Modern Large Language Models (LLMs) feature increasingly large context windows, with some models like Gemini 2.5 Pro capable of processing up to 1 million tokens.
While this seems like an advantage, simply filling the context window with as much information as possible is actually a bad practice. This creates context bloat, which can lead to worse performance and higher costs.
More recently, people began to call the practice of managing LLM context context engineering. Andrej Karpathy (ex-OpenAI researcher) calls it "the delicate art and science of filling the context window with just the right information."

Performance Degrades with More Context
It is important to understand that as the context window grows, the model's performance starts to degrade.
A study on long-context evaluation called NoLiMa found that for many popular LLMs, "performance degrades significantly as context length increases." The NoLiMa benchmark showed that at 32k tokens, 11 out of 12 tested models dropped below 50% of their performance in short contexts.
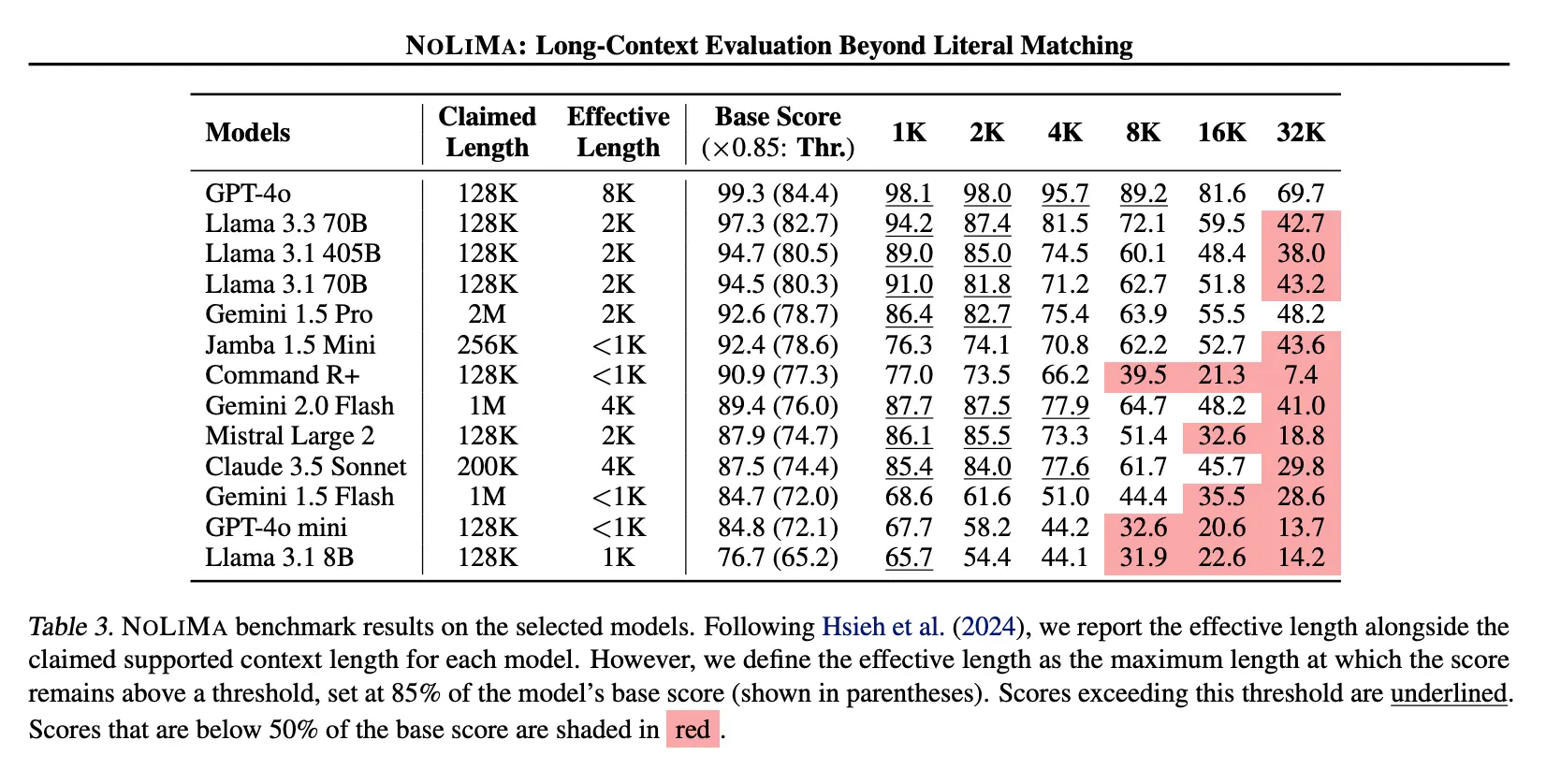
This happens because the attention mechanism can struggle to find the most relevant information within a sea of text.
