Mistral Medium 3 is the latest medium-sized model from Mistral.
We recently evaluated Mistral Medium 3 via OpenRouter, comparing it to leading models such as GPT-4.1, Claude 3.7 Sonnet, DeepSeek V3, and Gemini 2.5 Pro.
Here's a summary of the results:
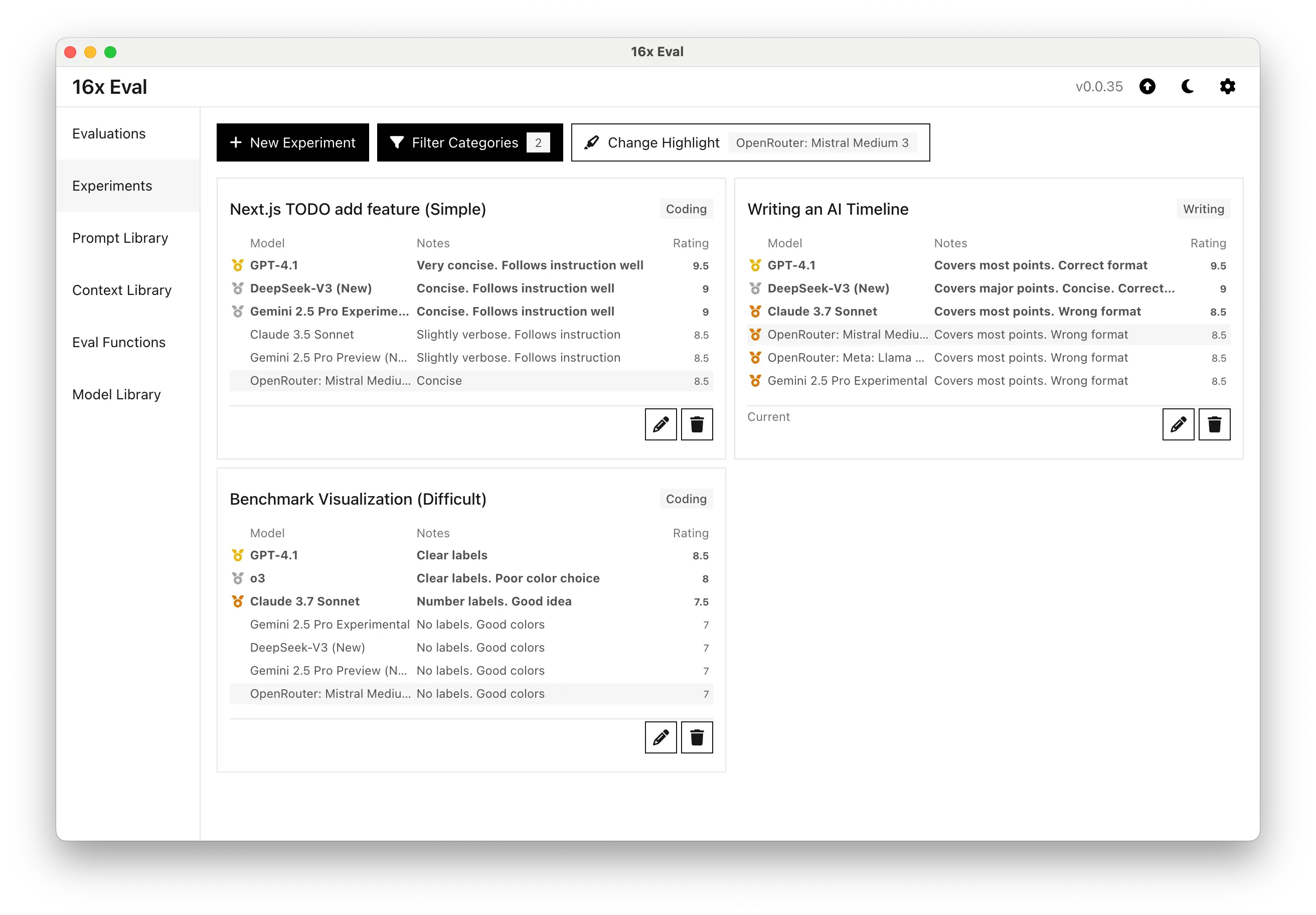
Coding: Simple TODO App Feature
For the simple task of adding a feature to a Next.js TODO app, Mistral Medium 3 delivered a concise and correct response.
