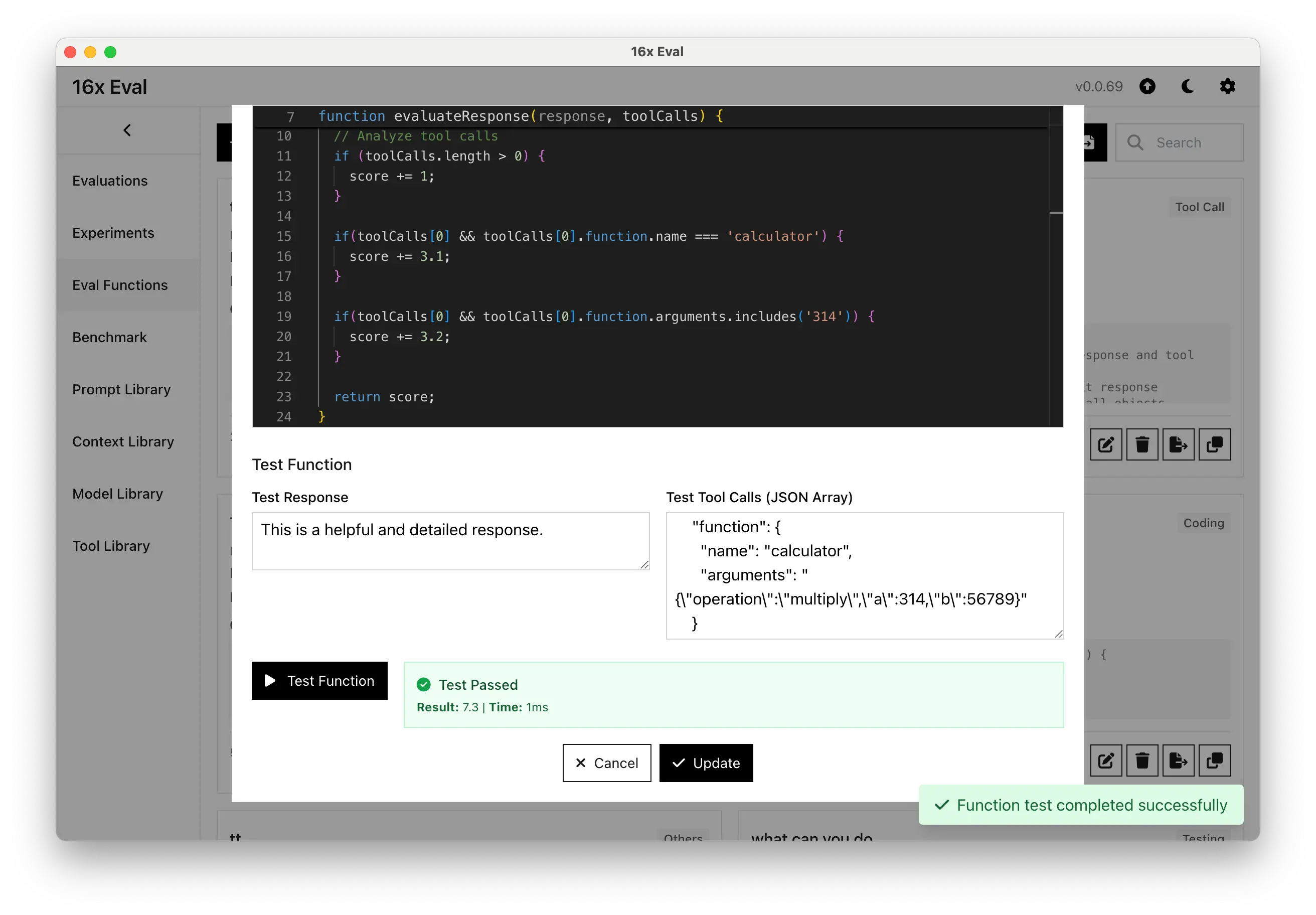
- Added support for user-defined JavaScript functions as evaluation functions.
- You can now create your own evaluation functions in JavaScript to evaluate model responses, including tool calls.
- Enhanced tool calls display to be more readable.
- Various bug fixes and UI/UX improvements
0.0.67
September 2, 2025
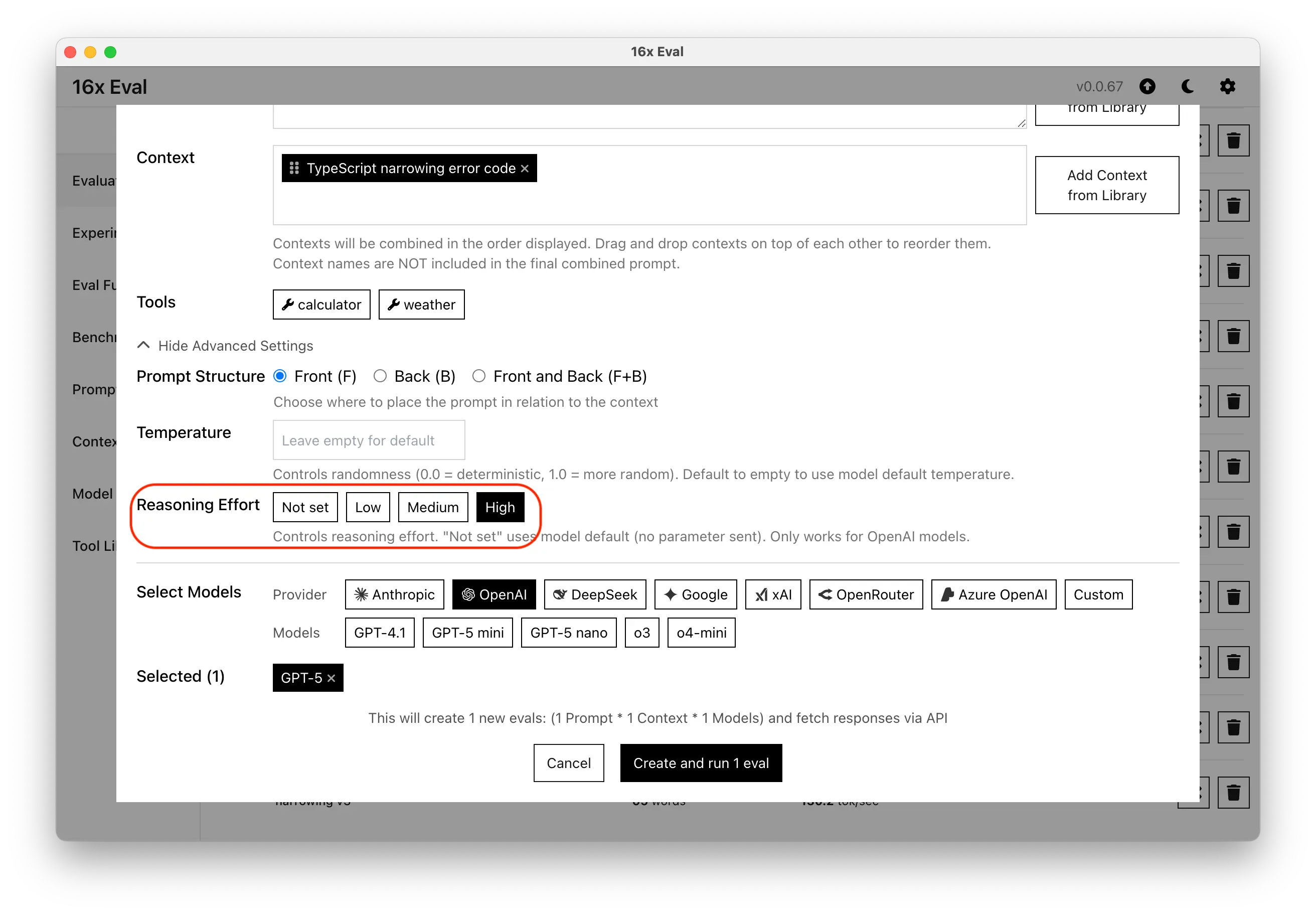
- Added support for OpenAI reasoning effort parameter to control reasoning depth for GPT-5 and o series models
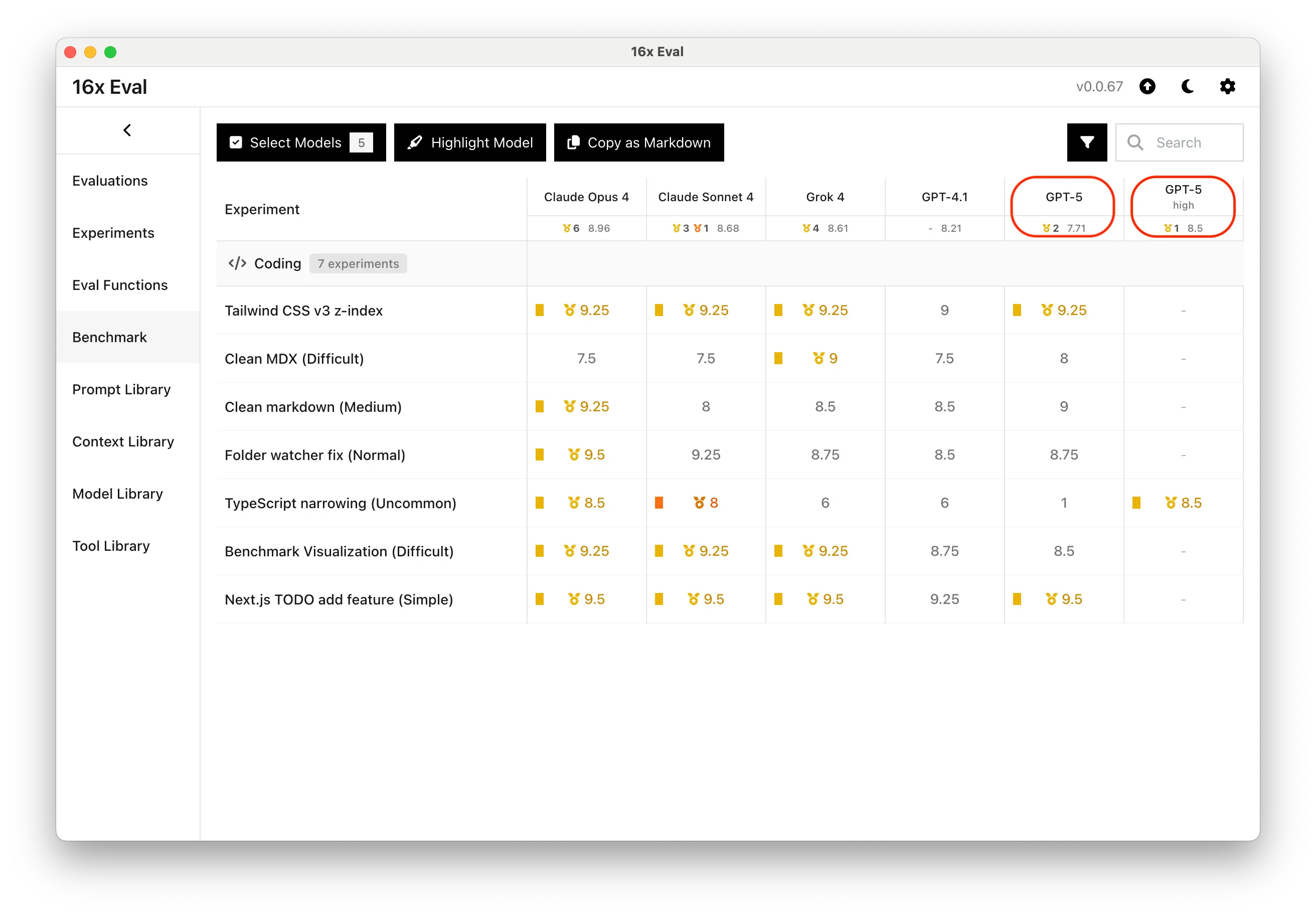
- Added reasoning effort column in evaluation tables
- Separated models with different reasoning effort on benchmark page for better comparison
- Various UI/UX improvements and bug fixes
0.0.66
August 28, 2025
- Additional bug fixes for DeepSeek-V3.1 model
0.0.65
August 27, 2025
- Fixed issues with DeepSeek-V3.1 model
0.0.64
August 27, 2025
- Added support for Grok Code Fast 1 model from xAI
0.0.63
August 21, 2025
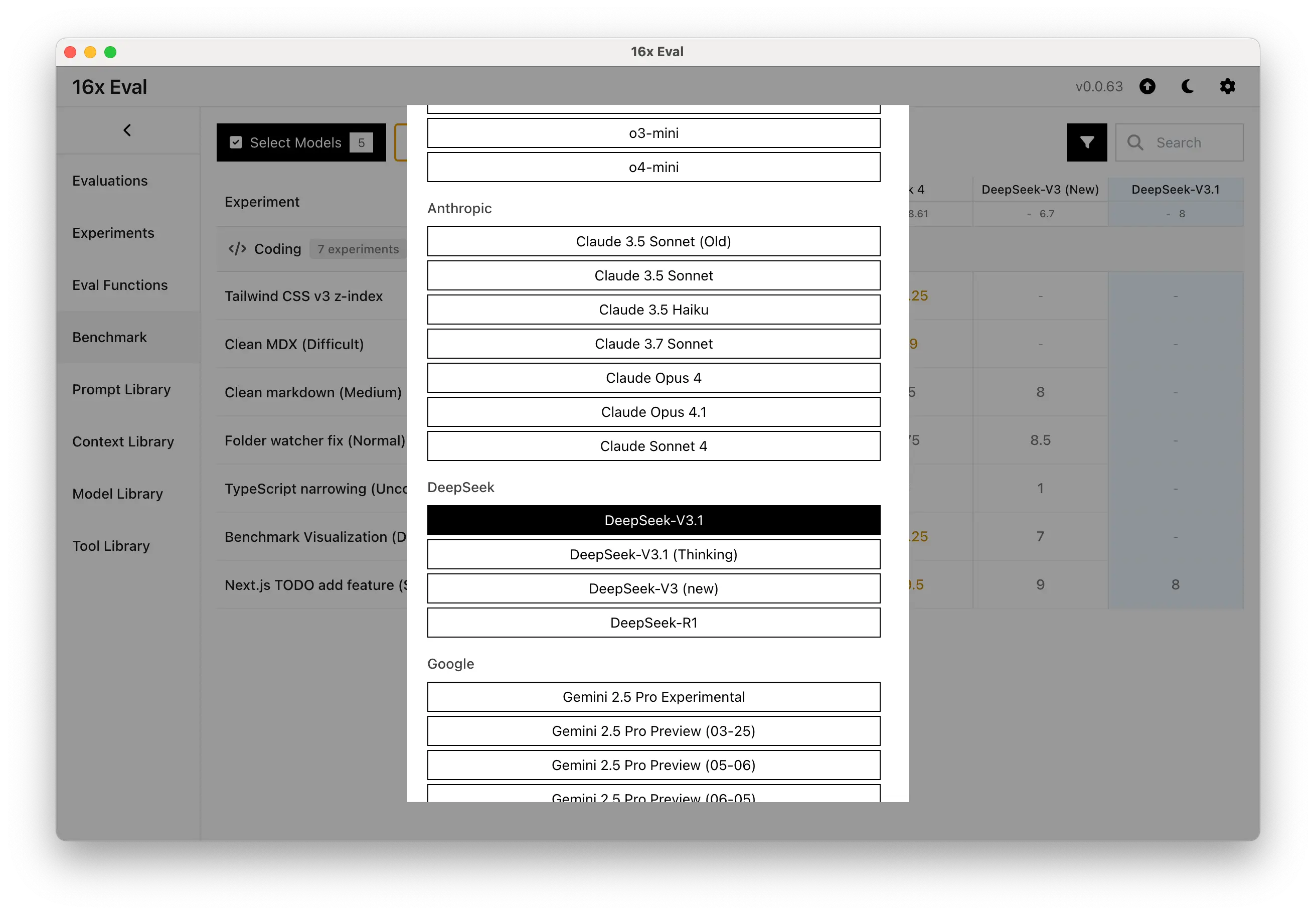
- Added support for DeepSeek-V3.1 and DeepSeek-V3.1 (Thinking Mode) models
- Added model release date tracking for cases where the underlying model was changed without changing the model id:
