16x Eval Blog
Read the latest blog posts from 16x Eval.

Beyond Leaderboards: Why You Need Personalized AI Evaluation
Generic AI benchmarks and leaderboards often fail to predict real-world performance. Learn why personalized evaluation is key to finding the right model and prompt for your specific tasks.
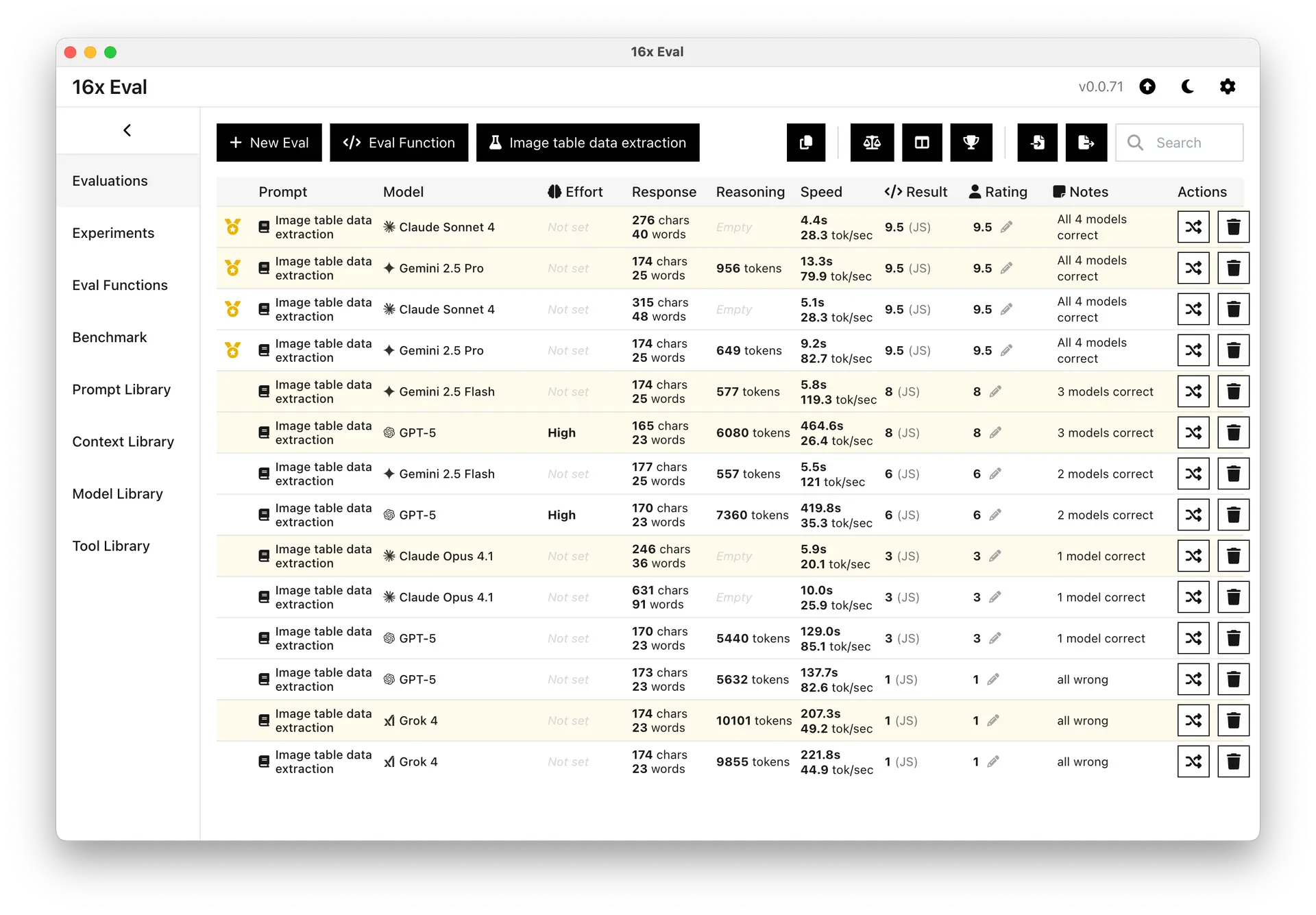
Gemini 2.5 Pro and Claude Sonnet 4 Excel at Image Table Data Extraction
We evaluated leading vision models on a new image table data extraction task. Gemini 2.5 Pro and Claude Sonnet 4 did the best. GPT-5 (High) and Gemini 2.5 Flash was decent. Others struggled.
