Anthropic recently announced Claude Opus 4 and Claude Sonnet 4, positioning them as leaders in coding and complex problem-solving.
We tested both Claude Opus 4 and Claude Sonnet 4 (default mode, no extended thinking) across multiple coding and writing tasks in our evaluation set to see how they perform against other models.
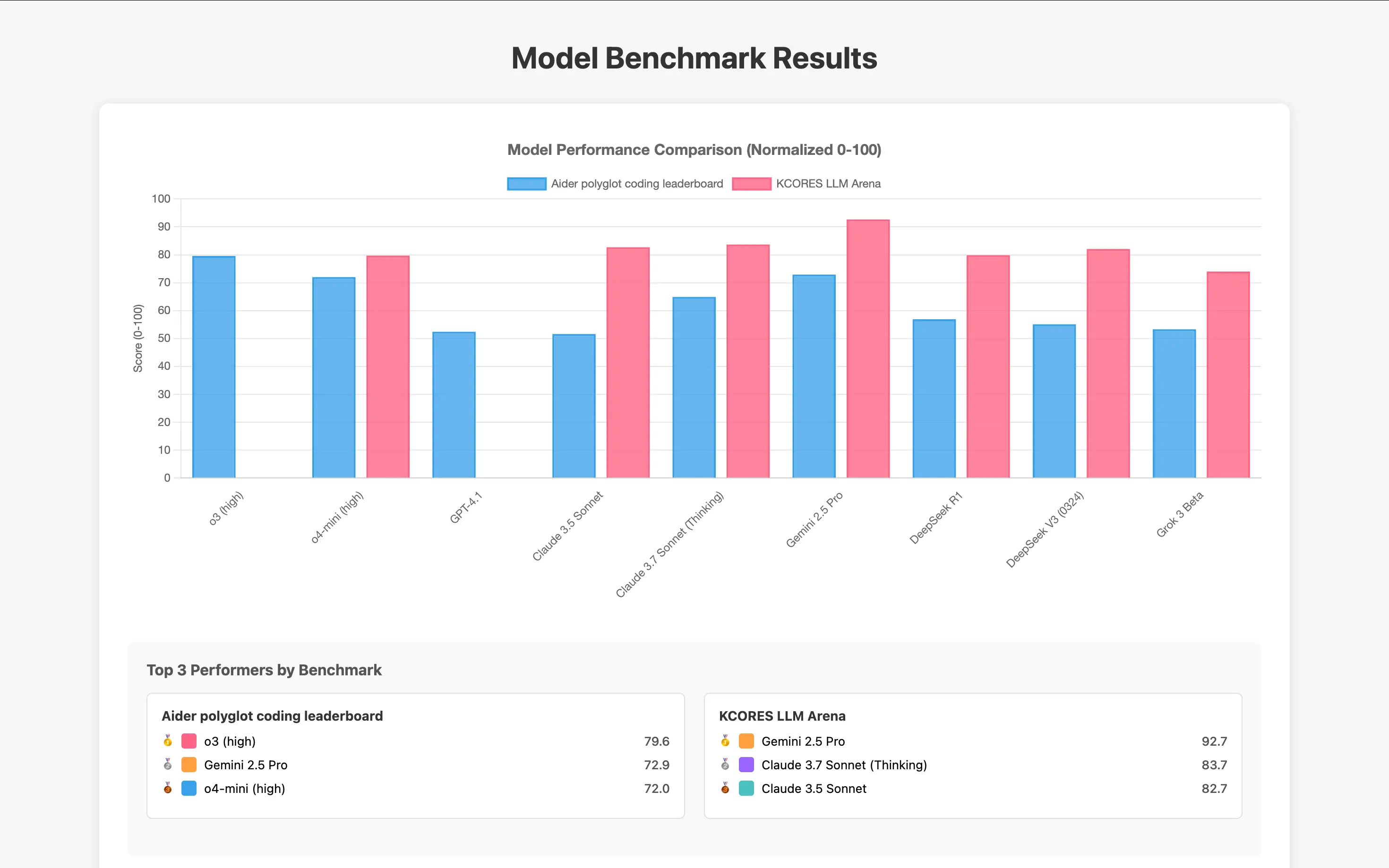
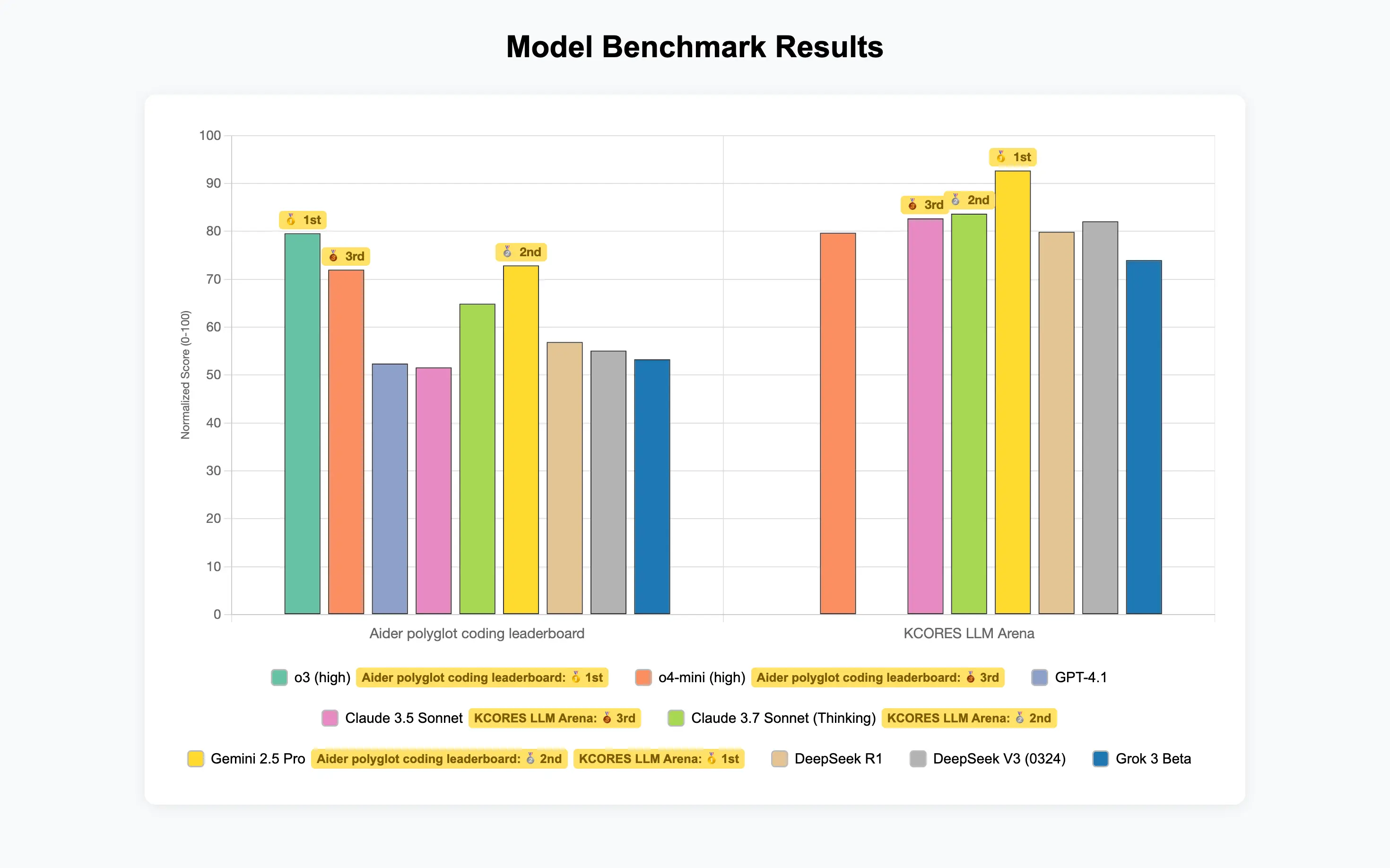
Our results are consistent with Anthropic's claims of state-of-the-art performance with 72.5% on SWE-bench Verified for Opus 4 and 72.7% for Sonnet 4 (default mode, no extended thinking).
