Large Language Models (LLMs) are becoming powerful tools for various tasks. Google's Gemini 2.5 Pro is one such advanced model.
While highly capable, we've noticed that by default, Gemini 2.5 Pro can be rather verbose when generating code. The output often includes excessive comments or outputting code that are not modified. This verbosity can slow down workflows if you need to parse through unnecessary text.
"Be Concise" Prompting
We experimented with different phrasings to reduce Gemini 2.5 Pro's output. We found that simply adding the instruction "Minimize prose" to the prompt was not effective in making Gemini 2.5 Pro less verbose.
However, adding a more direct instruction, "Be concise" to the prompt, as seen in our "TODO task v2 (concise)" prompt, yielded much better results for coding tasks.
| Prompt Phrasing | Effectiveness on Gemini 2.5 Pro |
|---|---|
| "Minimize prose" | Not effective |
| "Be concise" | Effective |
Experiment Results
With the "Be concise" instruction, the Gemini 2.5 Pro Preview (New) (gemini-2.5-pro-preview-05-06) output for the same TODO task dropped to 1.4k characters and was rated "concise". The Gemini 2.5 Pro Experimental (gemini-2.5-pro-exp-03-25) model with the "concise" prompt was even shorter at 1.2k characters.
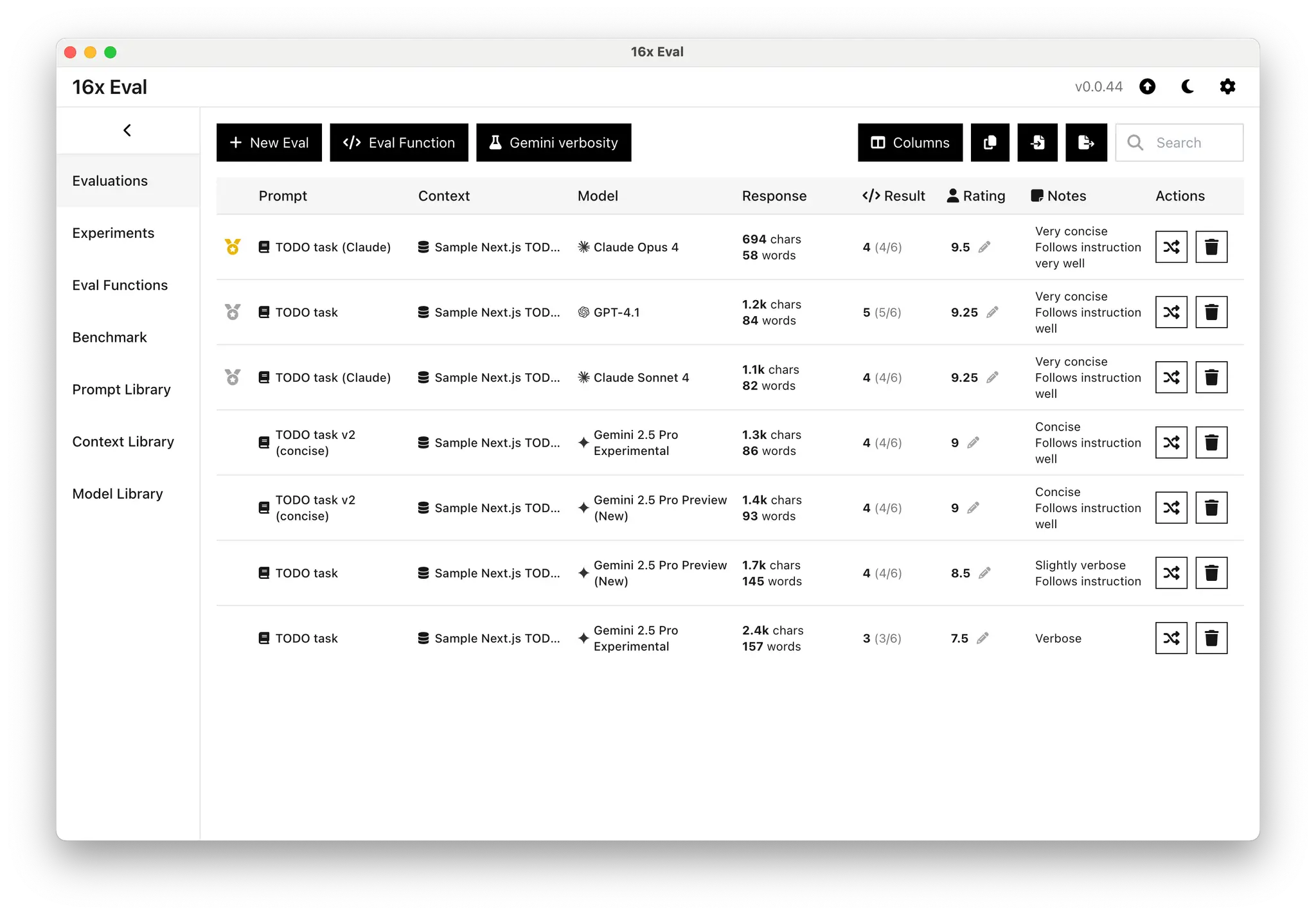
| Model | Prompt | Output | Verbosity |
|---|---|---|---|
| Gemini 2.5 Pro Experimental | "TODO task" | 2.4k characters | Verbose |
| Gemini 2.5 Pro Preview (New) | "TODO task" | 1.7k characters | Verbose |
| Gemini 2.5 Pro Preview (New) | "TODO task v2 (concise)" | 1.4k characters | Concise |
| Gemini 2.5 Pro Experimental | "TODO task v2 (concise)" | 1.2k characters | Concise |
Let's take a closer look at the prompts and the output.