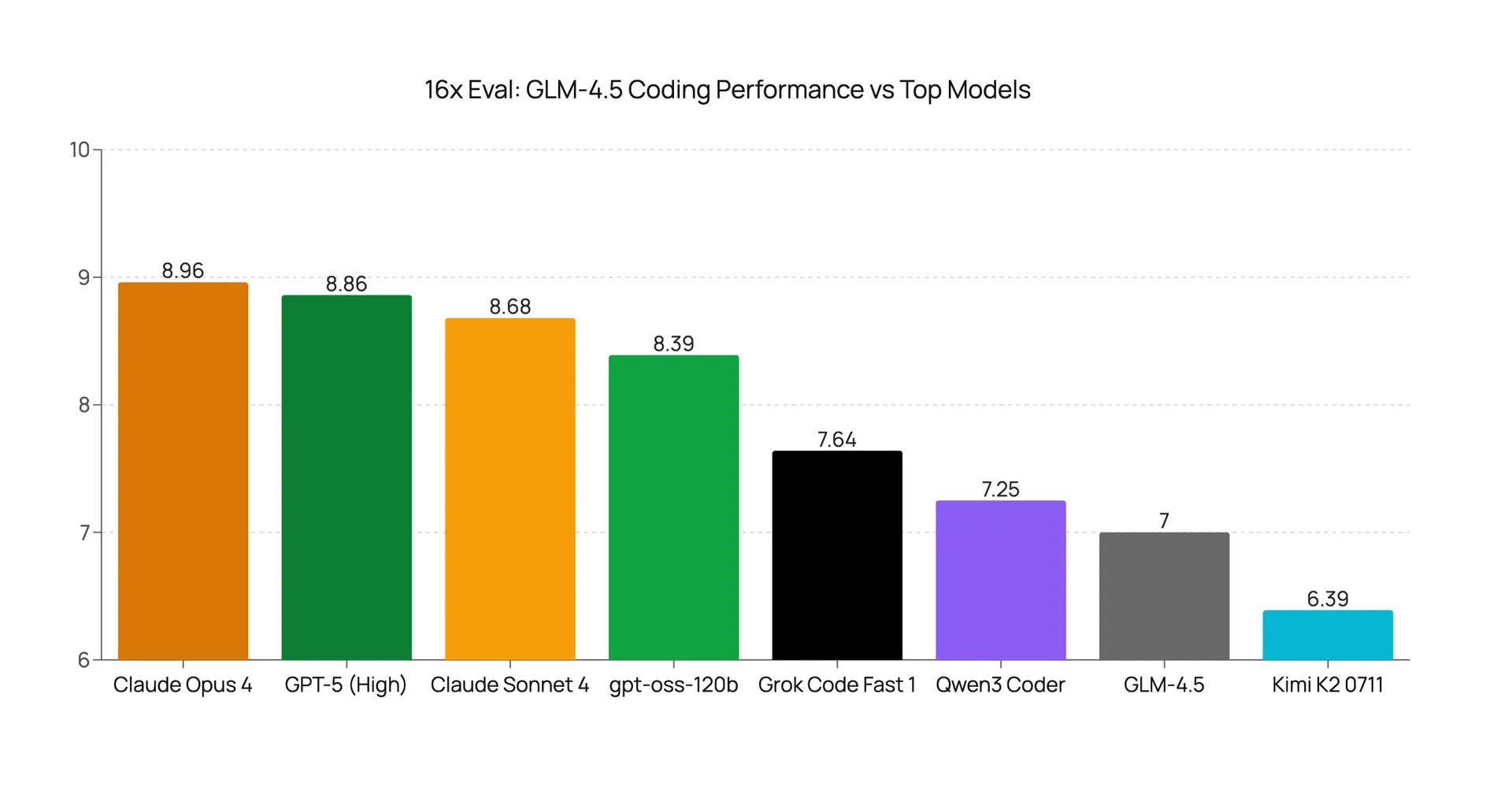
GLM-4.5 Coding Evaluation: Budget-Friendly with Thinking Trade-Off
We evaluated Z.ai's new GLM-4.5 model on several coding tasks. Our tests show it has specific strengths but also significant weaknesses, and its thinking process comes with trade-offs.
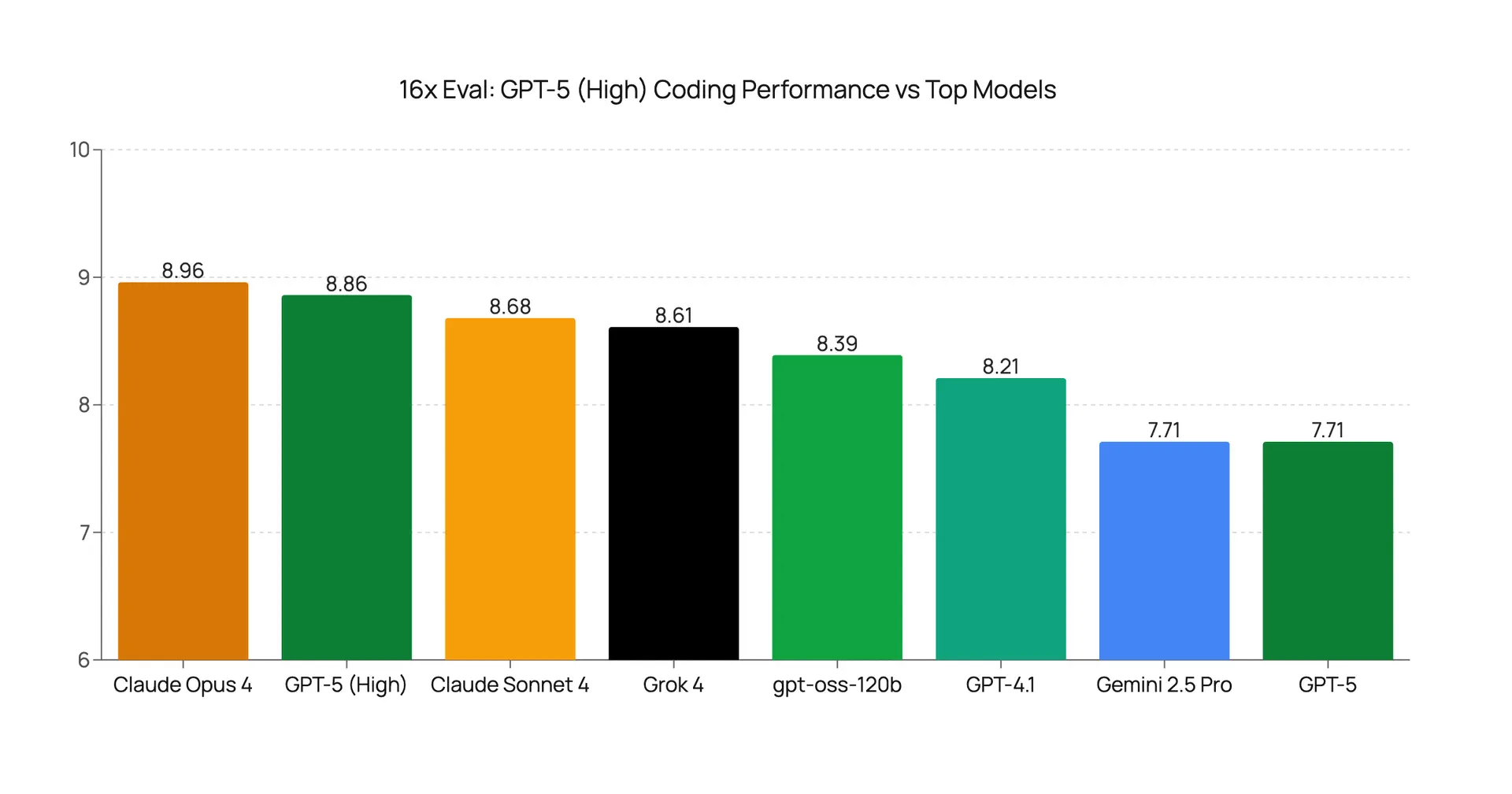
GPT-5 High Reasoning Evaluation: A Major Leap in Coding Performance
We re-evaluate GPT-5 using high reasoning effort on coding tasks. The results show a significant performance boost over the medium setting, placing it among the top models like Claude Opus 4.
