In our previous evaluation of GPT-5, we tested the model using its default medium reasoning effort and found its performance underwhelming.
The community response suggested that GPT-5's true strength is unlocked with high reasoning effort. This feedback prompted us to conduct a new evaluation to see if the reasoning effort setting makes a difference.
Evaluation Setup and Methodology
We re-ran our full coding evaluation suite of seven tasks, this time setting GPT-5's reasoning effort to "high". The methodology remained the same:
- For standard tasks, we gave each model one attempt. For tasks with high variance in output and ratings, we gave each model two attempts and picked the higher rating.
- We used default settings for other parameters like temperature and verbosity.
- We had a human evaluator assign ratings based on our evaluation rubrics.
- We livestreamed the entire evaluation process.
High Reasoning Boosts Overall Performance
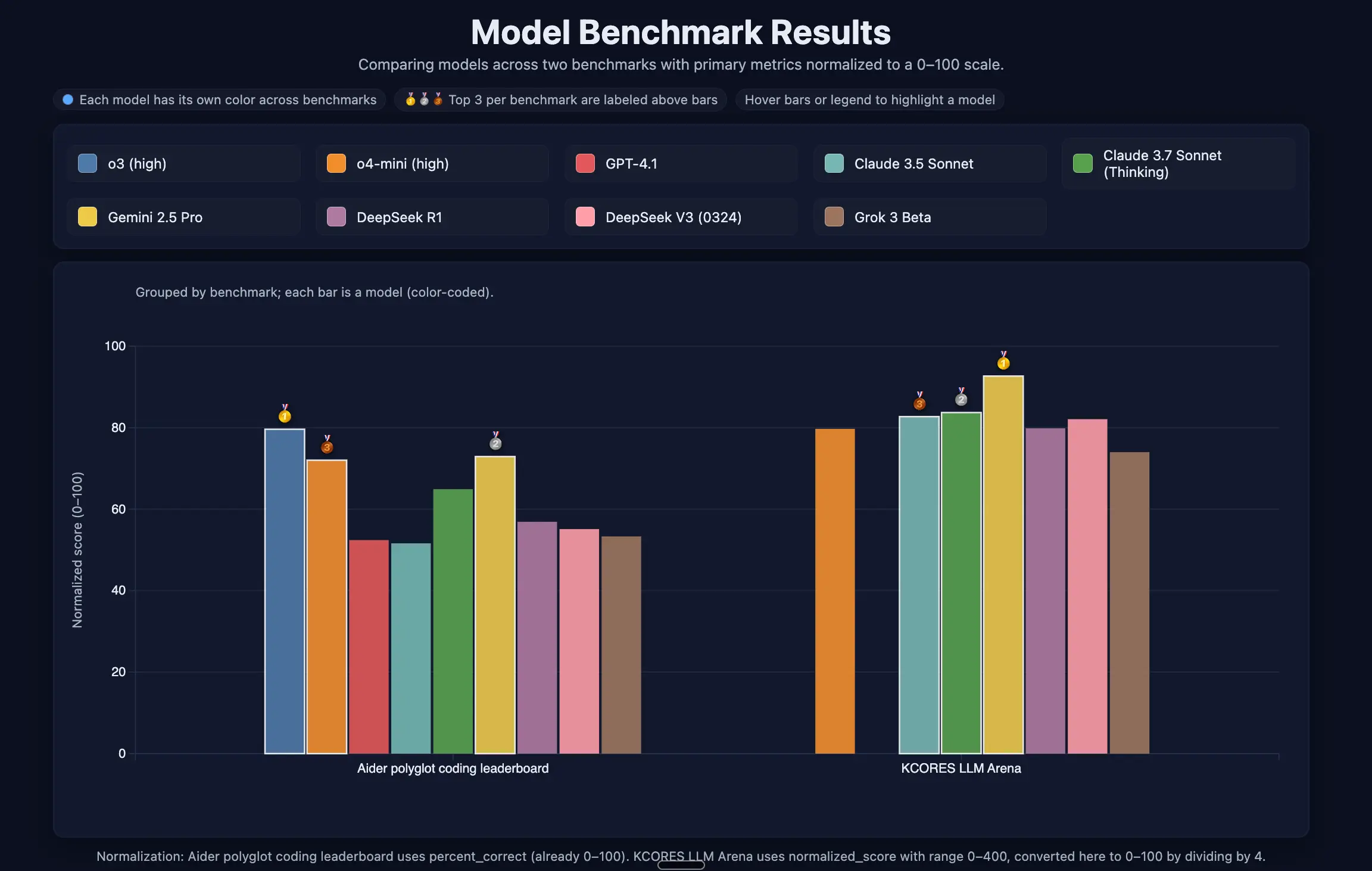
With high reasoning effort, GPT-5's average coding rating jumped from 7.71 to 8.86. This substantial improvement places it just behind Claude Opus 4 and makes GPT-5 (High) the second-best model in our evaluation. It now clearly outperforms other top models, including Claude Sonnet 4 and Grok 4.
Average Rating for Coding Tasks: GPT-5 (High) vs Top Models
The community was right. High reasoning effort was the key to unlocking GPT-5's true strength. This setting allows the model to "think" more before generating a response, leading to more accurate and capable solutions.
However, this performance boost comes at a cost. During the evaluation, we observed that GPT-5 with high reasoning is significantly slower when it comes to getting the final response. Tasks often took several minutes to complete due to the large number of reasoning tokens generated.
Where High Reasoning Excels
The most significant improvements appeared in the most difficult tasks. High reasoning effort enabled GPT-5 to solve complex problems that its medium-reasoning counterpart completely failed on.