More recent results from the Fiction.liveBench benchmark also show this trend. As context size grows, even top models see a drop in their ability to recall and reason about the information provided.
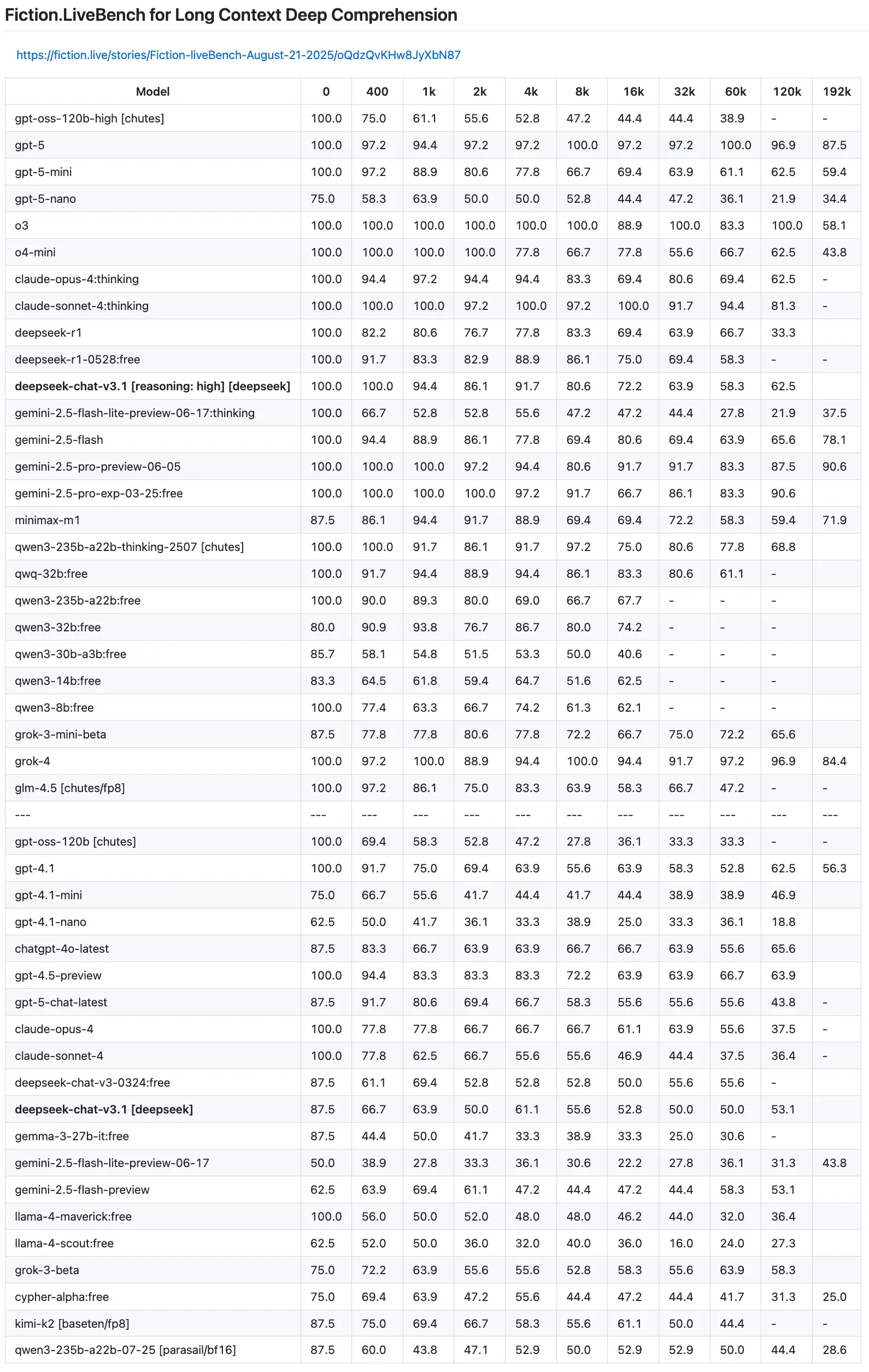
Here's an excerpt from the results from Fiction.liveBench on popular new models:
| Model | Performance at 8k | Performance at 32k | Performance at 120k | Performance at 192k |
|---|---|---|---|---|
| Gemini 2.5 Pro | 80.6 | 91.7 | 87.5 | 90.6 |
| GPT-5 | 100.0 | 97.2 | 96.9 | 87.5 |
| DeepSeek v3.1 (Thinking) | 80.6 | 63.9 | 62.5 | - |
| Claude Sonnet 4 (Thinking) | 97.2 | 91.7 | 81.3 | - |
Some models like Gemini 2.5 Pro and GPT-5 are able to maintain good performance at 192k tokens, while other models like DeepSeek V3.1 and Sonnet 4 (thinking) see their performance drop at 120k tokens.