Claude, Claude API, and Claude Code: What's the Difference?
Learn the key differences between the Claude web app, the Claude API, and the Claude Code coding assistant, especially when used in 3rd party tools like Cline, Repo Prompt, and Zed.
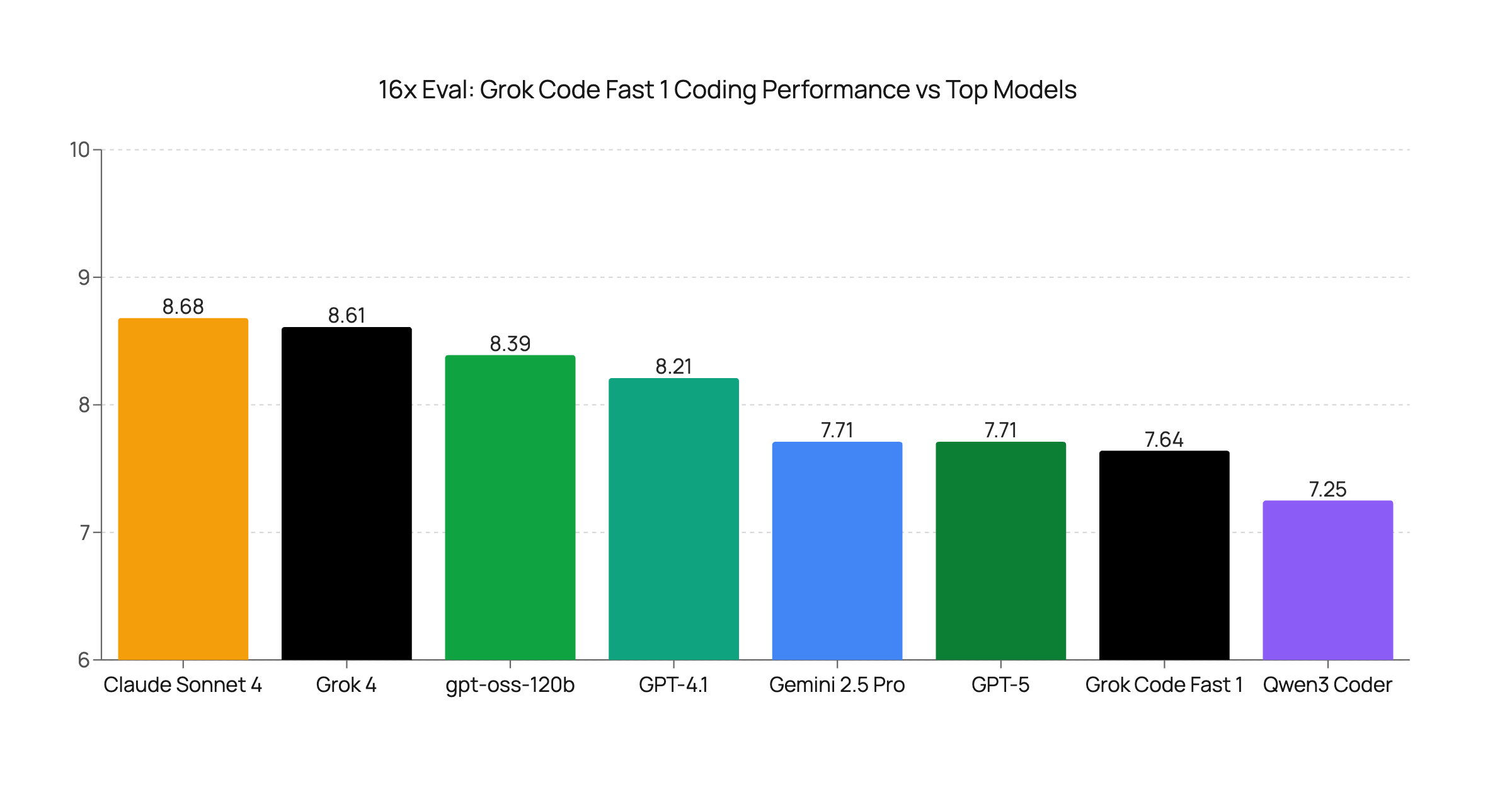
Grok Code Fast 1 Coding Evaluation: Strong Performance with Some Quirks
We evaluated xAI's Grok Code Fast 1 on seven coding tasks. The model shows strong performance on many tasks but struggles with Tailwind CSS task, placing it as a cost-effective coding model.
