Recently, OpenAI released gpt-oss, which is available through several inference providers. Community reports suggest that performance can differ across providers, with Romain Huet from OpenAI confirming that performance and correctness can vary a bit across providers.
X user NomoreID also reported significant variations in stability and output quality for gpt-oss-120b on different platforms. The tests specifically focused on multilingual capability, where Groq seems to be worse than the other providers.
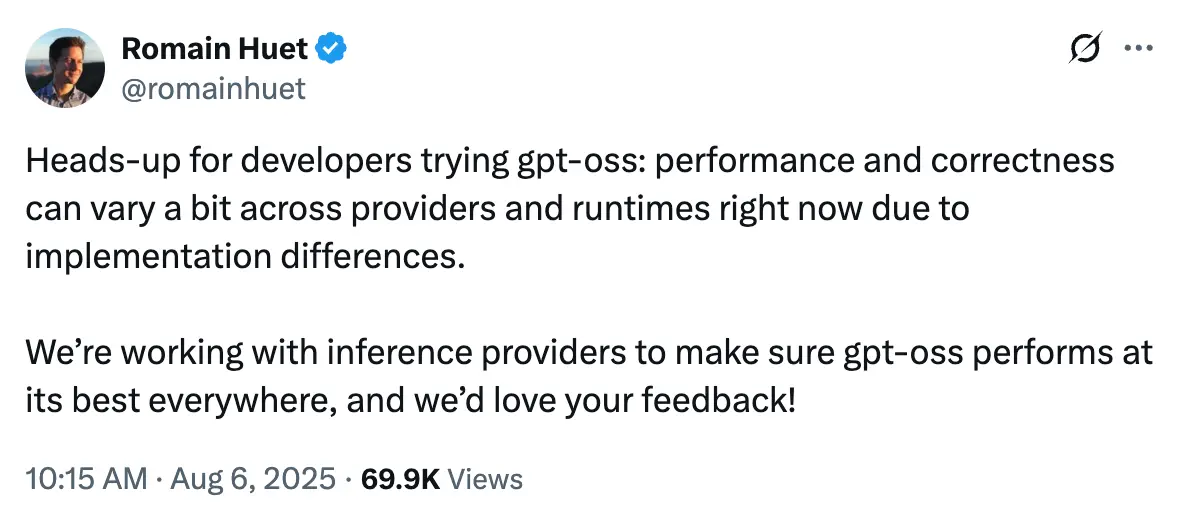
To validate these claims and understand the differences between providers, we evaluated gpt-oss-120b across four providers via OpenRouter: Cerebras, Fireworks, Together, and Groq.
Our test included one writing task and one coding task. All tests were conducted using the same prompts and settings for each provider to ensure a fair comparison. We did not specify custom temperature settings and instead rely on the default settings from the providers.
Writing Task Performance
The writing task required the model to generate a timeline of AI history. We ran the same prompt three times on each provider to check for consistency and quality variance.
We observed noticeable variance in response length for all providers, suggesting that the response length variation is not from the providers, but from the model itself.
Speed differences were noticeable, with providers like Cerebras and Groq delivering responses much faster than Fireworks and Together.
In terms of the output quality, Cerebras, Fireworks, and Together all produced at least one good response with a rating of 8 out of 10. Groq received a 7.5 rating on all three attempts.
Benchmark Visualization Task
For the benchmark visualization task, the model was asked to generate HTML and JavaScript code to display benchmark results. We used two attempts per provider to assess its ability to generate functional and well-formatted code.
Interestingly, both Cerebras and Fireworks produced code containing emojis in the comments. This suggests the behavior is a characteristic of the gpt-oss-120b model itself, rather than an artifact of a specific provider.