For the best results, you should aim to operate within a model's effective context length, which is the point before its performance starts to drop significantly. For new top models like Gemini 2.5 Pro and GPT-5, this is around 200k tokens. For Claude Sonnet 4 (Thinking), this is around 60k to 120k tokens before the performance drops.
We expect the performance degradation to become less of a problem with the release of newer models. Nonetheless, it is still important to manage context effectively to get the best performance now, especially if you are using a model with a shorter effective context length like Claude Sonnet 4.
The Increasing Cost of Large Context
Besides performance issues, overloading the context also increases costs. LLMs are stateless, which means they do not have memory of past conversations. For every message you send, the entire conversation history must be sent back to the model.
Here's an nice illustration by OpenAI of how the context window grows with each turn in a conversation:
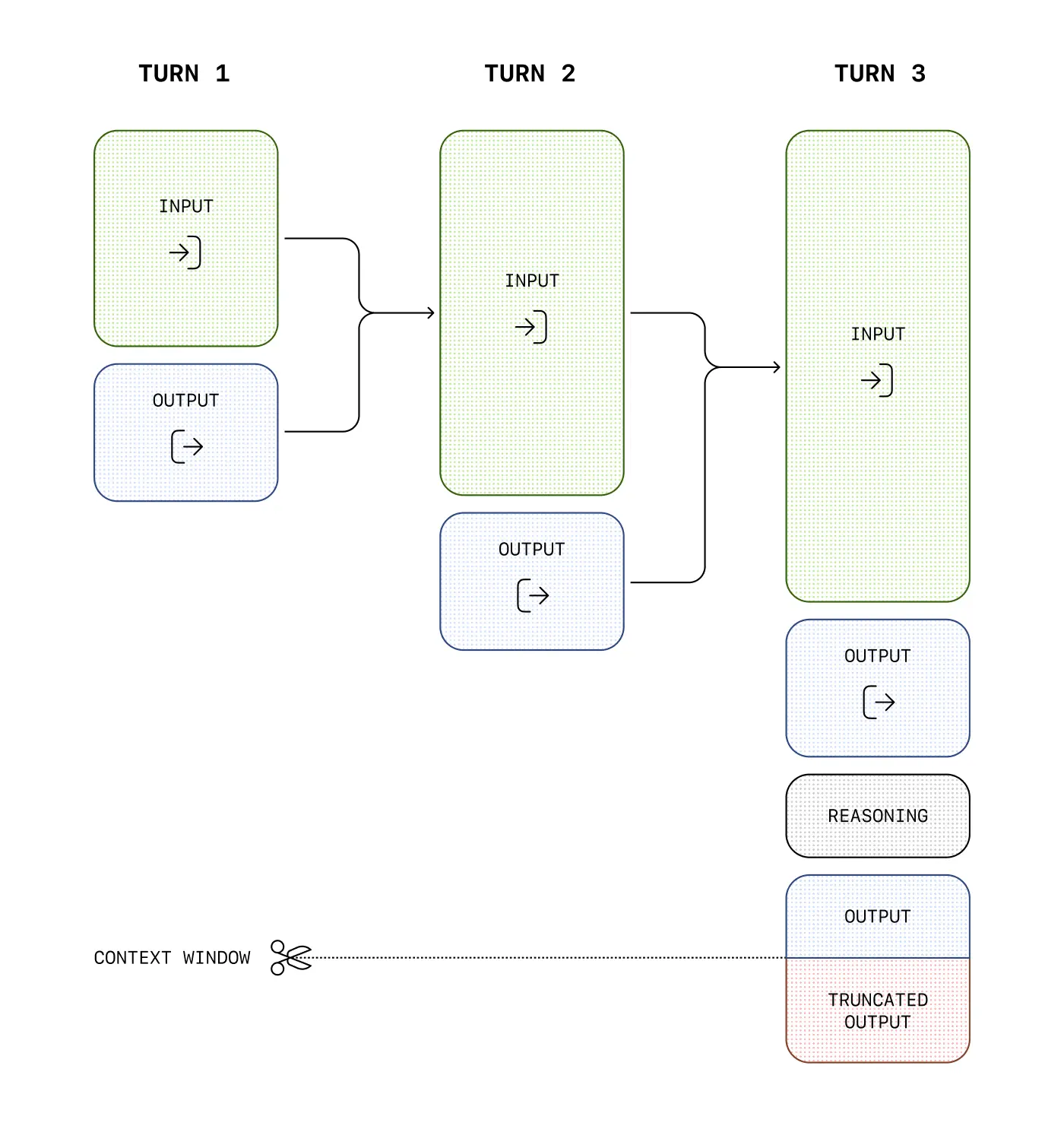
As the conversation gets longer, the number of tokens sent as input to the model grows for each new message within in the same session.
Since API usage is priced per token, longer contexts directly translate to higher costs. Keeping the context concise and relevant is therefore not just good for performance, but also for your budget.