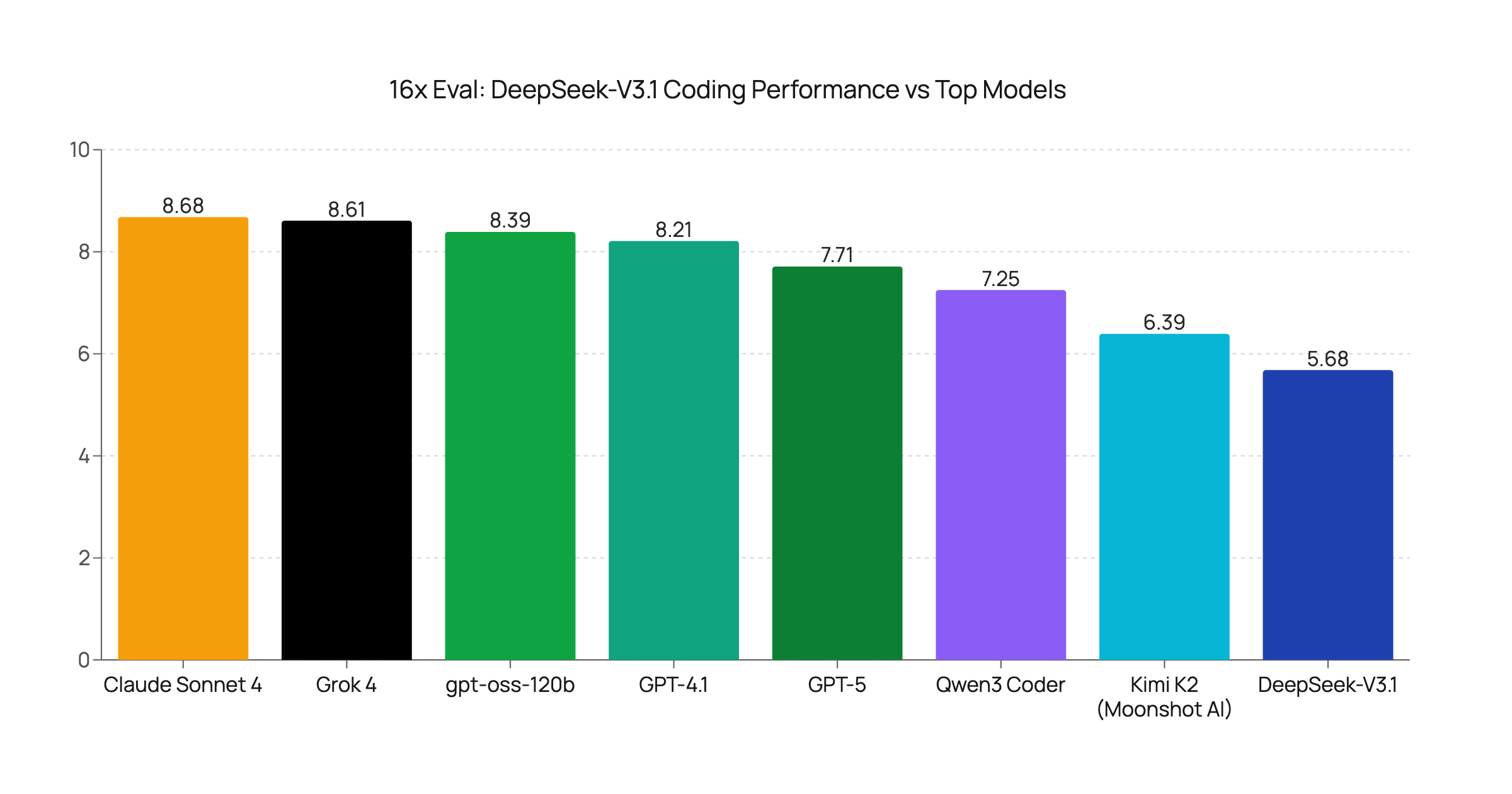
DeepSeek-V3.1 Coding Performance Evaluation: A Step Back?
We evaluated the new DeepSeek-V3.1 model on a range of coding tasks. Our results show a surprising regression in performance compared to its predecessor and other leading models.
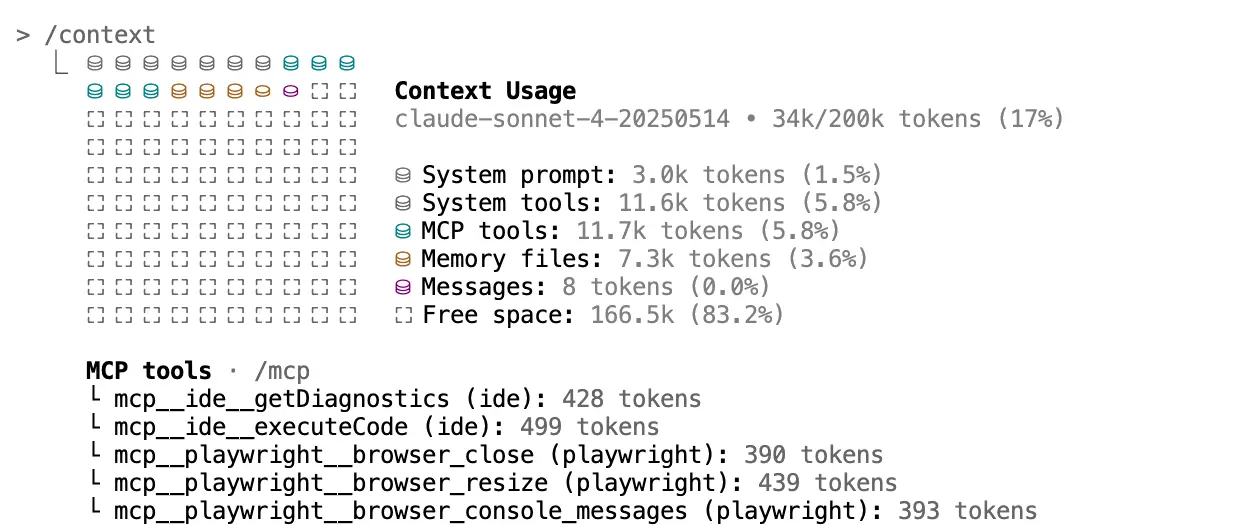
LLM Context Management: How to Improve Performance and Lower Costs
Large context windows in LLMs are useful, but filling them carelessly can degrade performance and increase costs. Learn why context bloat happens and how to manage it effectively.
