The same AI model can behave differently across providers due to variations in quantization, configuration, and infrastructure. To understand these differences for the newly released Kimi K2 model, we tested the model across seven different platforms on both coding and writing tasks.
Our evaluation reveals significant differences in speed, output quality, and consistency between providers.
Testing Methodology
We evaluated Kimi K2 across multiple providers using two distinct tasks:
- AI timeline writing task (technical writing assessment)
- Clean markdown coding task (programming evaluation)
Kimi K2 provider selection:
- For the writing task, we tested seven providers: DeepInfra, Groq, Moonshot AI (the original model creator), Novita, Parasail, Together, and Chutes.
- Unfortunately Chutes returned errors for all writing tests, so we dropped it from the writing task results.
- For the coding evaluation that was conducted later, we focused on four providers (DeepInfra, Groq, Moonshot AI, and Together) plus Chutes (based on requests from the OpenAI Discord community), dropping Novita and Parasail due to stability issues identified in the writing tests.
- All tests were done via the OpenRouter API using 16x Eval.
Other details:
- Each test was repeated three times to ensure reliability and measure consistency.
- All evaluations are rated by a human on a 1-10 scale. We also measured other metrics like token count and speed.
- When code failed to execute, we regenerated responses to avoid edge cases affecting the results.
Writing Task Performance
The AI timeline writing task revealed substantial provider differences in both speed and output characteristics.
In this task, the model was asked to write a timeline of events in the history of AI from 2015 to 2024.
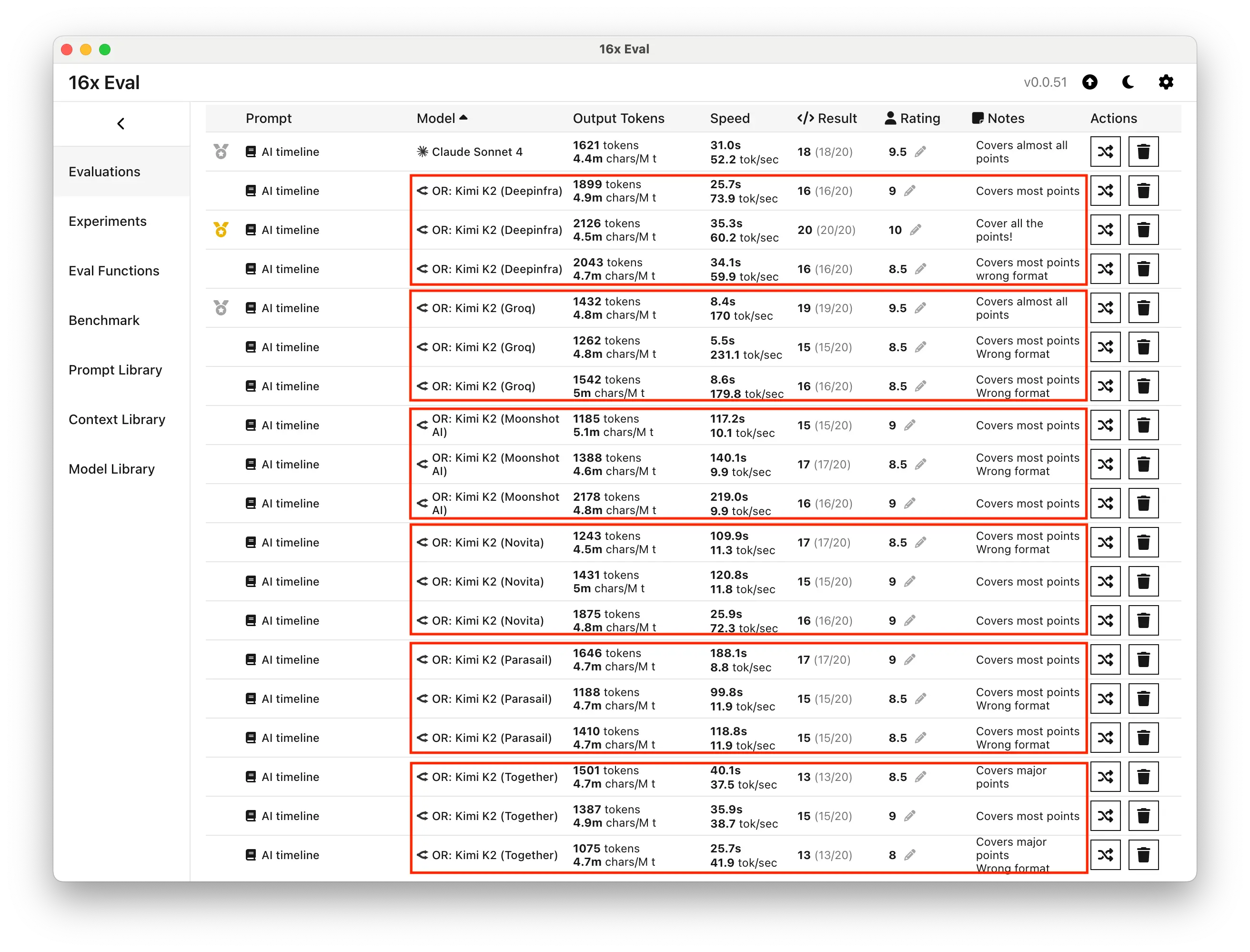
Here's the summary table for the writing task results:
| Provider | Speed (tokens / sec) | Response Length | Ratings | Notes |
|---|---|---|---|---|
| DeepInfra | 60-73 | ~2,000 tokens | 8.5, 9, 10 | Surprisingly good at fp4 |
| Groq | 170-230 | 1,300-1,500 tokens | 8.5, 8.5, 9.5 | Fastest provider |
| Moonshot AI | 10-10 | 1,200-2,200 tokens | 8.5, 9, 9 | Very slow, large response length variation |
| Novita | 11-72 | 1,200-1,800 tokens | 8.5, 9, 9 | Unstable speed |
| Parasail | 9-12 | 1,200-1,600 tokens | 8.5, 8.5, 9 | Consistently slow |
| Together | 38-42 | 1,100-1,500 tokens | 8, 8.5, 9 | Stable performance, large rating variation |
DeepInfra emerged as the standout performer, achieving ratings between 8.5 and 10, including one perfect 10 rating that surpassed Claude Sonnet 4's previous best of 9.5.