deepseek-chatmodel via DeepSeek API used to be DeepSeek-V3 (New), but it's now DeepSeek-V3.1deepseek-reasonermodel via DeepSeek API used to be DeepSeek-R1, but it's now DeepSeek-V3.1 (Thinking Mode)
- Old evaluations that were created with the old model name will continue to be displayed with the correct old model name
- Various bug fixes and UI/UX improvements
0.0.62
August 21, 2025
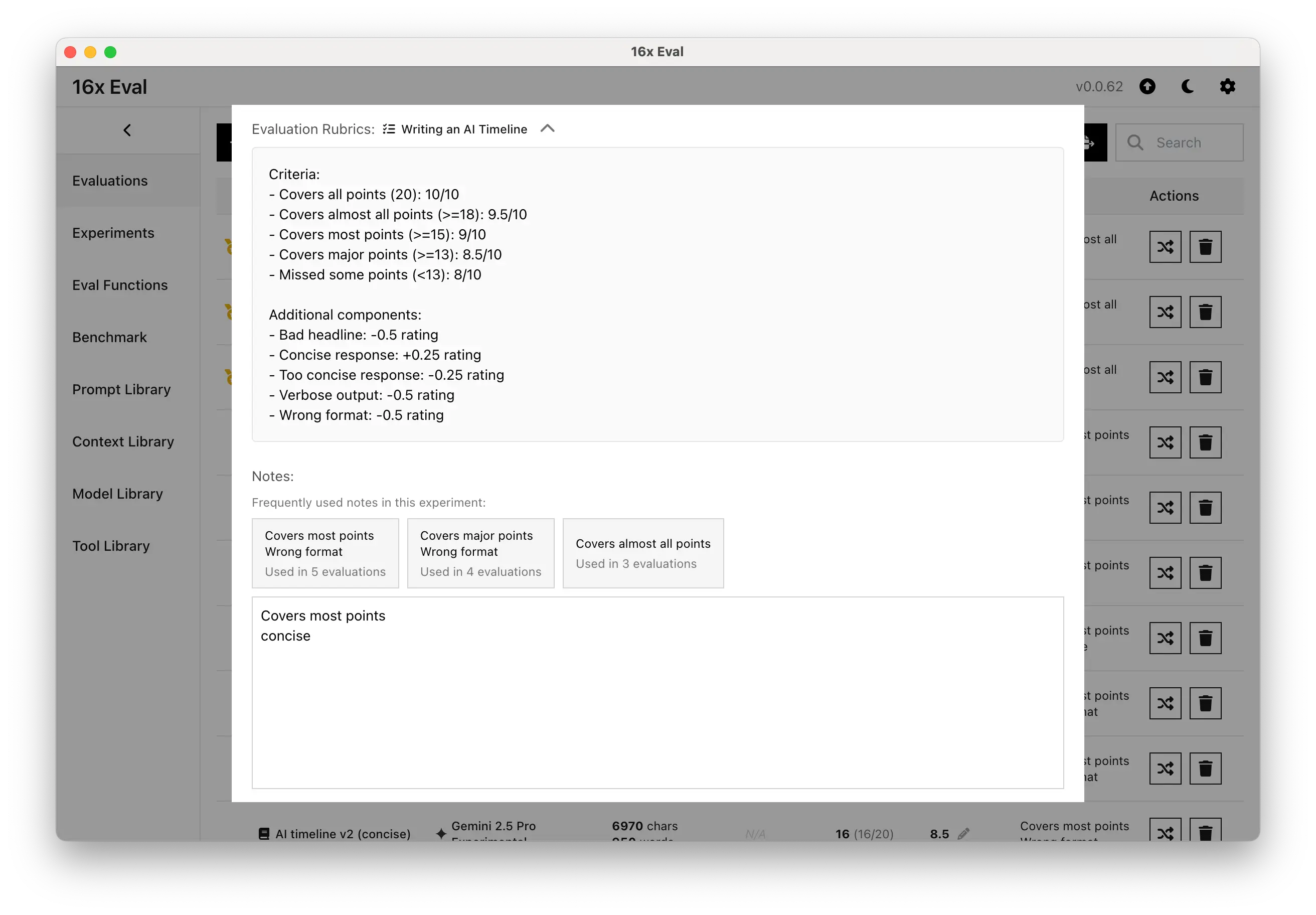
- Added suggested notes that shows most used notes from the experiment for faster evaluation
- Added ability to include rubrics when copying experiments
- Improved code block detection for better copying of code snippets
- Added model name in evaluations to handle cases where the underlying model was changed despite having the same model id (e.g.
deepseek-chat, etc.) - Updated sample evaluation and experiments data to include new features and fields
- Various bug fixes and UI/UX improvements
0.0.58
August 14, 2025
- Added ability to mark custom models and OpenRouter models as legacy for better organization
- Various bug fixes and UI/UX improvements
0.0.57
August 12, 2025
- Added highlight for top performance rows for each model in evaluation tables
- Added copy raw code button to copy code without markdown wrapping
- Added option to include file name when importing context files (default is on)