Here are the summaries of the evaluations across 4 tasks:
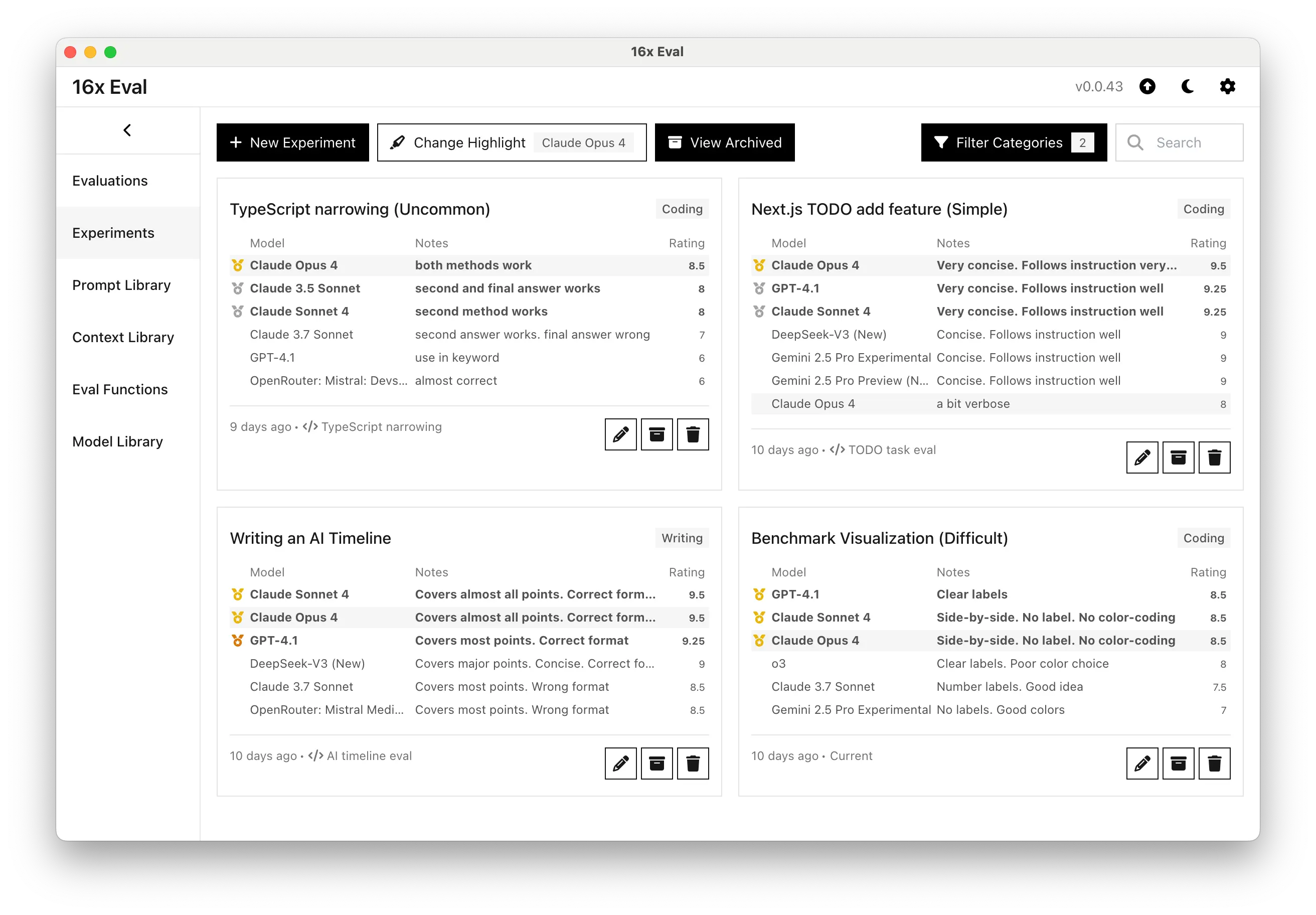

Simple Coding Task: Next.js TODO App
For a straightforward task of adding features to a Next.js TODO app, both Claude models demonstrated impressive conciseness and instruction-following capabilities. Claude Opus 4 took the top spot with a remarkable 9.5/10 rating.