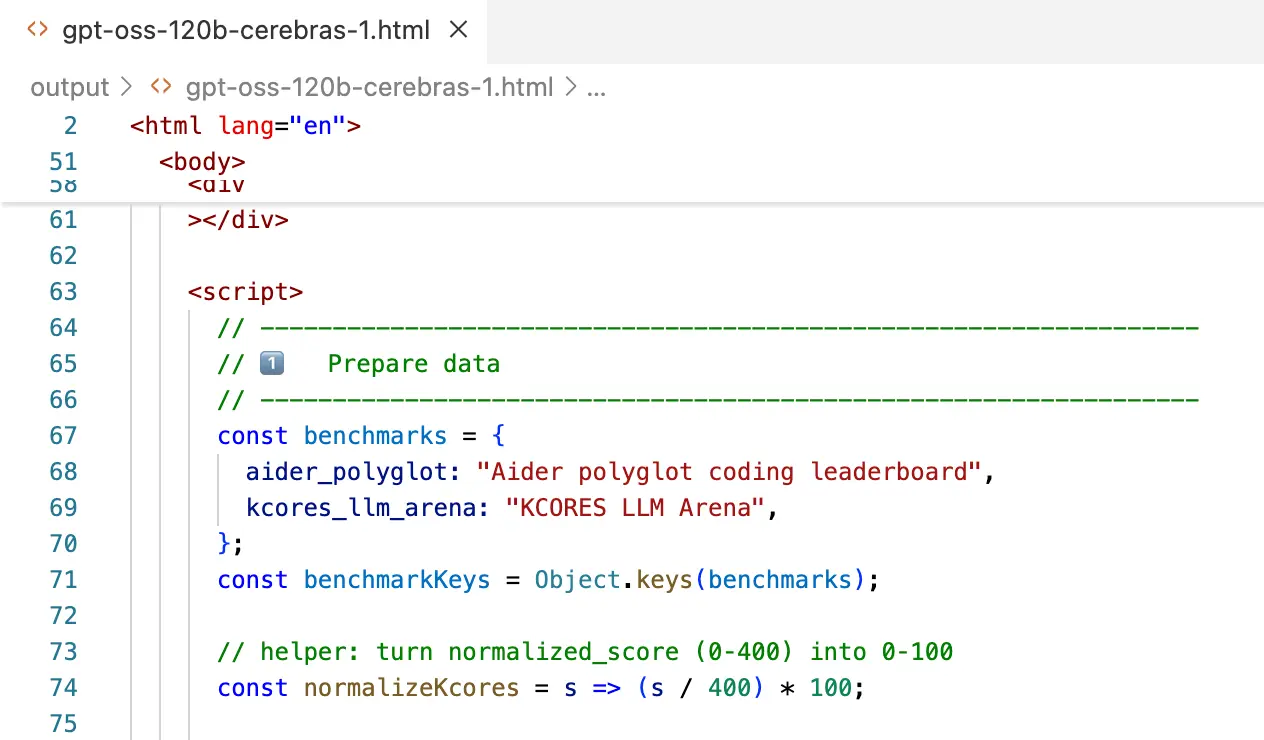
The style of the generated visualizations was similar across all providers, indicating that the core output is not heavily provider-dependent. However, we did notice some rendering issues:
- One attempt from Fireworks failed to render correctly, so we gave it another chance.
- All attempts on the Together provider produced a visualization that was too narrow, occupying only the top third of the screen.
In this task, Cerebras delivered the best average performance, scoring a consistent 8.5 on both of its attempts.
Provider Performance Summary
Based on our limited tests conducted on August 6, while the model output from various providers for gpt-oss-120b are largely consistent, we did see some notable differences between providers:
- Groq had slightly lower quality for the writing task
- Fireworks had a failed attempt for the visualization task
- Together had repeated rendering issues with the visualization task
Due to limited sample data, we cannot rule out the possibility that these differences are due to the natural variance of the model itself.
The table below shows the distribution of ratings achieved for each task, and the speed range for the writing task.
| Provider | Ratings (Writing) | Ratings (Visualization) | Speed range for writing (tokens/sec)* |
|---|---|---|---|
| Cerebras | 8, 7.5, 7.5 | 8.5, 8.5 | 522-757 |
| Fireworks | 8, 8, 7.5 | 8.5, 8, 1 | 133-179 |
| Groq | 7.5, 7.5, 7.5 | 8, 8 | 328-436 |
| Together | 8, 8, 7.5 | 8, 7.5 | 47-114 |
If we have to pick a provider to use for this model, Cerebras would be our top choice as it delivered consistent high-quality outputs on both tasks with good speed.
*: The speed is measured based on the entire request duration, including latency to first byte. Since the test is conducted in Singapore, network latency might have contributed to the lower speed than the officially reported 3000 tokens per second from Cerebras.
The evaluations in this post were conducted using 16x Eval, a desktop application for systematic AI model evaluation.

It helps you run tests across multiple models and providers, compare their outputs side-by-side, and analyze performance metrics like quality, speed, and consistency. This makes it easier to understand how a model will perform on the specific tasks that matter to you.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.