- Various bug fixes and UI/UX improvements
0.0.56
August 7, 2025
- Added support for GPT-5 models
- Added ability to set custom rating values for more flexible evaluation
- Added speed metrics to markdown export functionality
- Various bug fixes and UI/UX improvements
0.0.55
August 6, 2025
- Added ability to bulk export experiments
- Various bug fixes and UI/UX improvements
0.0.53
July 29, 2025
- Fixed OpenRouter model with provider options not working
0.0.52
July 29, 2025
- Added basic tool call support
- Added Tool Library page to manage and create tools for evaluation
- Added tools column and tool call column in evaluation table to display tool usage
- Added technical writing category
- Added copy benchmark as markdown functionality
- Various bug fixes and UI/UX improvements
0.0.51
July 23, 2025
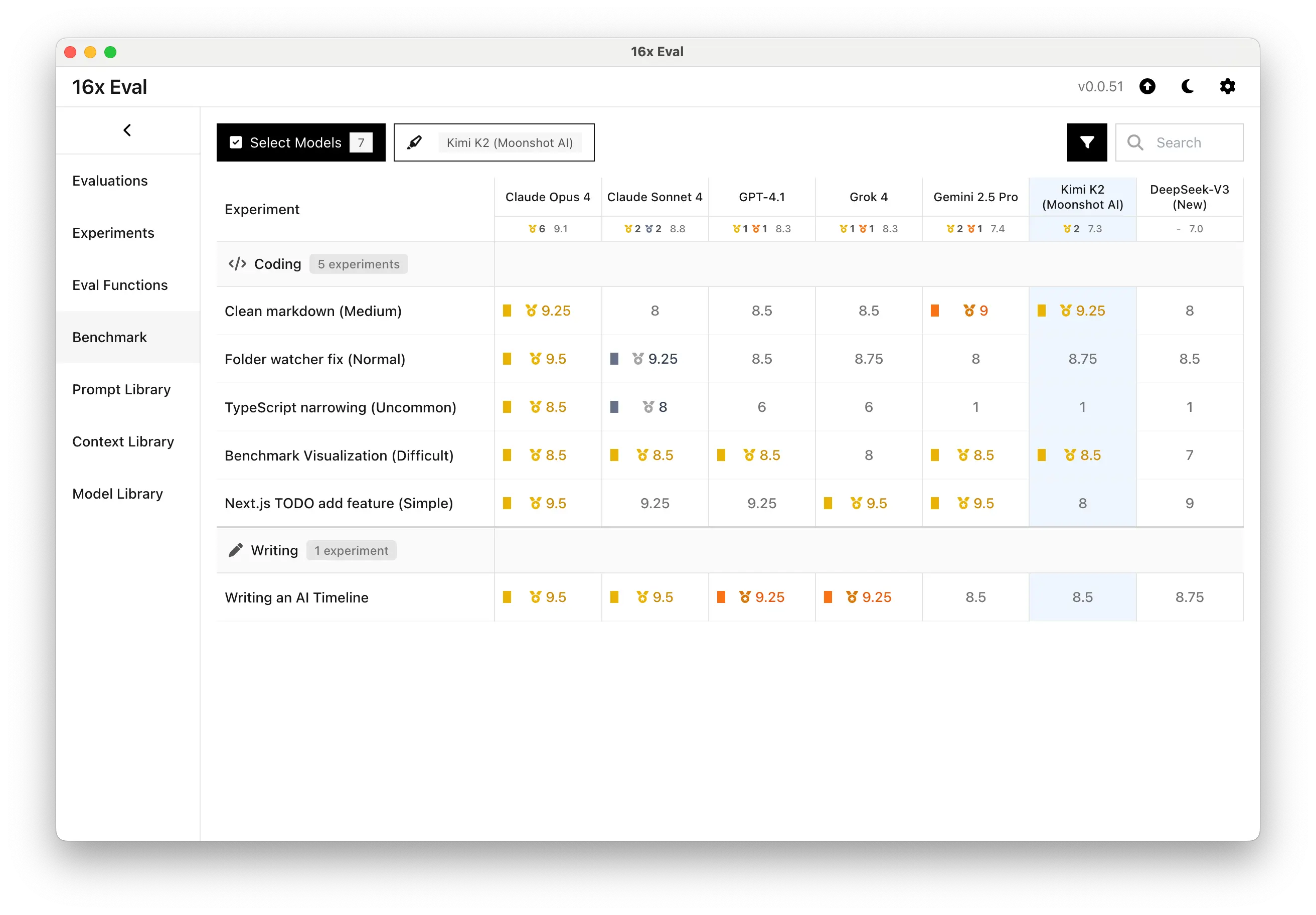
- Added average rating and ranking counts in benchmark page for better comparison
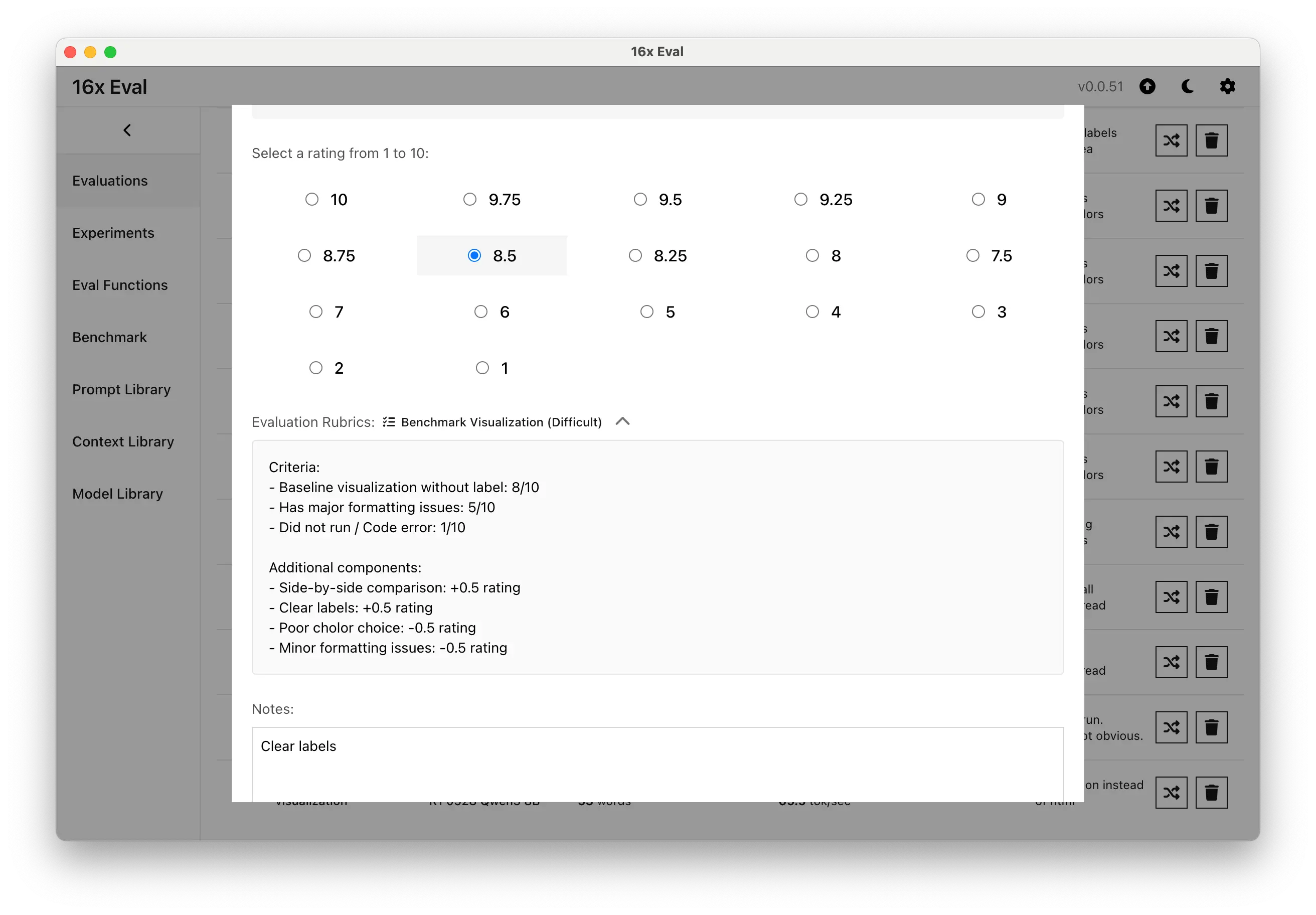
- Added rubrics support for experiments to provide more structured evaluation for human evaluators
- Added sort by prompt or response length functionality in eval table
- Added more granular rating options (6.5, 5.5, 9.75, 8.25) for better evaluation precision
- Various bug fixes and UI/UX improvements
0.0.50