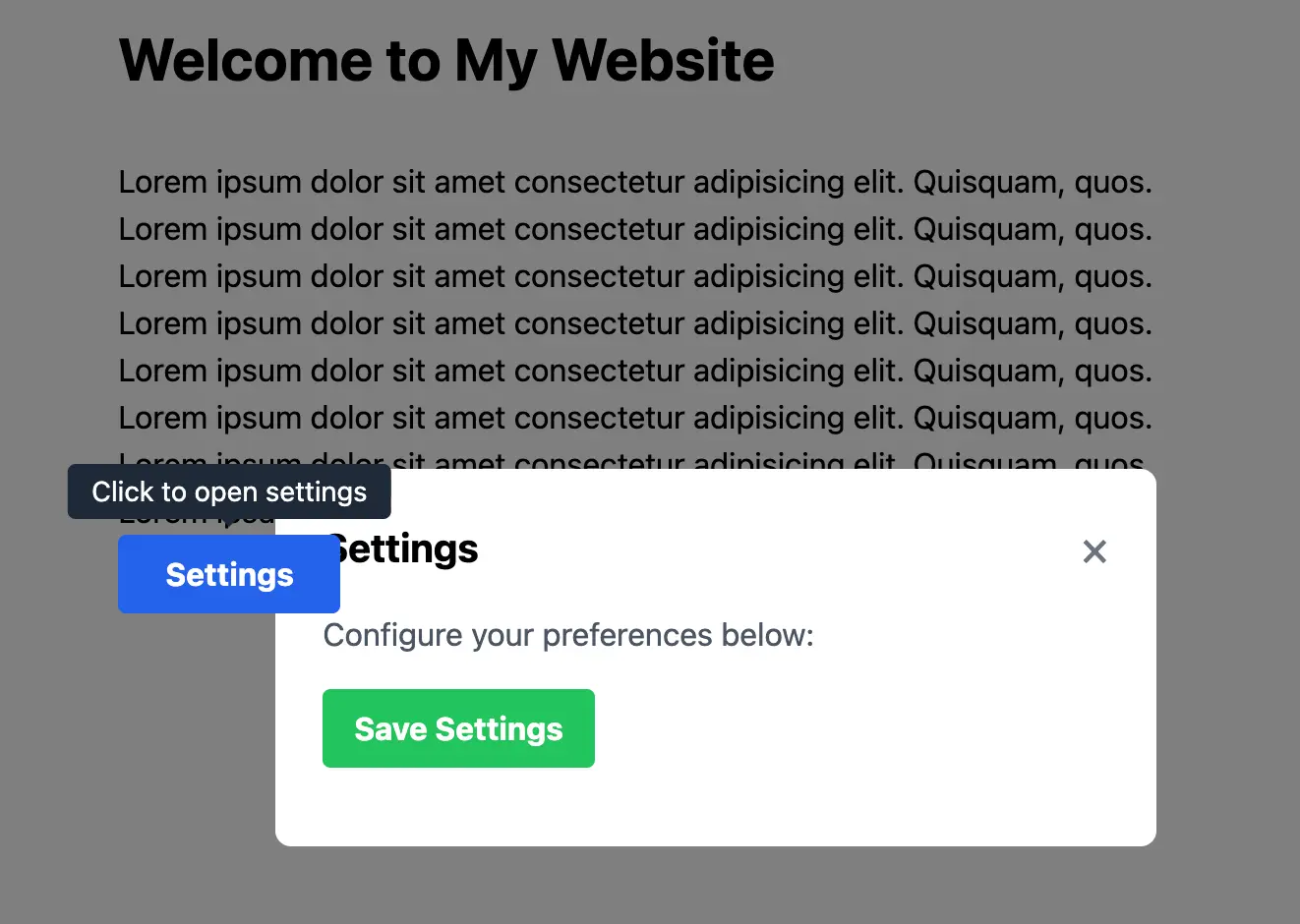
New Coding Task: Subtle Z-Index Bug in Tailwind CSS v3
New Tailwind CSS v3 z-index task tests AI models' ability to find version-specific bugs, a key challenge in real-world development.
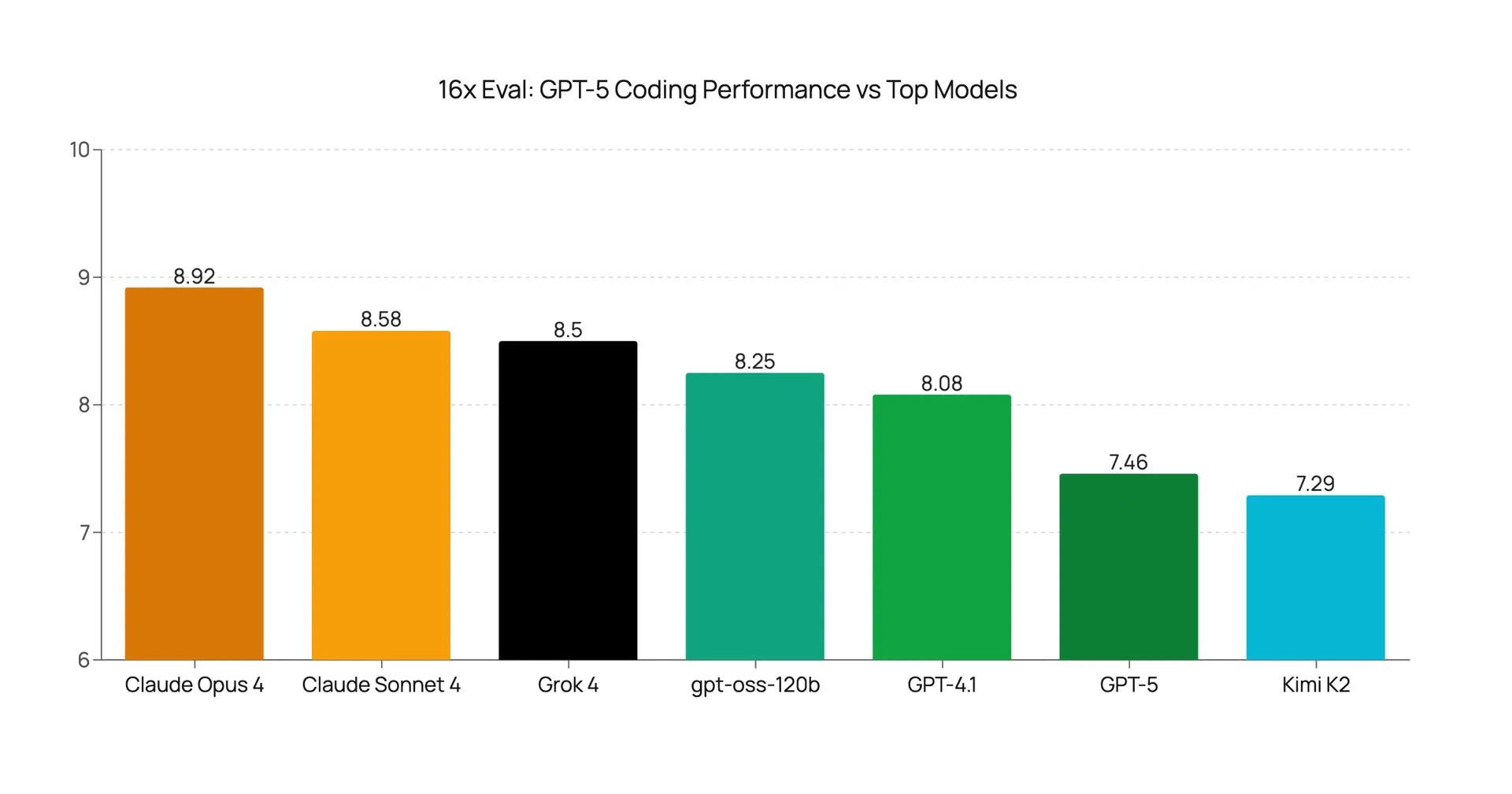
GPT-5 Coding Evaluation: Underwhelming Performance Given the Hype
GPT-5 coding evaluation reveals underwhelming results vs. Claude 4, Grok 4, and even GPT-4.1 despite the hype.