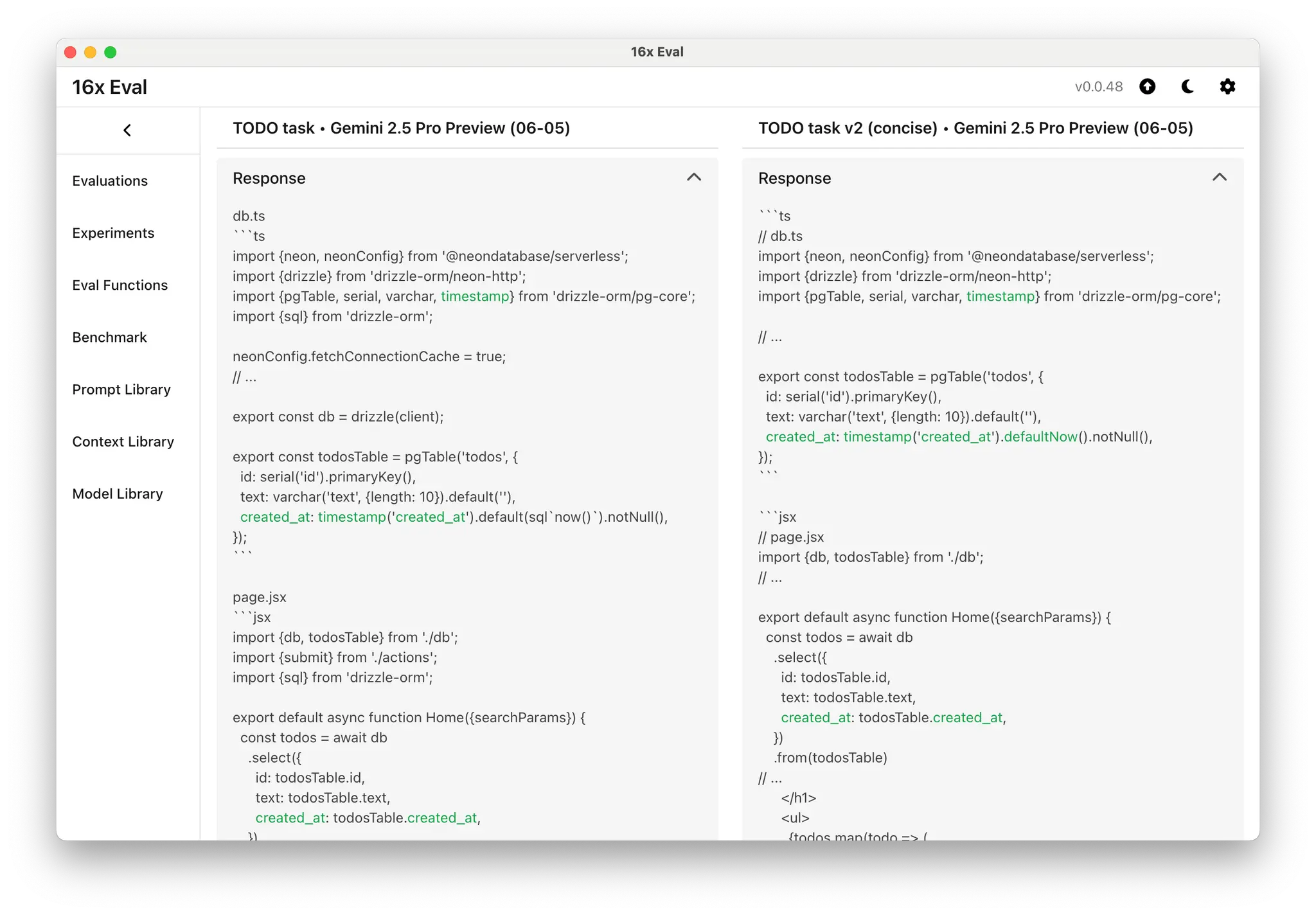
The original "TODO task" prompt:
add created_at field to todos, update both backend and frontend.