DeepInfra also consistently produced the longest responses at around 2,000 tokens while maintaining decent speed at approximately 60 tokens per second. Remarkably, this strong performance came from the fp4 quantization level, demonstrating that aggressive quantization doesn't necessarily harm output quality.
Groq delivered the fastest responses at roughly 170 tokens per second but generated shorter outputs (1,300-1,500 tokens) with ratings ranging from 8.5 to 9.5.
Together offered stable performance with consistent 40 tokens per second speed and moderate response lengths.
The slowest providers were Moonshot AI and Parasail, both operating at around 10-11 tokens per second. Moonshot AI showed the largest response length variations, ranging from 1,200 to 2,200 tokens across tests.
Coding Task Results
For the clean markdown coding task, we focused on consistency and accuracy rather than speed, since we had already established speed characteristics in the writing tests.
Clean markdown is a medium-level coding task that asks the model to write a function to convert markdown to plain text by removing or unwrapping the markdown formatting.
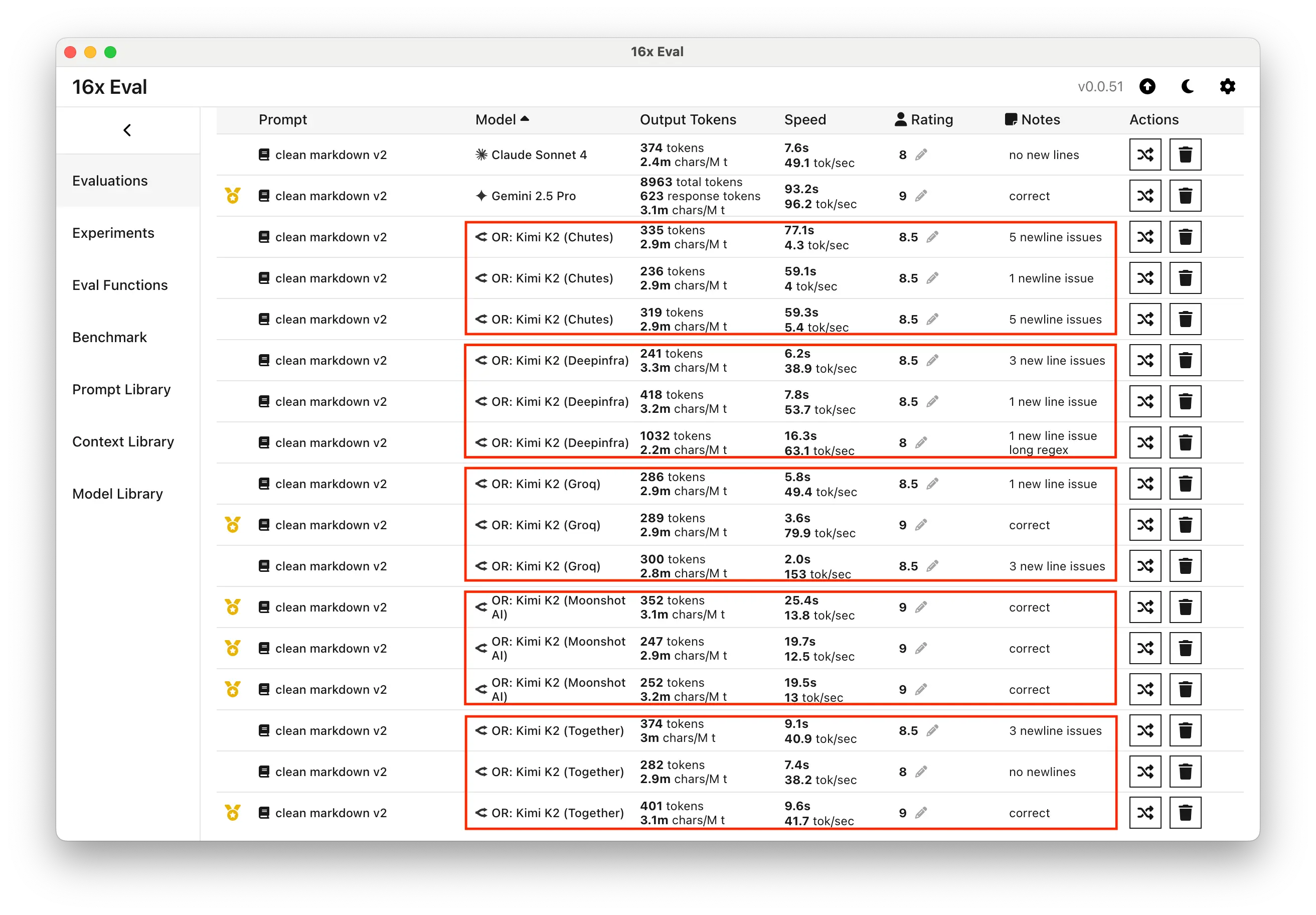
Here's the summary table for the coding task results:
| Provider | Response Length | Ratings | Notes |
|---|---|---|---|
| Chutes | 230-330 tokens | 8.5, 8.5, 8.5 | Consistent quality but lower rating |
| DeepInfra | 240-1030 tokens | 8, 8.5, 8.5 | Large variation in response length |
| Groq | 290-300 tokens | 8.5, 8.5, 9 | Consistent, but one response did not run |
| Moonshot AI | 250-350 tokens | 9, 9, 9 | Perfect consistency across tests |
| Together | 280-400 tokens | 8, 8.5, 9 | Stable performance, large rating variation |
Moonshot AI demonstrated remarkable consistency, achieving a perfect 9/10 rating across all three test runs. It also showed impressive response length consistency, with outputs ranging only from 250 to 350 tokens. This stability suggests well-tuned infrastructure and configuration for the model they created.
Groq achieved mixed results with two 8.5 ratings and one 9, but maintained very consistent response lengths (286-300 tokens). One response experienced execution issues, requiring regeneration to obtain a valid result.
DeepInfra showed the largest response length variations, with ratings from 8 to 8.5 and response lengths varying dramatically from 240 to 1,000 tokens. One response included an extremely long regex pattern, though it functioned correctly.
Together exhibited response length consistency (280-400 tokens) but large rating variation, with ratings spanning from 8 to 9 across the three tests.
Chutes provided consistent response length but also a consistently lower rating of 8.5.
Speed and Infrastructure Analysis