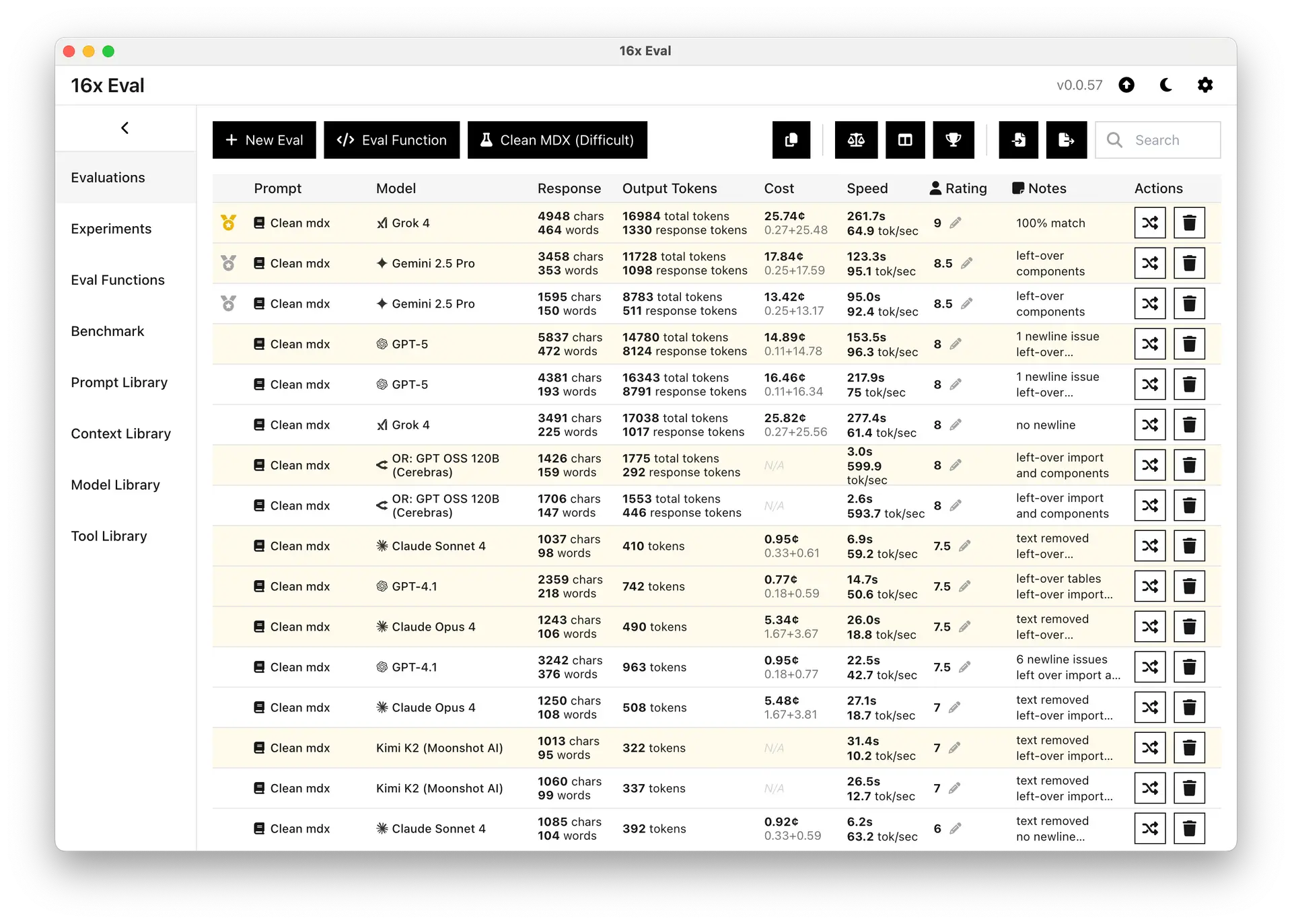
Clean MDX: New Coding Evaluation Task for Top AI Models
New Clean MDX coding task challenges top AI models. Evaluation results from GPT-5, Gemini 2.5 Pro, Grok 4, and more show surprising performance gaps.
The Identity Crisis: Why LLMs Don't Know Who They Are
A closer look at why large language models like Claude, Gemini, and GPT often fail to correctly state their own name or version, and what this means for LLM users.
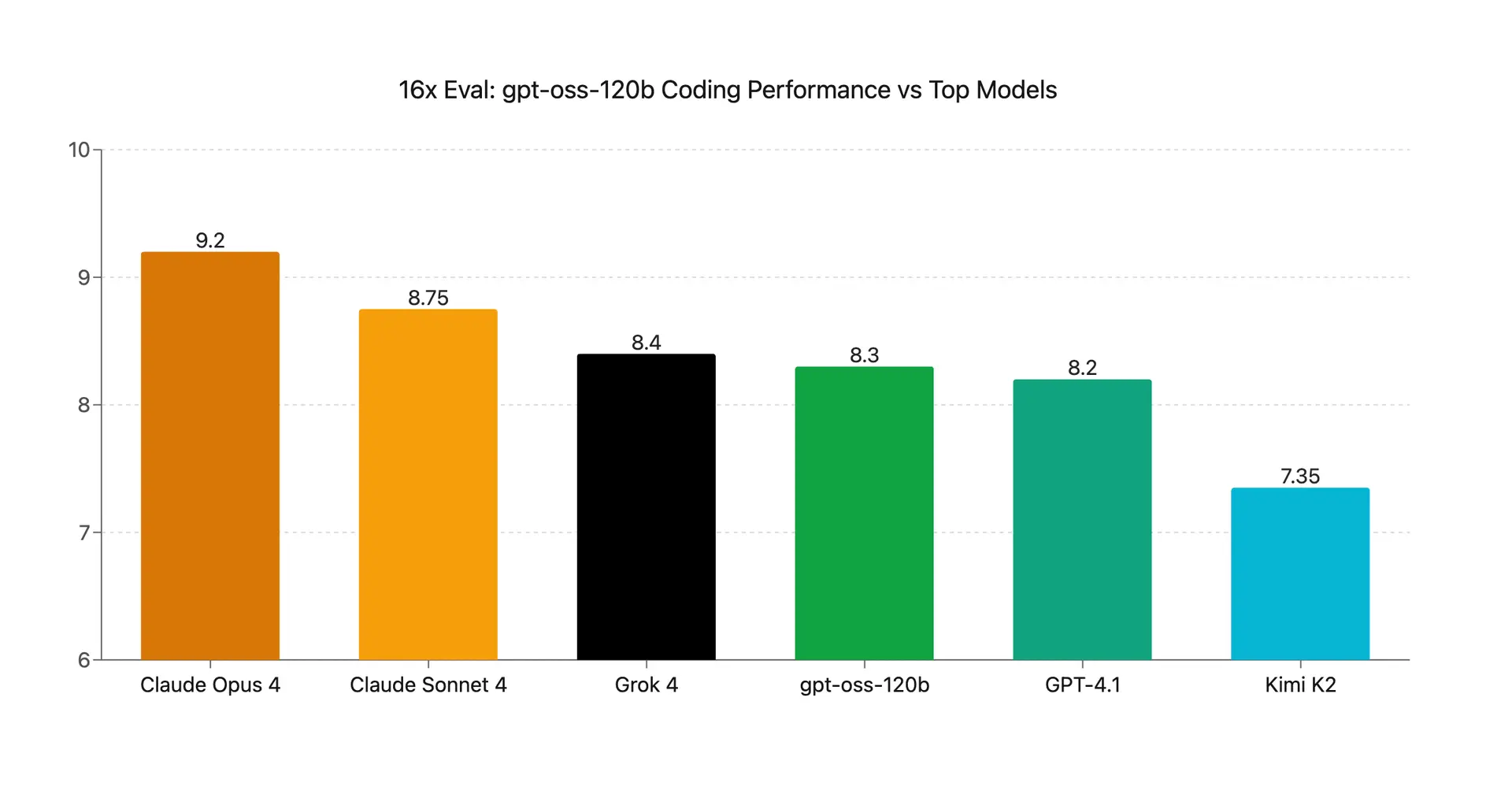
gpt-oss-120b Coding Evaluation: New Top Open-Source Model
Evaluation of gpt-oss-120b on coding tasks shows strong performance. We examine its performance across five coding challenges and compare it to top models.