Instructions for the output format:
- Output code without descriptions, unless it is important.
- Minimize prose, comments and empty lines.
- Only show the relevant code that needs to be modified. Use comments to represent the parts that are not modified.
- Make it easy to copy and paste.
- Consider other possibilities to achieve the result, do not be limited by the prompt.
The "TODO task v2 (concise)" prompt with "Be concise" instruction:
add created_at field to todos, update both backend and frontend.
Instructions for the output format:
- Be concise.
- Output code without descriptions, unless it is important.
- Minimize prose, comments and empty lines.
- Only show the relevant code that needs to be modified. Use comments to represent the parts that are not modified.
- Make it easy to copy and paste.
- Consider other possibilities to achieve the result, do not be limited by the prompt.
Sample output from Gemini 2.5 Pro Preview (New) with the original "TODO task" prompt:
export default async function Home({ searchParams }) {
const todos = await db
.select({
id: todosTable.id,
text: todosTable.text,
created_at: todosTable.created_at, // Added
})
.from(todosTable)
.limit(20)
// .orderBy(searchParams.asc ? sql`${todosTable.id} ASC` : sql`${todosTable.id} DESC`); // Old
// Changed to sort by created_at by default (newest first if asc is not present/false)
.orderBy(
searchParams.asc === 'true'
? todosTable.created_at.asc()
: todosTable.created_at.desc()
); // Modified
return <main key={todos[0]?.id}>{/* ... */}</main>;
}Sample output from Gemini 2.5 Pro Preview (New) using the "TODO task v2 (concise)" prompt:
export default async function Home({ searchParams }) {
const todos = await db
.select({
id: todosTable.id,
text: todosTable.text,
created_at: todosTable.created_at, // added
})
.from(todosTable)
.limit(20)
.orderBy(searchParams.asc ? sql`${todosTable.id} ASC` : sql`${todosTable.id} DESC`);
return <main key={todos[0]?.id}>{/* ... */}</main>;
}As you can see, the output from the second version with "Be concise" instruction is much shorter, with less comments and more concise code.
Why the Verbosity?
While we can't know Google's exact design decisions, there are a few possibilities:
- Educational training data bias: Gemini may be trained to prioritize helpfulness over brevity, leading to over-explanation. Its educational focus could stem from training data heavy on tutorial content.
- Conversational AI heritage: Google's conversational AI heritage (think Google Assistant) may influence Gemini to treat every interaction as a conversation rather than a command.
- Risk-averse design philosophy: Google may have designed Gemini to err on the side of over-explanation rather than under-explanation, especially given the potential consequences of providing insufficient context in critical applications.
Best Practices for Controlling Verbosity
Based on our testing with Gemini 2.5 Pro, here are some practical tips for managing its verbosity:
- Start prompts with clear, direct instructions about the desired output format
- Use specific keywords and phrases like:
- "Be concise"
- "Minimize prose"
- "Only show modified code"
- For code tasks, start with "Write code to..." instead of "Explain how to..."
"Be Concise" For Writing
While "Be concise" works well for managing verbosity in coding tasks, it's not a universal solution. Applying such a strict instruction to writing tasks, for instance, can be counterproductive. It might lead to outputs that are too brief, lacking necessary detail, or sounding unnatural.
For creative or explanatory writing, you generally want the model to elaborate and provide context. An overly concise response could miss the nuances or the comprehensive coverage required for a blog post or a report. Therefore, prompt engineering needs to be context-aware, adjusting for the specific type of output desired.
Claude Models
Gemini 2.5 Pro is not unique in requiring specific prompts to control output style for coding. Anthropic's models, like Claude Opus 4 and Claude Sonnet 4, tend to output full code blocks, even when explicit instructions are given to not do so.
Our analysis of Claude's full code output behavior showed that prompts tailored for Claude models, which include "Do NOT output full code", helped them achieve parity with other models in terms of outputting only the code that is modified.
OpenAI Models
OpenAI models such as GPT-4.1 seem to handle requests for conciseness in code well with general instructions.
In the same Next.js TODO task, GPT-4.1 responded with "Very concise" output (1249 characters) to the standard "TODO task" prompt, which included "Minimize prose" but not the harsher "Do NOT output full code".
This suggests different baseline behaviors regarding verbosity among models.
Model Evaluation with 16x Eval
Understanding how different models respond to prompts is key to using them effectively. If you are looking to run your own evaluations for various models and prompts, you might find tools like 16x Eval helpful.
It's a desktop application designed for running model comparisons locally, allowing you to test prompts and observe output characteristics like verbosity for your specific use cases.