July 21, 2025
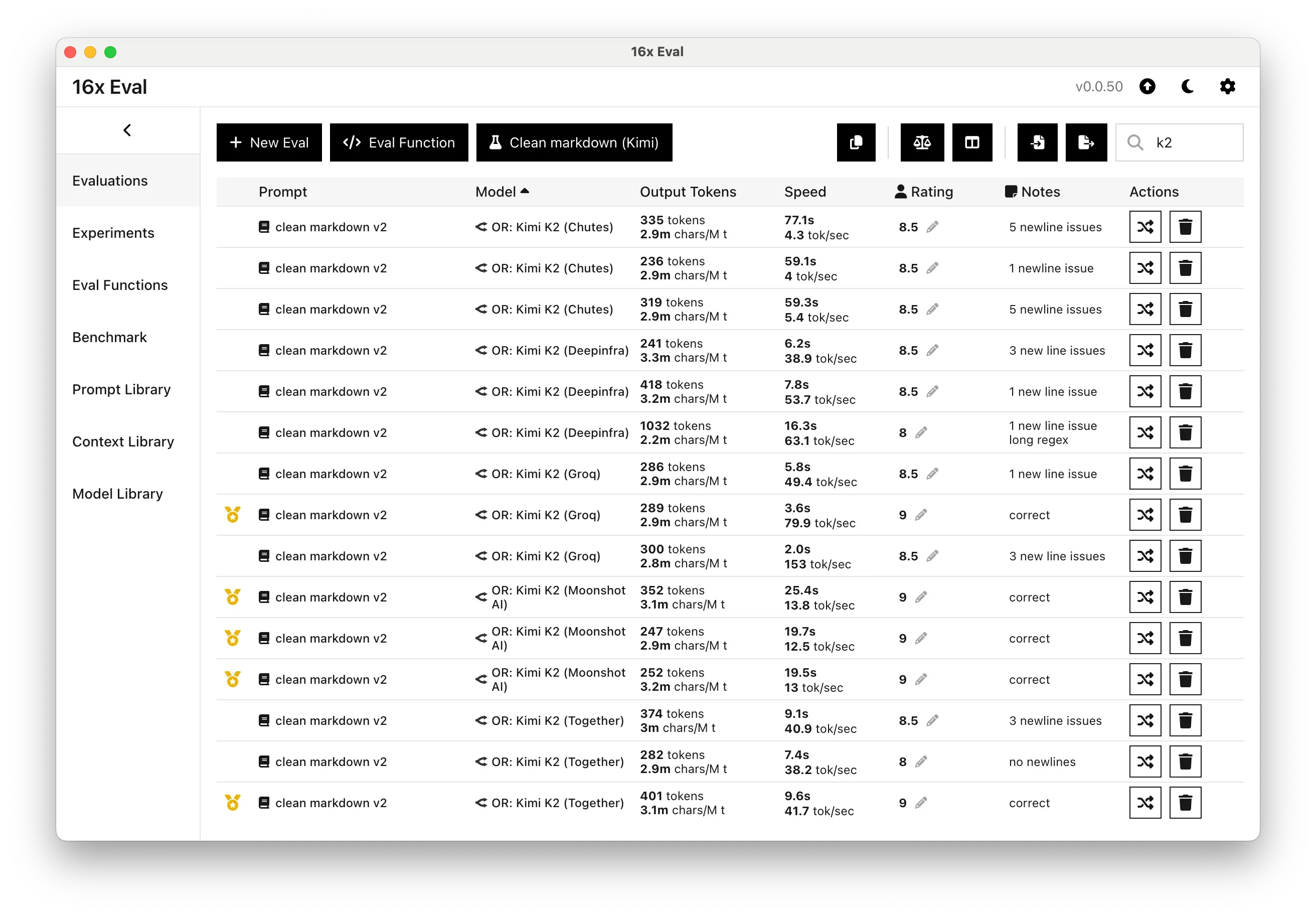
- Specific improvements for models like Kimi K2 where there are a lot of providers
- Added compact layout setting for more efficient use of screen space
- Added support for OpenRouter provider options to specify the exact provider for OpenRouter models
- Added ability to duplicate evaluations to new experiments
- Improved benchmark page with better layout and functionality
- Fixed context rendering to properly handle whitespace
- Various UI/UX improvements
0.0.49
July 16, 2025
- Added links to provider api key page in settings page
- UI/UX improvements to experiment page to allow more customization

0.0.48
July 15, 2025
- Added support for xAI as first-party model provider
- Added first-party support for Grok 4 model
- Changed the default model to Claude Sonnet 4
- Fixed thoughts / reasoning token counting logic for OpenRouter provider
- Various UI/UX improvements

0.0.47
June 20, 2025
- Added pricing metrics for models in the evals page
- Added cost metrics for individual evaluations in the evals page

0.0.46
June 17, 2025
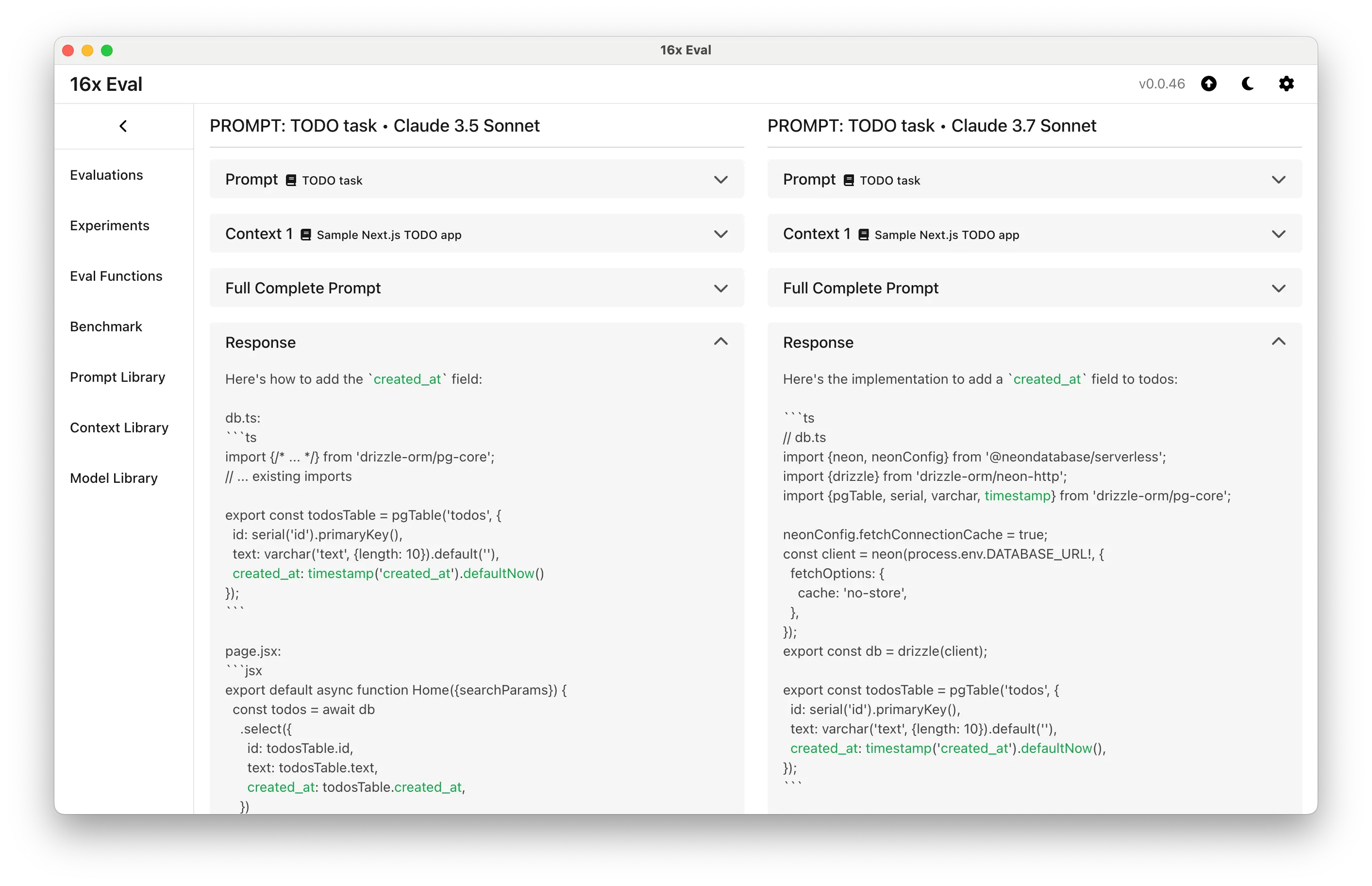
- Added evaluation comparison page to compare the results of two evaluations side by side
0.0.45
June 8, 2025
- Added support for Gemini 2.5 Pro Preview (06-05)