The model earned a solid 8.5/10 rating, just behind DeepSeek V3 (New) which is still the best performing model in the medium-sized category:
While Mistral Medium 3's output was concise, it did not follow the exact instructions as well as the top models such as GPT-4.1, and Gemini 2.5 Pro Experimental, which produced even more concise and instruction-following code.
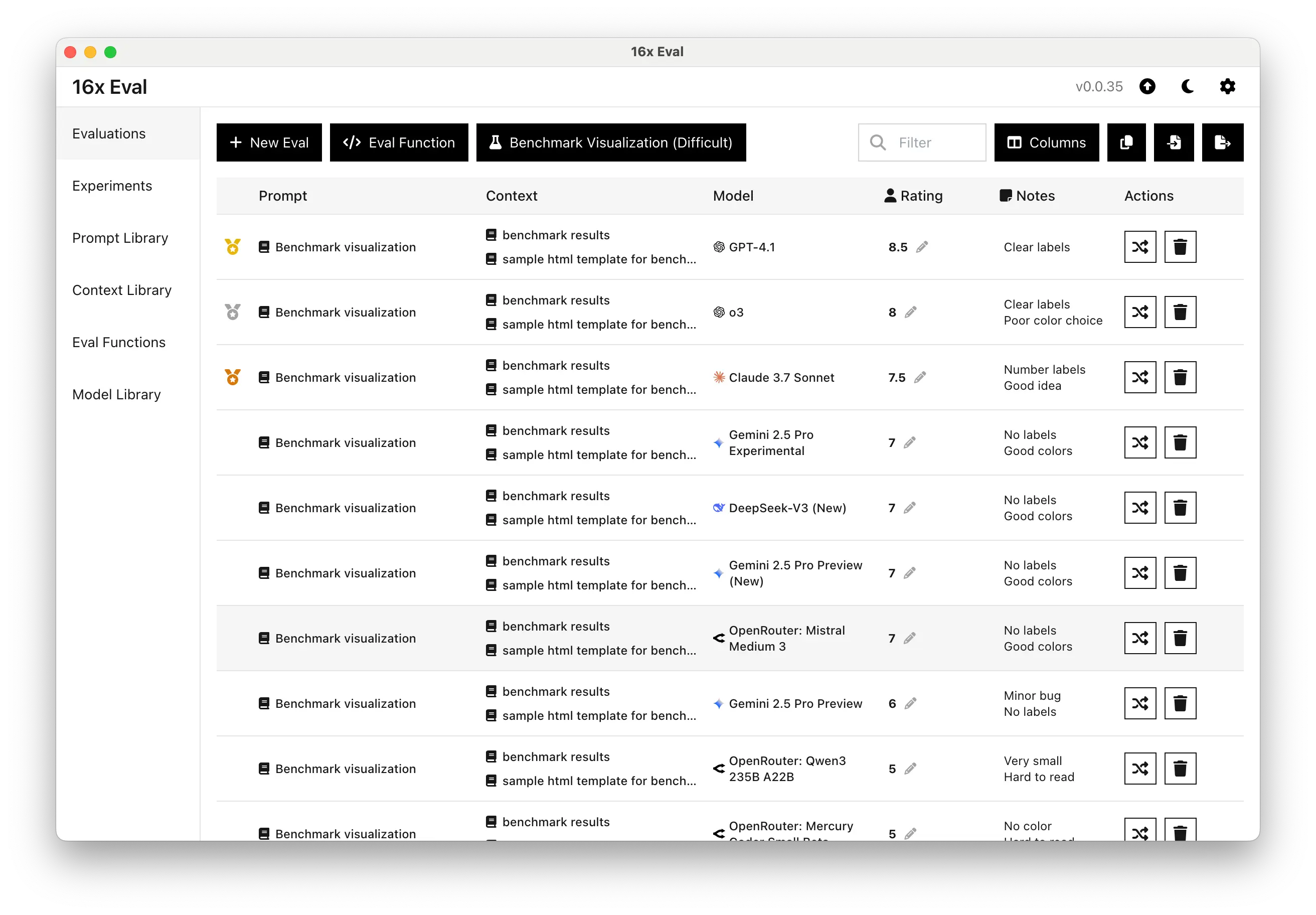
Coding: Complex Benchmark Visualization
When tested on a more complex coding problem, generating a visualization of benchmark results using code, Mistral Medium 3's performance was average.