GPT-OSS Provider Evaluation: Do All Providers Perform the Same?
gpt-oss-120b evaluation across Cerebras, Fireworks, Together, and Groq reveals notable differences in speed and consistency.

The Pink Elephant Problem: Why "Don't Do That" Fails with LLMs
Why negative instructions like "don't do X" fail with LLMs, the psychology behind it, and how to write better prompts.
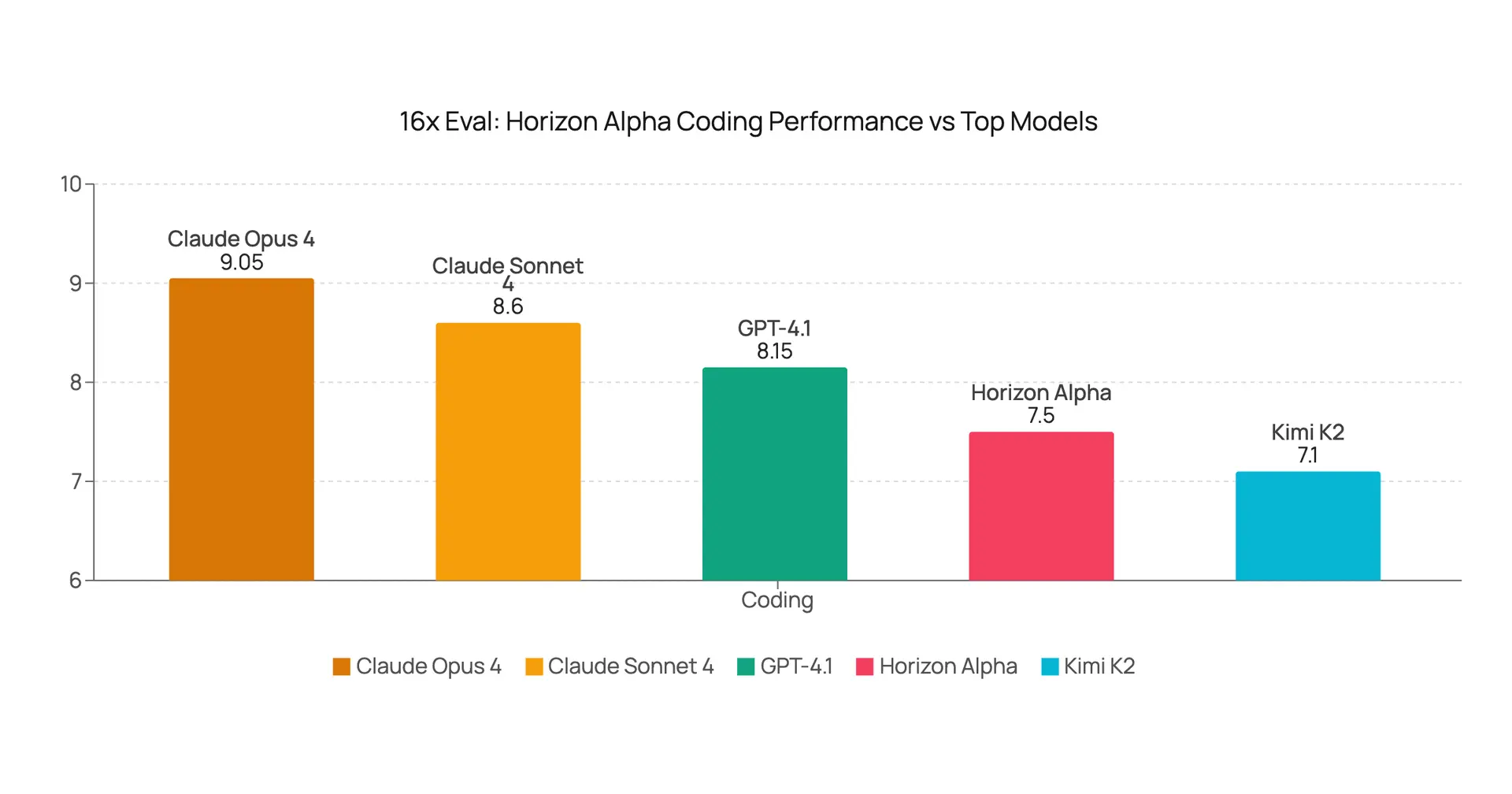
Horizon Alpha Coding Evaluation: The New Stealth Model from OpenRouter
Evaluation of the new stealth model, Horizon Alpha on coding tasks, analyzing its unique characteristics, performance against other top models, and possible identity.