Provider infrastructure differences became obvious when looking at the speed. Groq's specialized inference chips delivered exceptional speed for the Kimi K2 model.
| Provider | Speed (tokens/sec) based on writing task |
|---|---|
| Groq | 170-230 |
| DeepInfra | 60-73 |
| Together | 38-42 |
| Novita | 11 to 70 |
| Parasail | 9-12 |
| Moonshot AI | 10-10 |
Moonshot AI's slower speeds likely reflect their focus on quality and consistency rather than raw throughput. As the original model creator, they may prioritize careful inference over speed optimization.
Novita's unstable speed patterns (ranging from 11 to 70 tokens per second) suggest infrastructure scaling issues or inconsistent server allocation.
For more speed comparisons across providers, you can check out the stats from OpenRouter's Kimi K2 model page.
Provider Recommendations
Based on our evaluation results, provider selection should align with your specific priorities and use cases.
Writing tasks requiring highest quality:
- DeepInfra stands out despite using fp4 quantization. The provider consistently delivers longer, more comprehensive responses with ratings reaching perfect scores.
Applications prioritizing speed:
- Groq offers the best performance at roughly 170 tokens per second, though with somewhat shorter responses. This makes it suitable for interactive applications or rapid content generation.
Tasks requiring consistency:
- Moonshot AI provides the most reliable output quality and response length, though its slow speed might not be suitable for real-time applications.
Balanced performance:
- Together offers stable speed and reasonable quality across both tasks, providing a good middle ground for general-purpose applications.
Do also note the location that the model is hosted. For example, Moonshot AI is based in China, while Groq is based in the US. This might have implications for latency and compliance.
Comparison with Leading Models
The provider variations we identified demonstrate the importance of testing models across different hosting platforms. Different providers clearly have distinct output characteristics that can significantly impact your applications.
For a comprehensive comparison of Kimi K2 against leading models like Claude 4, GPT-4.1, Gemini 2.5 Pro and Grok 4 across all task domains, see our detailed evaluation of Kimi K2:
Evaluating Models with 16x Eval
These provider evaluations in this post were conducted using 16x Eval, a desktop application designed for systematic AI model evaluation and comparison.
16x Eval enables you to test multiple providers, compare response quality, and analyze performance metrics including speed and consistency.

Use 16x Eval to simplify the process of creating custom evaluations, running multiple tests, and comparing results across different providers and models.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.