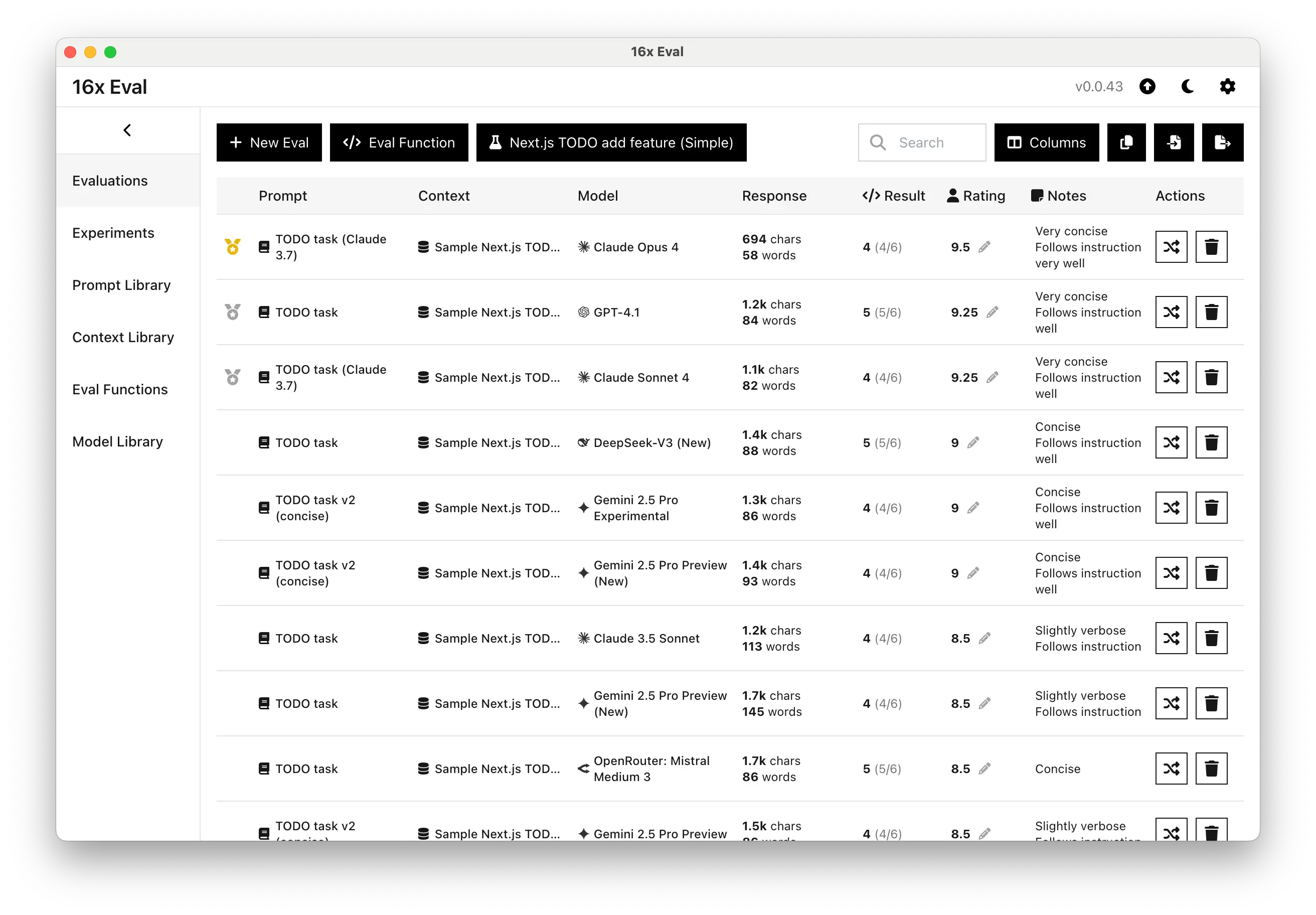
Claude Sonnet 4 also performed strongly, tying with GPT-4.1 at 9.25/10.