- Optimized the UX for adding OpenRouter models for new users
0.0.44
June 1, 2025
- Moved benchmark to a separate dedicated page with option to select models
- Added sorting options for experiments page
- Added temperature as an advanced setting
- Merged rating and notes modal for better UX
- Various UI/UX improvements

0.0.43
May 26, 2025
- Added a new table view for experiments with improved layout and 3-column display on large screens
- Added experiment linking with evaluation functions to automatically enable the linked evaluation functions
- Added writing statistics color-coded ranges for words per sentence and words per paragraph
- Added response token count display in statistics
- Added line wrapping option for better text readability
- Added copy as markdown feature
- Various UI/UX and performance improvements
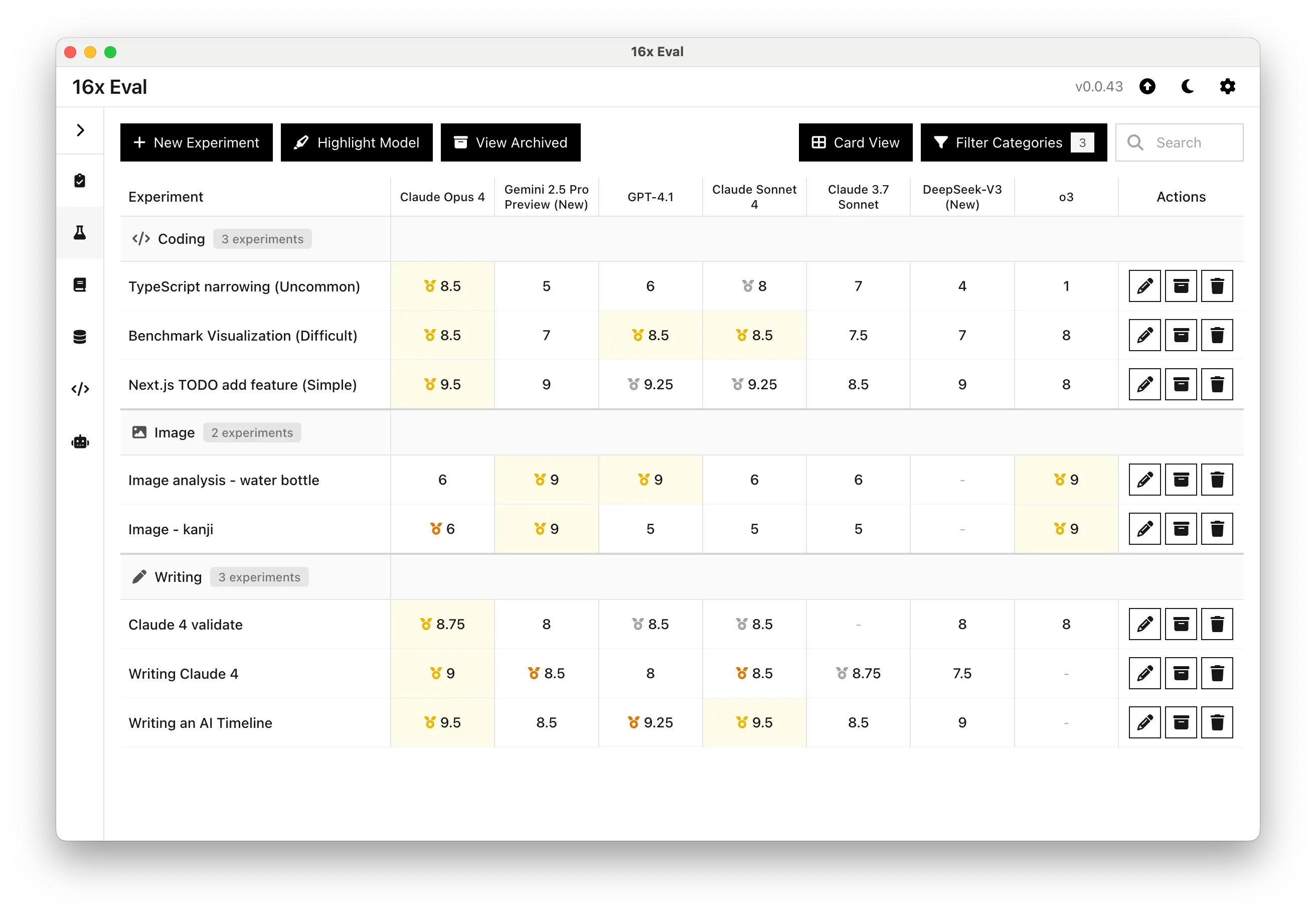
0.0.42
May 23, 2025
- Added support for Claude Sonnet 4 and Claude Opus 4 models
In our sample evaluation for coding and writing tasks, Claude Opus 4 absolutely dominated other models in both coding and writing tasks. It is the best performing model for all 4 tasks given.
Claude Sonnet 4 is also very impressive, coming in top 1 or top 2 in all tasks, beating almost all other models.