It produced code with good color choices but lacked clear labels in the visualization, scoring a 7/10, similar to DeepSeek V3 (New) and Gemini 2.5 Pro Preview.
Models like GPT-4.1 and o3 outperformed Mistral Medium 3 in this area, offering clearer, more user-friendly visualization with better labels.
Here is how the model scored against other models:
Writing Tasks
On our writing evaluation task involving writing an AI timeline, Mistral Medium 3 covered most of the required points, demonstrating strong comprehension and content coverage.
However, it did not follow the exact format that was requested, which affected its overall rating. Its 8.5/10 score put it in line with Claude 3.7 Sonnet and Gemini 2.5 Pro Experimental, but a step behind GPT-4.1 and DeepSeek V3 (New), which both excelled in both content and formatting.
For users who prioritize substance over strict formatting, Mistral Medium 3 is a solid option. But if you need perfect adherence to specific formats, you may want to consider one of the higher-rated models.
Evaluation Results Table
Here are the evaluation results in table format for Mistral Medium 3 compared to other models.
We may use a variant of the prompt for certain models to perform "style control". This is our best effort to ensure all outputs are consistent in style during evaluation, as we prefer concise response over verbose ones.
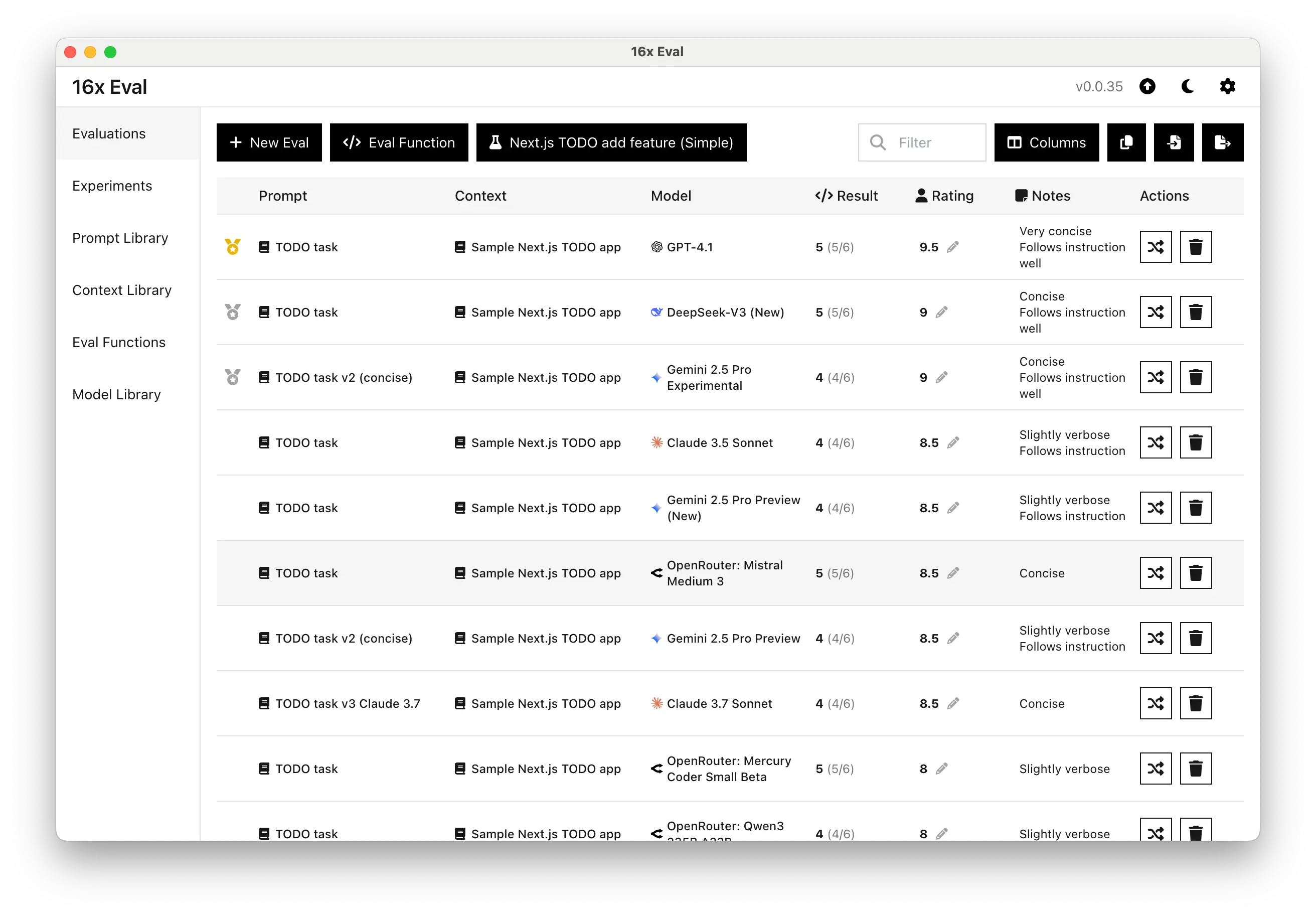
For the simple Next.js TODO app coding task:
| Ranking | Prompt | Model | Rating | Notes |
|---|---|---|---|---|
| 1 | TODO task | GPT-4.1 | 9.5/10 | Very concise Follows instruction well |