Both Claude models produced notably more concise code compared to other models in the test while maintaining correct functionality.
Complex Visualization Task
When tested on creating benchmark visualizations from data, both Claude models scored 8.5/10, demonstrating solid performance.
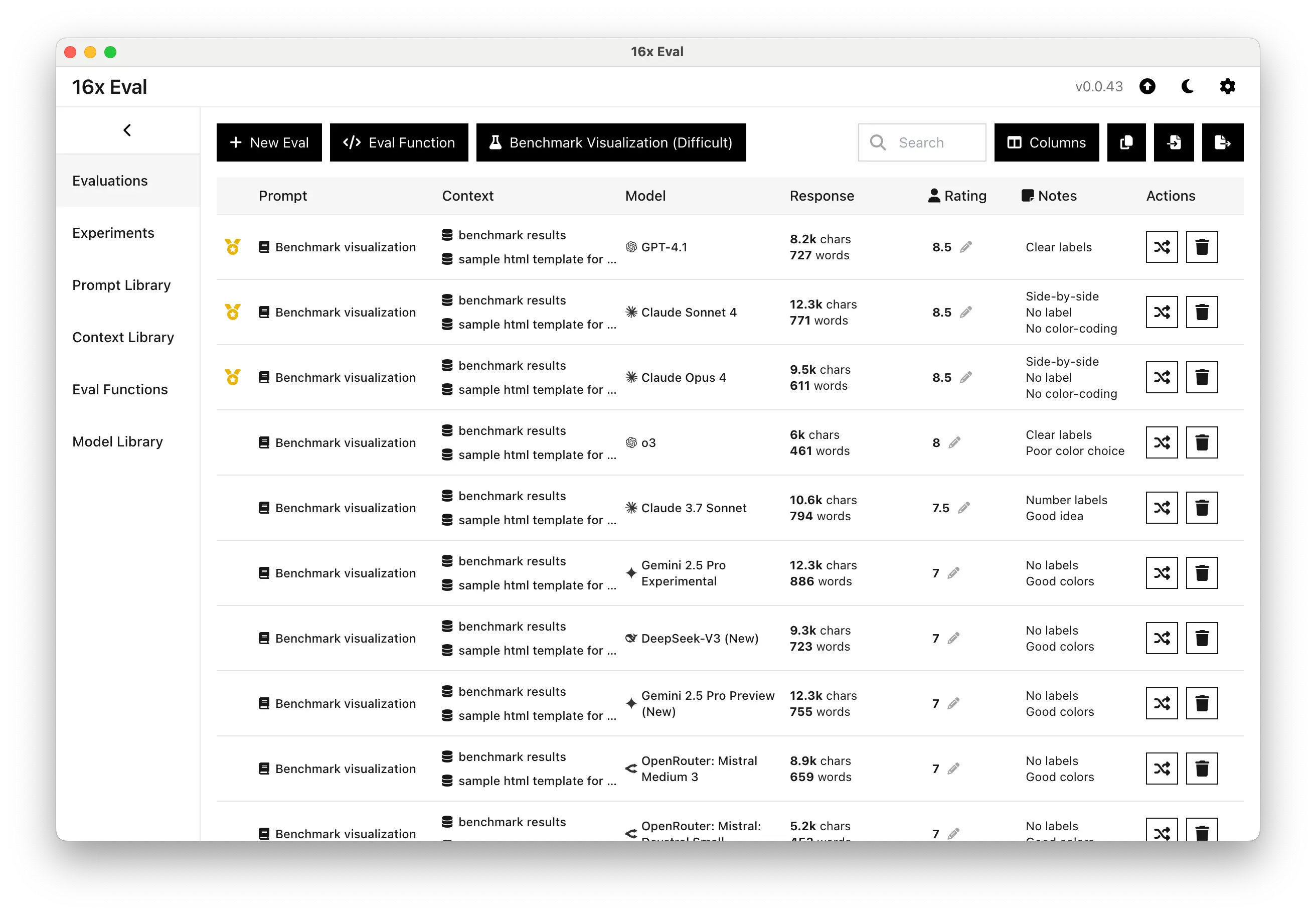
Both Claude 4 models produced side-by-side comparisons for each model, which we found to be a novel approach that no other model attempted. However, they lacked clear labels and color-coding that would improve readability.
GPT-4.1 matched their score, without side-by-side comparisons, but provided clearer labels.
TypeScript Type Narrowing Challenge
On an uncommon TypeScript type narrowing problem, Claude Opus 4 excelled with an 8.5/10 rating. The model provided two working methods, showing deep understanding of TypeScript's type system. Claude Sonnet 4 scored 8/10, with its second method working correctly.

This specialized task revealed the Claude 4 models' strengths in handling complex, less common programming scenarios. Both GPT-4.1 and Gemini 2.5 Pro used the in keyword approach, which was less optimal.
Writing Task: AI Timeline Creation