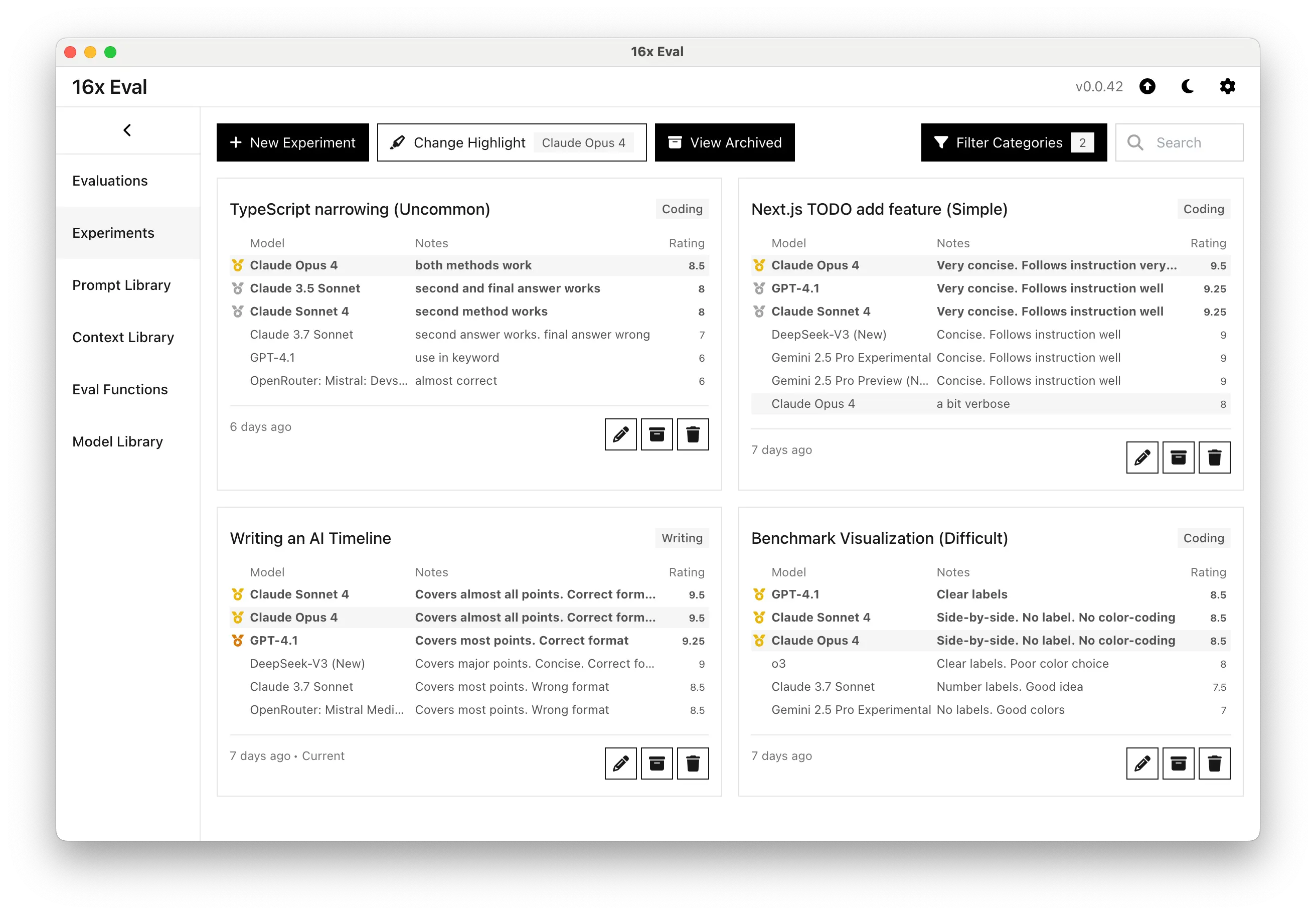
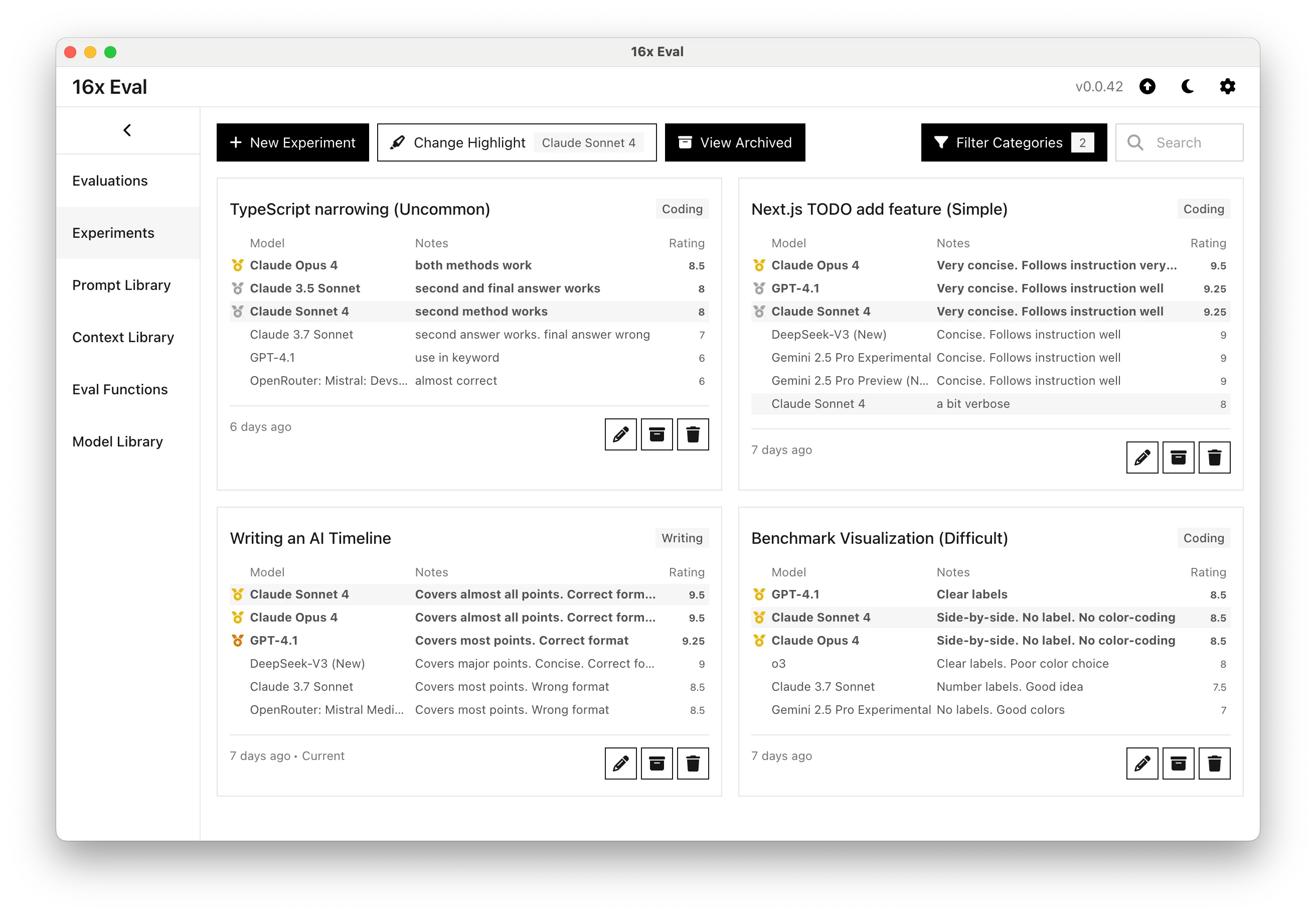
0.0.41
May 22, 2025
- Added archive functionality for experiments, prompts, and contexts to avoid cluttering the list
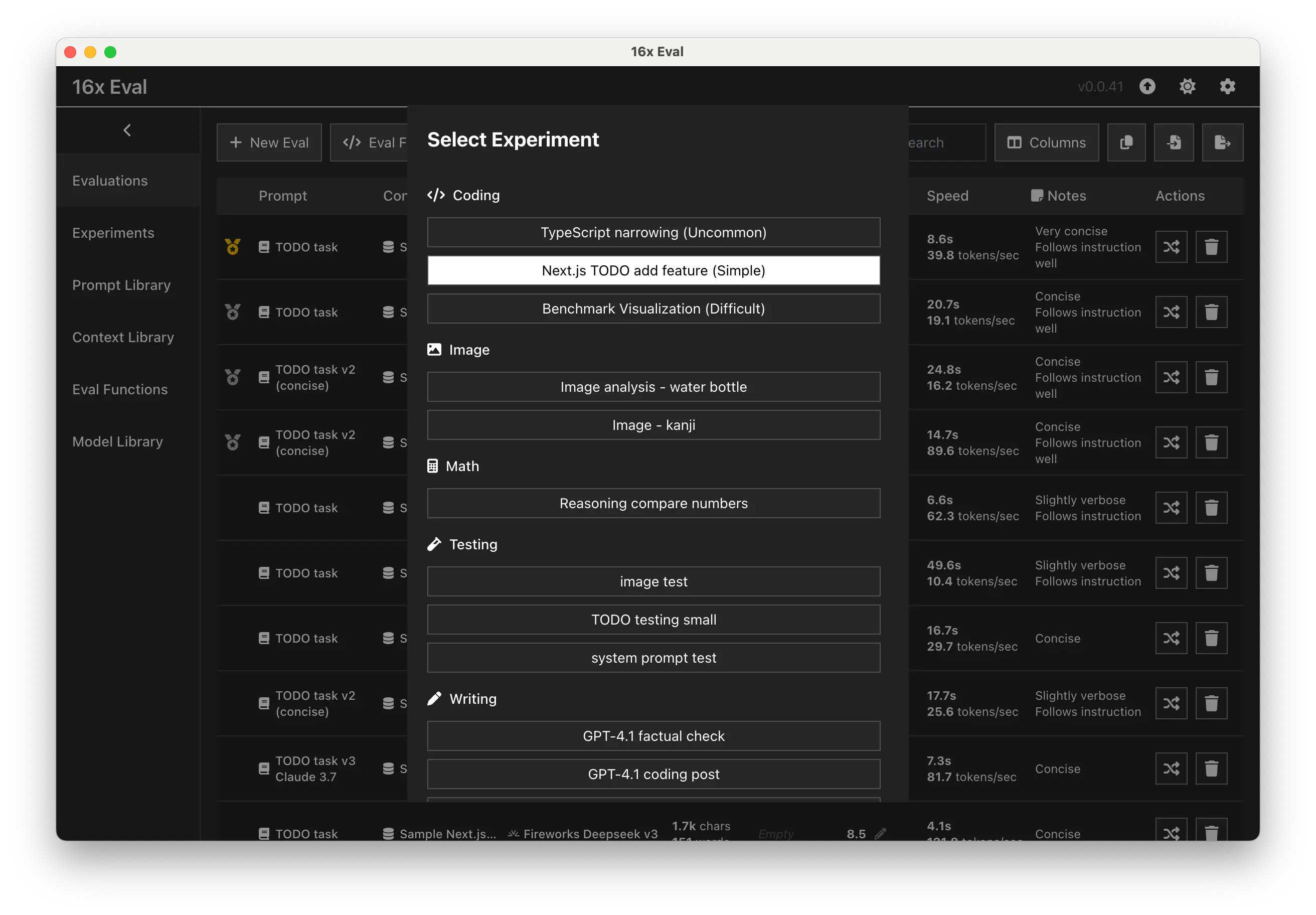
- Added category grouping for evaluation functions and experiments in selection modal
- Added category icons and ensured category filter persist across pages
- Improved image context handling and storage
- Fixed dark mode colors
- Various UI/UX improvements

0.0.39
May 21, 2025
- Added reasoning token count from OpenRouter provider
0.0.38
May 20, 2025
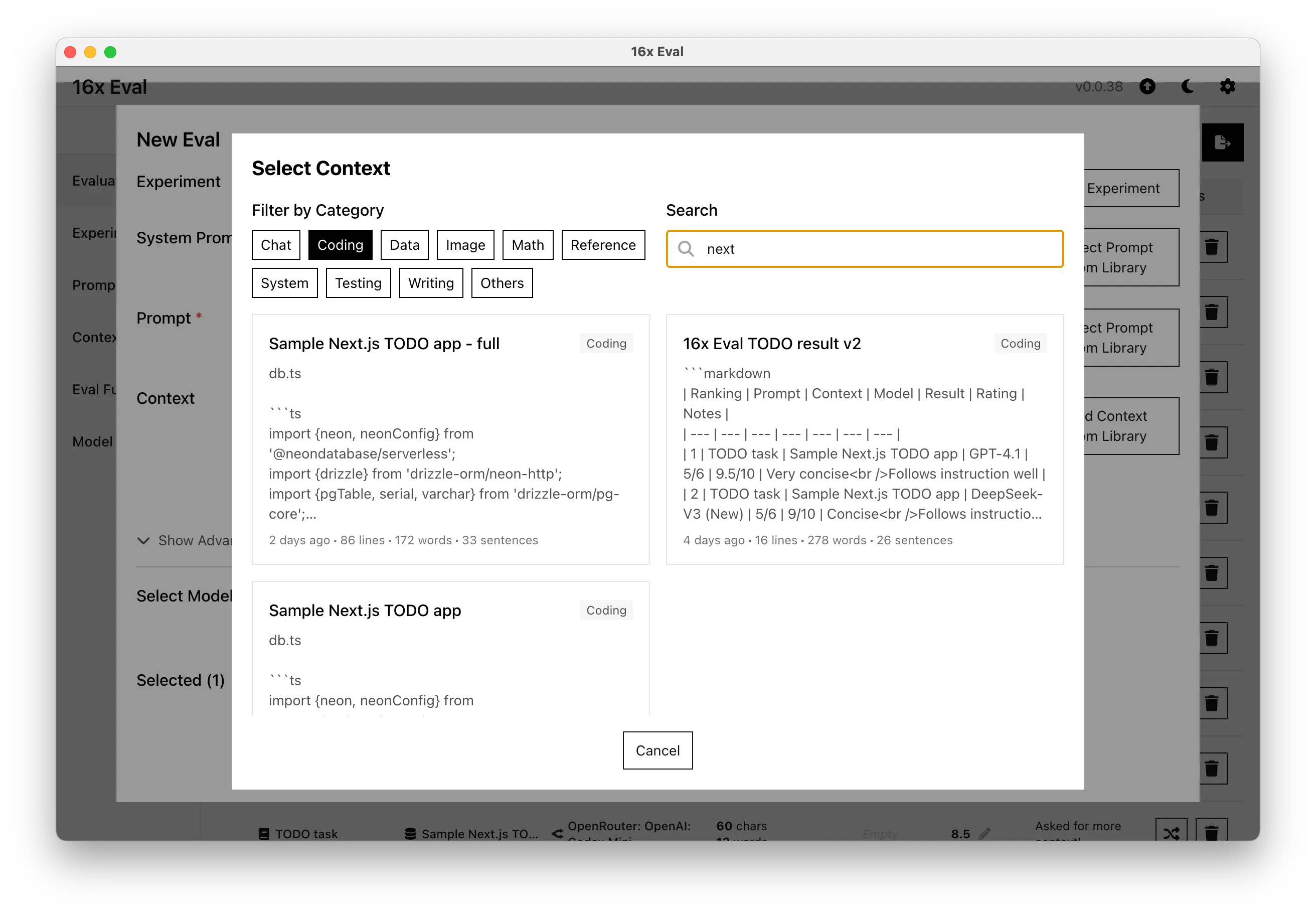
- Added search functionality across the app (experiments, prompts, contexts)
- Added green and red highlights for target and penalty strings from evaluation functions in model responses
- Added drag and drop support for re-ordering contexts
- Added created at timestamps for evaluation functions and experiments
- Added new options (8.75 and 9.25) for more granular rating
- Replaced 3rd-party LLM library with our own send-prompt library to support more features and improve stability
- Various UI/UX improvements and bug fixes
0.0.37
May 15, 2025
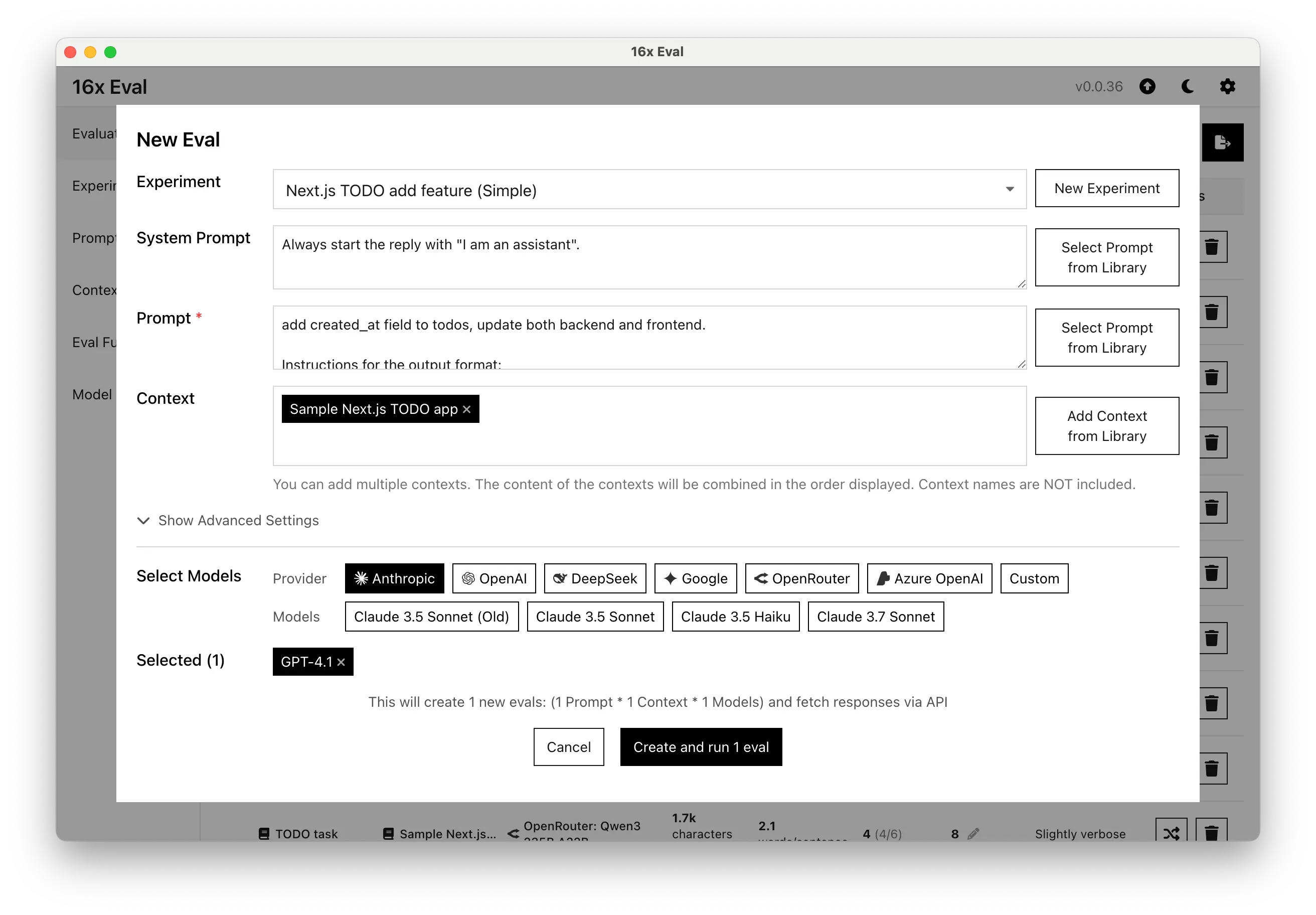
- Added support for system prompts
- Added advanced settings for more configuration options
- Added categories for prompts and contexts