If you need to have long context or long conversations, look out for providers that support input token caching (context caching), the cost of long context can be significantly reduced with caching at lower price for input tokens.
What Causes Context Bloat
Context can get filled up for several reasons, often without the user realizing it. For coding tasks, one common cause for context bloat is including irrelevant rules or instructions. Including instructions for a backend task when working on the frontend can confuse the model, as explained by a developer from Cline.
Having too many tools from MCP servers can also quickly increase context size, because the definitions of the tools inside the MCP servers need to be included in the context before any user prompt. For example, the popular MCP server Playwright contains 21 tools, each with its own definition and instructions.
With the help of newly released /context command in Claude Code, we can see that a single Playwright MCP server can consume over 11.7k tokens, while the built-in tools consume 11.6k tokens. This information is included in every message, whether you use the tools or not.
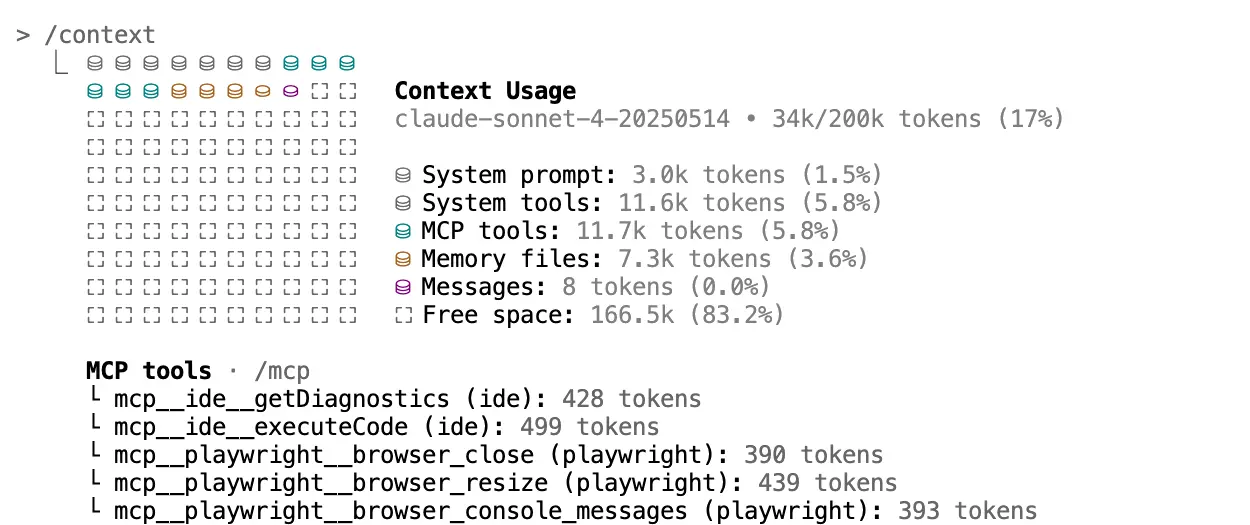
Another simple cause of context bloat is reusing the same chat session for multiple, unrelated tasks. This clutters the conversation history with irrelevant information from previous tasks. The model must then sift through this old context, which can negatively affect its focus on the current problem.