Both Claude 4 models achieved top scores on the AI timeline writing task, earning 9.5/10 ratings. They covered 16 out of 18 required points while following the correct format, demonstrating strong comprehension and attention to detail.
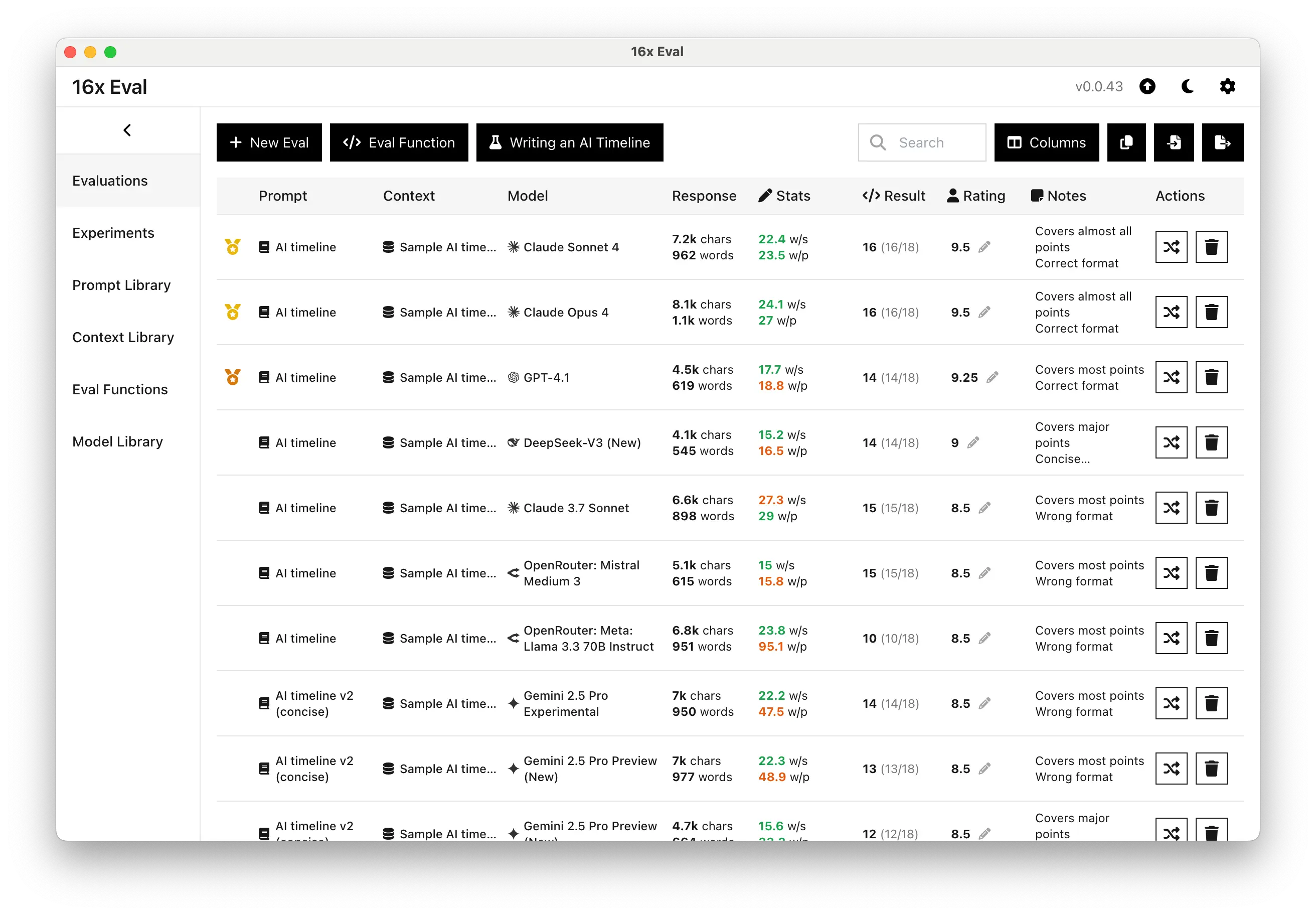
Both models outperformed GPT-4.1, which covered fewer points, and significantly exceeded other models that struggled with format compliance.
Recommendations for Developers
Claude Opus 4 should be used when you need the most concise, precise code generation, particularly for complex tasks requiring sustained focus. However, at $15/$75 per million tokens (input/output), it comes at a premium price point.
Claude Sonnet 4 provides an excellent balance of capability and efficiency. It matches Opus 4's coding performance on many tasks while being significantly more cost-effective at $3/$15 per million tokens.
For most day-to-day coding tasks, Sonnet 4 delivers frontier performance without the premium price, making it the more practical choice for regular development work, replacing the old Claude 3.7 Sonnet.
Developers should also check out Claude Code, an agentic coding tool made by Anthropic that leverages these new models for agentic coding.
Recommendations for Content Writers
Content writers will find both Claude 4 models excel at following specific formatting requirements and maintaining consistency across long documents. The models' attention to detail and ability to cover required points comprehensively make them valuable for technical writing, documentation, and structured content creation.
Opus 4 is priced at $15/$75 per million tokens, while Sonnet 4 offers similar quality for most writing tasks at a significantly more accessible price point of $3/$15 per million tokens.
For regular content creation, blog posts, documentation, and marketing copy, Sonnet 4 provides excellent value while maintaining the high-quality output that makes Claude 4 models stand out.
Running Your Own Evaluations with 16x Eval
These evaluations were conducted using 16x Eval, a desktop application that makes it easy to compare AI models on your specific use cases. You can replicate these tests or create your own evaluations to find the best model for your particular needs.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.