- Various UI/UX improvements
0.0.35
May 9, 2025
- Added ability to duplicate and export single evaluation function
- Added support for penalizing occurrences of strings in evaluation functions
- Added ability to copy evaluation as markdown
- Added sorting by speed
- Various UI/UX improvements and bug fixes
0.0.32
May 8, 2025
- Various UI/UX improvements and bug fixes
0.0.31
May 7, 2025
- Added notes feature for evaluations with improved UX
- Added ability to cancel running evaluations
- Added provider logos and icons for models
- Added sorting by creation time
- Improved UI/UX for various pages
- Various code refactoring for better maintainability
0.0.30
May 1, 2025
- Added performance metrics including speed, writing statistics, and reasoning response
- Added ability to sort evaluations by rating or model name
- Added model highlighting feature in experiments page
- Increased timeout limit to 10 minutes
- Improved experiment page UI/UX
- Fixed image import and export functionality
0.0.29
April 28, 2025
- Added support for Azure OpenAI models
- Added experiment categories to help organize experiments
- Added auto-fill for custom model API settings (Fireworks for now)
- Fixed bugs with sending prompts to custom models (You need to delete the existing custom models and create a new ones)
- Fixed temperature setting bug for OpenAI reasoning models
- Various UI/UX improvements
0.0.28
April 26, 2025
- Added support for creation time and token stats columns in the evaluation page
- Improve export and import of evaluations containing images
- Major code refactoring to support more features
0.0.26
April 26, 2025
- Bug fixes related to app update (surprisingly, it's very tricky to get right)
0.0.24
April 25, 2025
- Added support image context. You can now send images as context to the models that support it.
- Added ability to import evaluations from a JSON file that was exported previously
- Added a link to release notes in the settings page
- Improve the UI/UX of app update
- Fixed various bugs
0.0.19
April 23, 2025
- Fixed a bug where API keys cannot be pasted into the API key input field
- Fixed a bug where importing multiple files from the file system would fail
- Added built-in exclusion filter for large files (>1MB) and binary files
- Image file support is coming soon
0.0.16
April 23, 2025
- Added dedicated page for managing evaluation functions
- Added ability to check for updates and install updates on Settings page
- UI/UX improvements
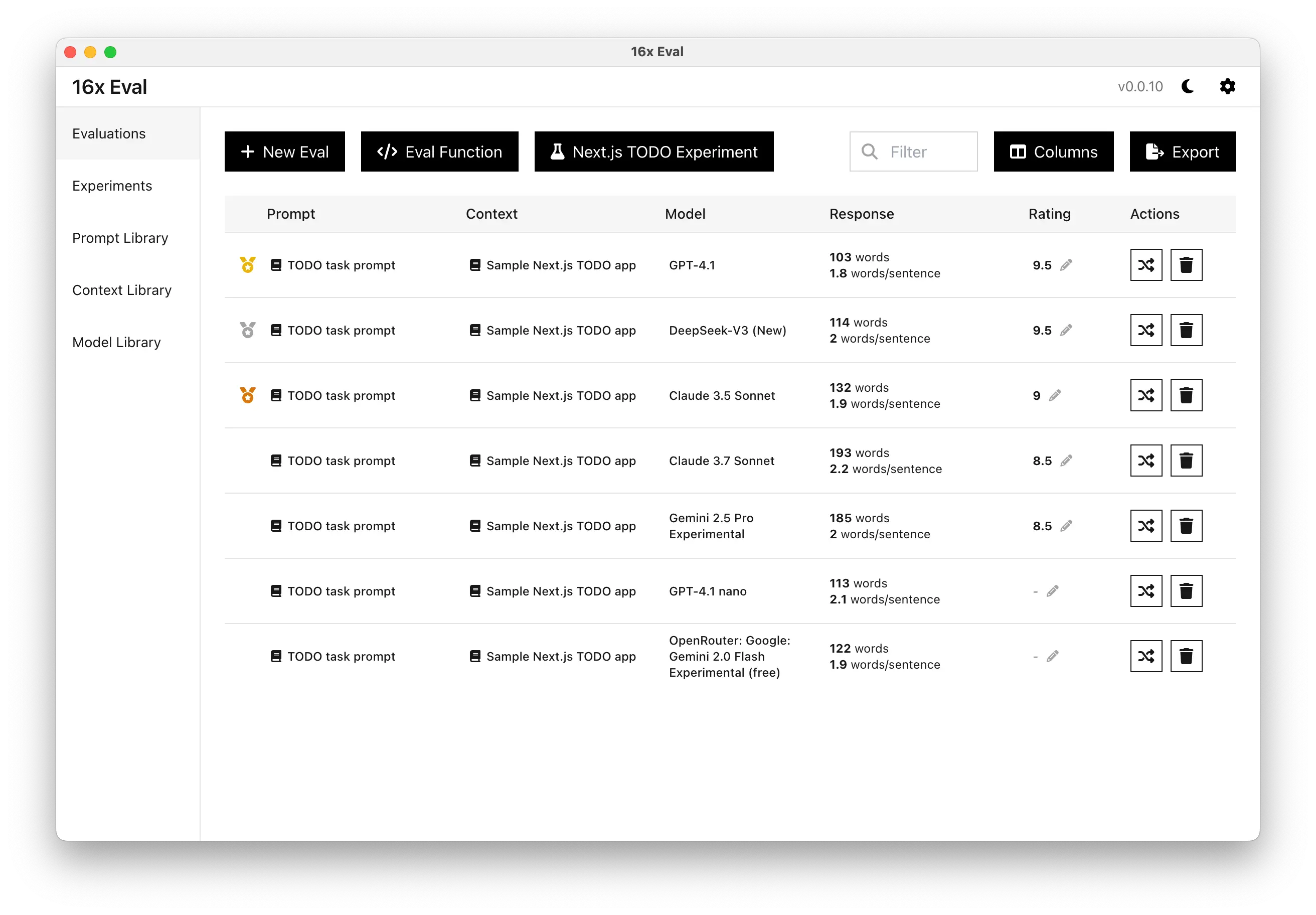
0.0.10
April 21, 2025
- Customizable columns for evaluation page
0.0.9
April 20, 2025
- Run evaluation on multiple models
- Organize evaluations into experiments
- Prompt library and context library
- Built-in models and custom models