How to Manage Context Effectively
The key to managing context is understanding what is in it. In tools like Claude Code, you can use the /context command to see a breakdown of your current token usage of the context window.
If you see memory files taking up too many tokens, consider removing irrelevant rules from your CLAUDE.md or AGENTS.md file. Keep it concise and relevant.
Some tools like Claude Code supports directory-level rules or memory files. For example, if your repository has frontend code inside frontend directory, you can place CLAUDE.md specific for frontend tasks in a frontend directory. This will only be loaded when the model is working on frontend tasks in that directory.
If you see tools from MCP servers taking up too many tokens, be selective about which MCP servers you enable. If a MCP server is not needed for your current task, consider disabling it to free up context space.
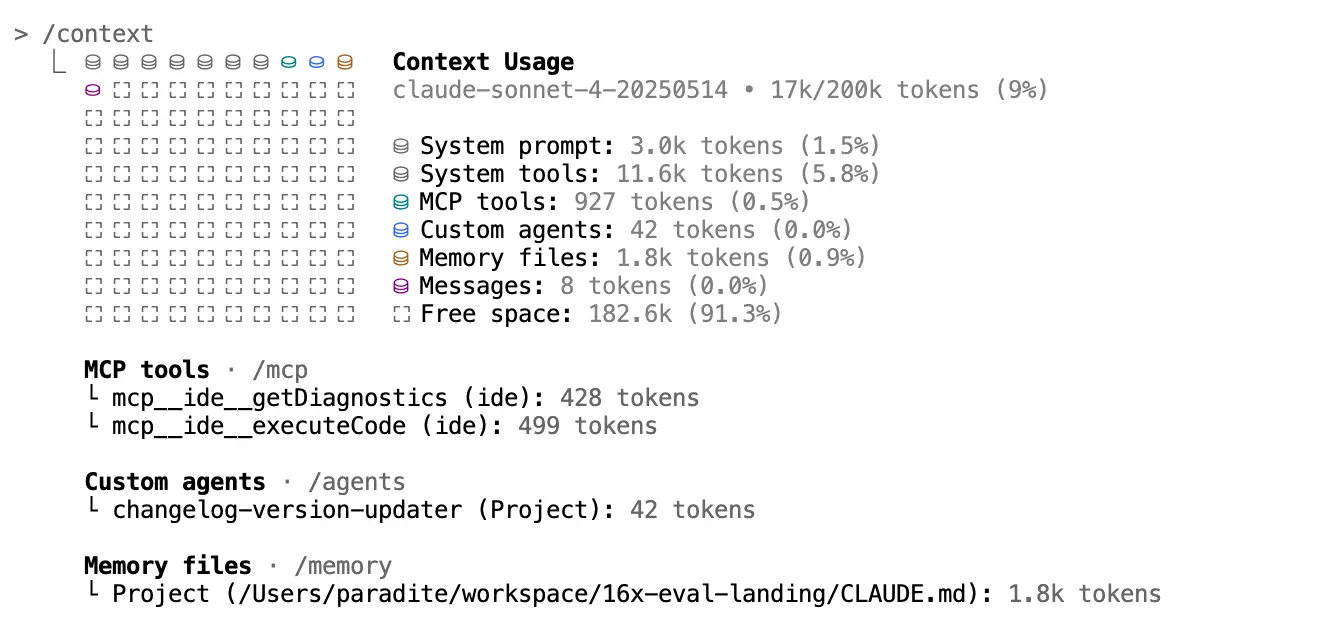
Another important tip is to start a new session for each new task, clearing the current context window. This ensures the context contains only relevant information, preventing the model from getting confused by previous, unrelated conversations.
16x Eval is a desktop app designed to help AI product builders run systematic evaluations of LLMs. You can use it to test how different models perform with different prompts, or varying context lengths.

This allows you to understand a model's effective context length and refine your context engineering strategy for your specific needs.