| 2 | TODO task | DeepSeek-V3 (New) | 9/10 | Concise Follows instruction well |
| 2 | TODO task v2 (concise) | Gemini 2.5 Pro Experimental | 9/10 | Concise Follows instruction well |
| 4 | TODO task | Claude 3.5 Sonnet | 8.5/10 | Slightly verbose Follows instruction |
| 4 | TODO task | Gemini 2.5 Pro Preview (New) | 8.5/10 | Slightly verbose Follows instruction |
| 4 | TODO task | OpenRouter: Mistral Medium 3 | 8.5/10 | Concise |
| 4 | TODO task v2 (concise) | Gemini 2.5 Pro Preview | 8.5/10 | Slightly verbose Follows instruction |
| 4 | TODO task v3 Claude 3.7 | Claude 3.7 Sonnet | 8.5/10 | Concise |
| 9 | TODO task | OpenRouter: Qwen3 235B A22B | 8/10 | Slightly verbose |
And for the more complex benchmark visualization task:
| Ranking | Prompt | Model | Rating | Notes |
|---|---|---|---|---|
| 1 | Benchmark visualization | GPT-4.1 | 8.5/10 | Clear labels |
| 2 | Benchmark visualization | o3 | 8/10 | Clear labels Poor color choice |
| 3 | Benchmark visualization | Claude 3.7 Sonnet | 7.5/10 | Number labels Good idea |
| 4 | Benchmark visualization | Gemini 2.5 Pro Experimental | 7/10 | No labels Good colors |
| 4 | Benchmark visualization | DeepSeek-V3 (New) | 7/10 | No labels Good colors |
| 4 | Benchmark visualization | Gemini 2.5 Pro Preview (New) | 7/10 | No labels Good colors |
| 4 | Benchmark visualization | OpenRouter: Mistral Medium 3 | 7/10 | No labels Good colors |
| 8 | Benchmark visualization | Gemini 2.5 Pro Preview | 6/10 | Minor bug No labels |
| 9 | Benchmark visualization | OpenRouter: Qwen3 235B A22B | 5/10 | Very small Hard to read |