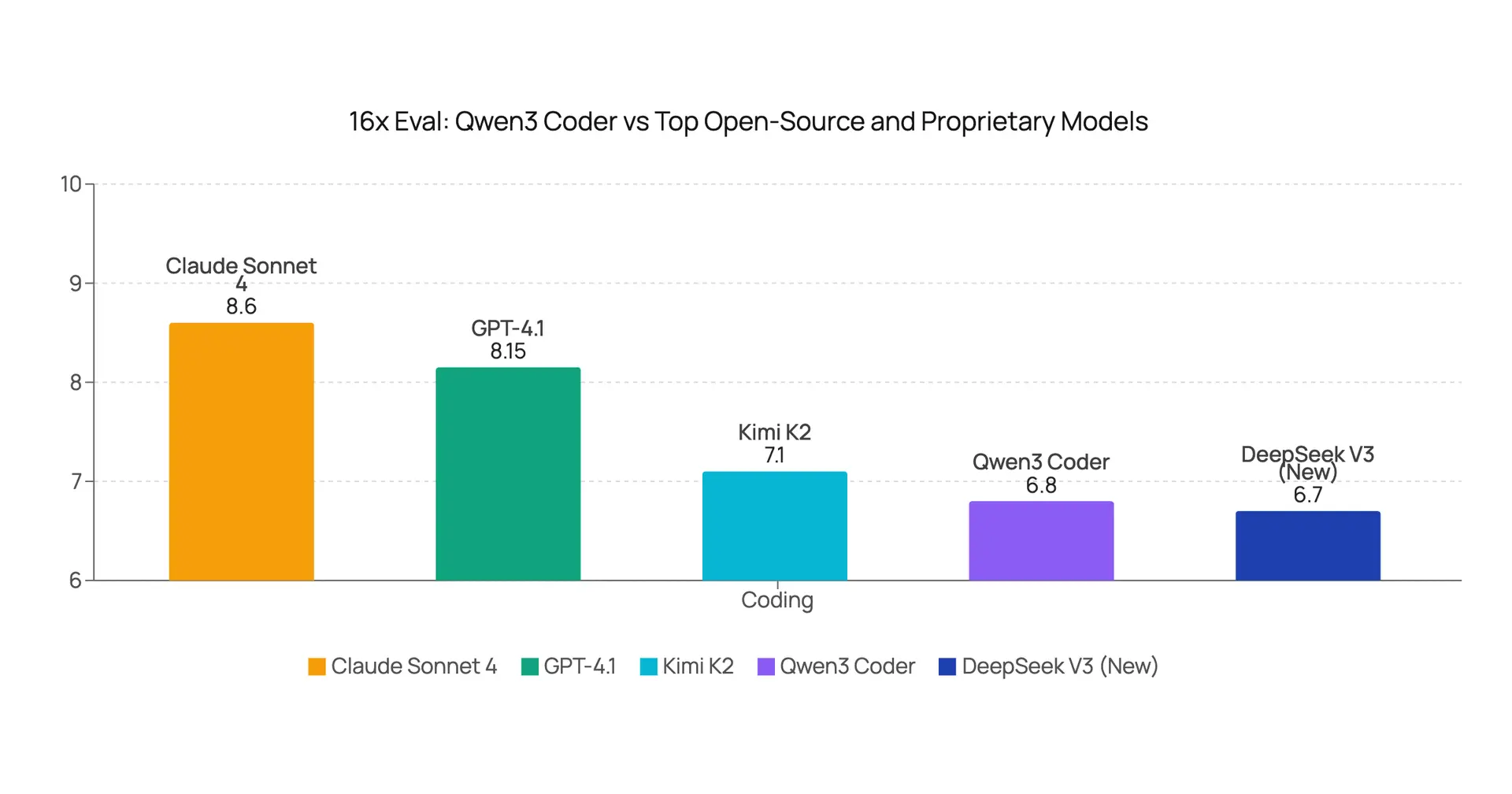
Qwen3 Coder Performance Evaluation: A Comparative Analysis Against Leading Models
Qwen3 Coder evaluation on coding tasks vs. leading models including Kimi K2, DeepSeek V3, Gemini 2.5 Pro, and Claude Sonnet 4.
Kimi K2 Evaluation Results: Top Open-Source Non-Reasoning Model for Coding
Kimi K2 model evaluation on coding and writing tasks vs. Claude 4, GPT-4.1, Gemini 2.5 Pro, and Grok 4.
Kimi K2 Provider Evaluation: Significant Performance Differences Across Platforms
Kimi K2 provider evaluation: DeepInfra, Groq, Moonshot AI, Together show major differences in speed, stability, and quality.
Grok 4 Evaluation Results: Strong Performance with Reasoning Trade-offs
Comprehensive evaluation of xAI Grok 4 model performance on coding, writing, and image analysis tasks, comparing against Claude 4, Gemini 2.5 Pro, and other leading models.
9.9 vs 9.11: Which One is Bigger? It Depends on Context
Why AI models get 9.9 vs 9.11 wrong: context matters in math, versioning, and book chapters for both humans and language models.
Claude 4, Gemini 2.5 Pro, and GPT-4.1: Understanding Their Unique Quirks
A practical guide to the quirks of top LLMs: Claude 4, Gemini 2.5 Pro, and GPT-4.1. Learn how their traits affect output and how you can adapt prompts for best results.
New Claude Models Default to Full Code Output, Stronger Prompt Required
Latest Claude models default to full code output vs. older models. Learn how to get concise output with stronger prompts.
Why Gemini 2.5 Pro Won't Stop Talking (And How to Fix It)
Learn how to manage Gemini 2.5 Pro's verbose output, especially for coding, and compare its behavior with other models like Claude and GPT.
Claude Opus 4 and Claude Sonnet 4 Evaluation Results
A detailed analysis of Claude Opus 4 and Claude Sonnet 4 performance on coding and writing tasks, with comparisons to GPT-4.1, DeepSeek V3, and other leading models.
Mistral Medium 3 Coding and Writing Evaluation
A detailed look at Mistral Medium 3's performance on coding and writing tasks, compared to top models like GPT-4.1, Claude 3.7 Sonnet, and Gemini 2.5 Pro.