And for the AI timeline writing task:
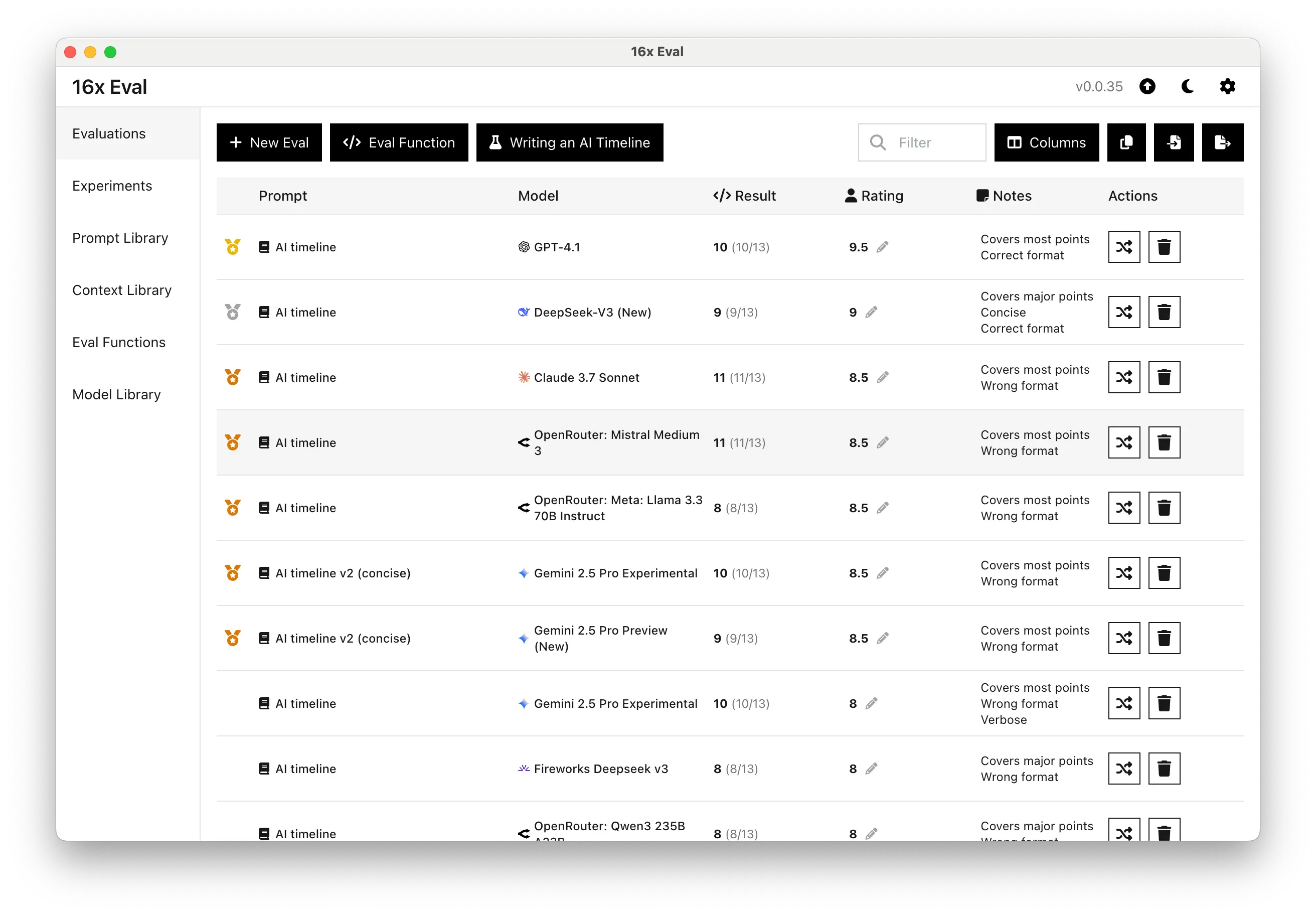
| Ranking | Prompt | Model | Rating | Notes |
|---|---|---|---|---|
| 1 | AI timeline | GPT-4.1 | 9.5/10 | Covers most points Correct format |
| 2 | AI timeline | DeepSeek-V3 (New) | 9/10 | Covers major points Concise Correct format |
| 3 | AI timeline | Claude 3.7 Sonnet | 8.5/10 | Covers most points Wrong format |
| 3 | AI timeline | OpenRouter: Mistral Medium 3 | 8.5/10 | Covers most points Wrong format |
| 3 | AI timeline | OpenRouter: Meta: Llama 3.3 70B Instruct | 8.5/10 | Covers most points Wrong format |
| 3 | AI timeline v2 (concise) | Gemini 2.5 Pro Experimental | 8.5/10 | Covers most points Wrong format |
| 3 | AI timeline v2 (concise) | Gemini 2.5 Pro Preview (New) | 8.5/10 | Covers most points Wrong format |
| 8 | AI timeline | Gemini 2.5 Pro Experimental | 8/10 | Covers most points Wrong format Verbose |
| 8 | AI timeline | OpenRouter: Qwen3 235B A22B | 8/10 | Covers major points Wrong format |
Conclusion
Mistral Medium 3 is a well-rounded model that consistently ranks among the top five for both coding and writing tasks.
If you're looking for a dependable, mid-tier model for everyday development and writing needs, Mistral Medium 3 is a strong alternative to DeepSeek V3 (New).
Evaluation Data and Prompts
You can find all the prompts and evaluation data on our GitHub repository.
Effortless Evaluation with 16x Eval
This evaluation was conducted locally using 16x Eval.
If you are looking to run your own evaluations for various models, try out 16x Eval.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.