The TypeScript narrowing task was the clearest example of this leap. The medium reasoning version of GPT-5 scored 1 out of 10, failing to produce a working solution. In contrast, GPT-5 with high reasoning scored 8.5 out of 10 by providing two working solutions, tying with Claude Opus 4 for the top spot on this challenging task.
TypeScript narrowing (Uncommon) Performance Comparison
GPT-5 (High) also showed impressive creativity on the benchmark visualization task. It scored 9.25, a notable increase from 8.5 achieved by the medium version. It produced an interactive chart with a hover effect that highlights model performance across benchmarks, a feature no other model has generated.
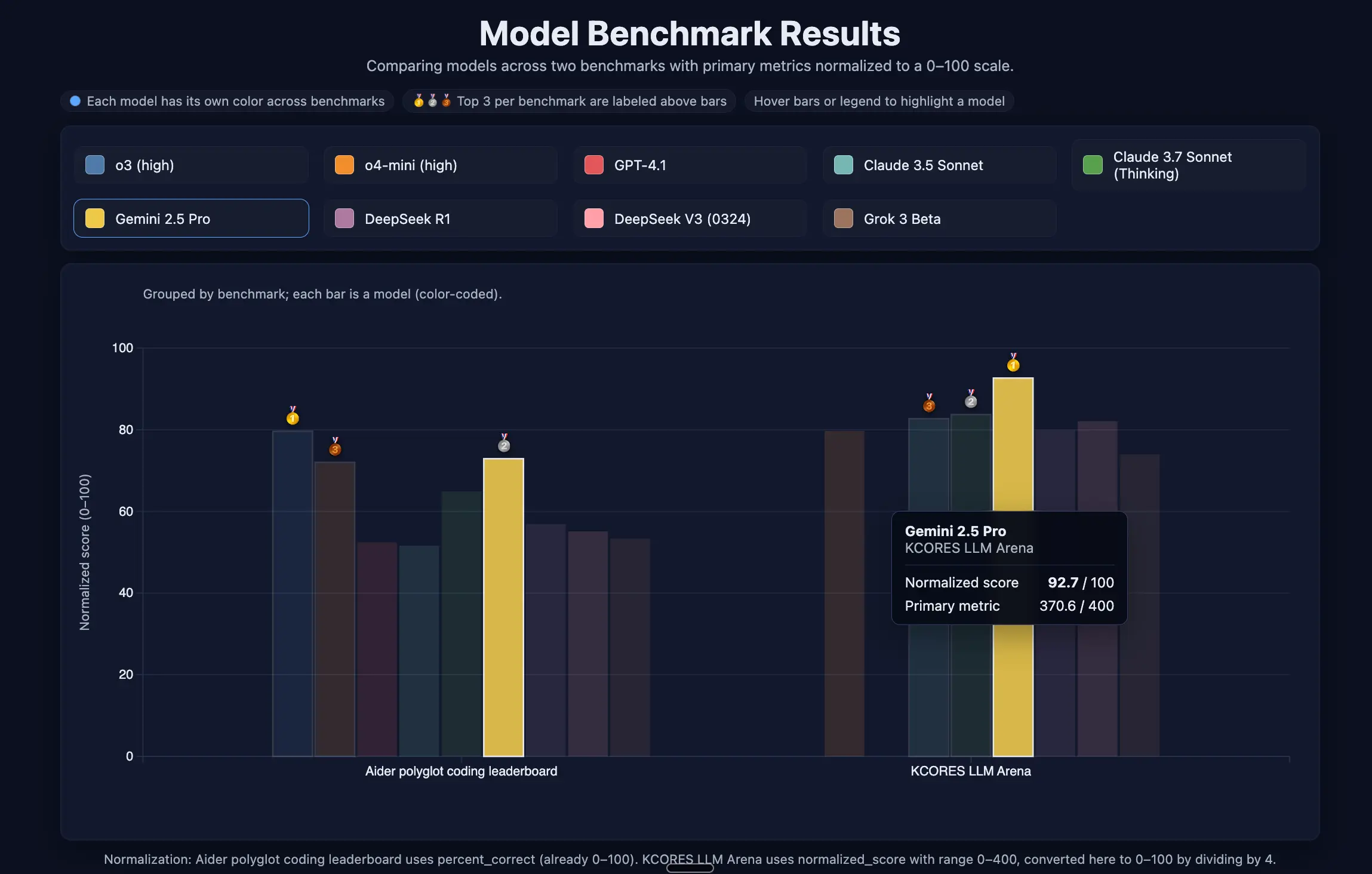
Not a Universal Improvement
While high reasoning delivered significant gains on difficult tasks, it was not a universal fix. On some tasks, the performance was either the same or slightly worse, suggesting that more "thinking" does not always lead to a better outcome.
For the difficult Clean MDX task, both versions of GPT-5 scored 8 out of 10. The high reasoning version's first attempt produced an output with three newline issues and a leftover component. Its second attempt was even worse, removing text incorrectly and scoring only 7.5.
Clean MDX (Difficult) Performance Comparison
On the Folder watcher fix task, the high reasoning version scored slightly lower than the medium version (8.5 vs. 8.75). Both versions produced verbose code, but the high reasoning version also missed implementing helpful extra logic that the medium version included. This shows that increased reasoning does not guarantee better adherence to conciseness or completeness.
Folder watcher fix (Normal) Performance Comparison
The Trade-Offs: Speed and Token Consumption
The improved performance of high reasoning comes with significant trade-offs in speed and token usage. We observed that response times were consistently long. The Clean markdown task, for example, took more than four minutes to complete, a stark contrast with Claude Opus 4, which returned the result in just 14 seconds.
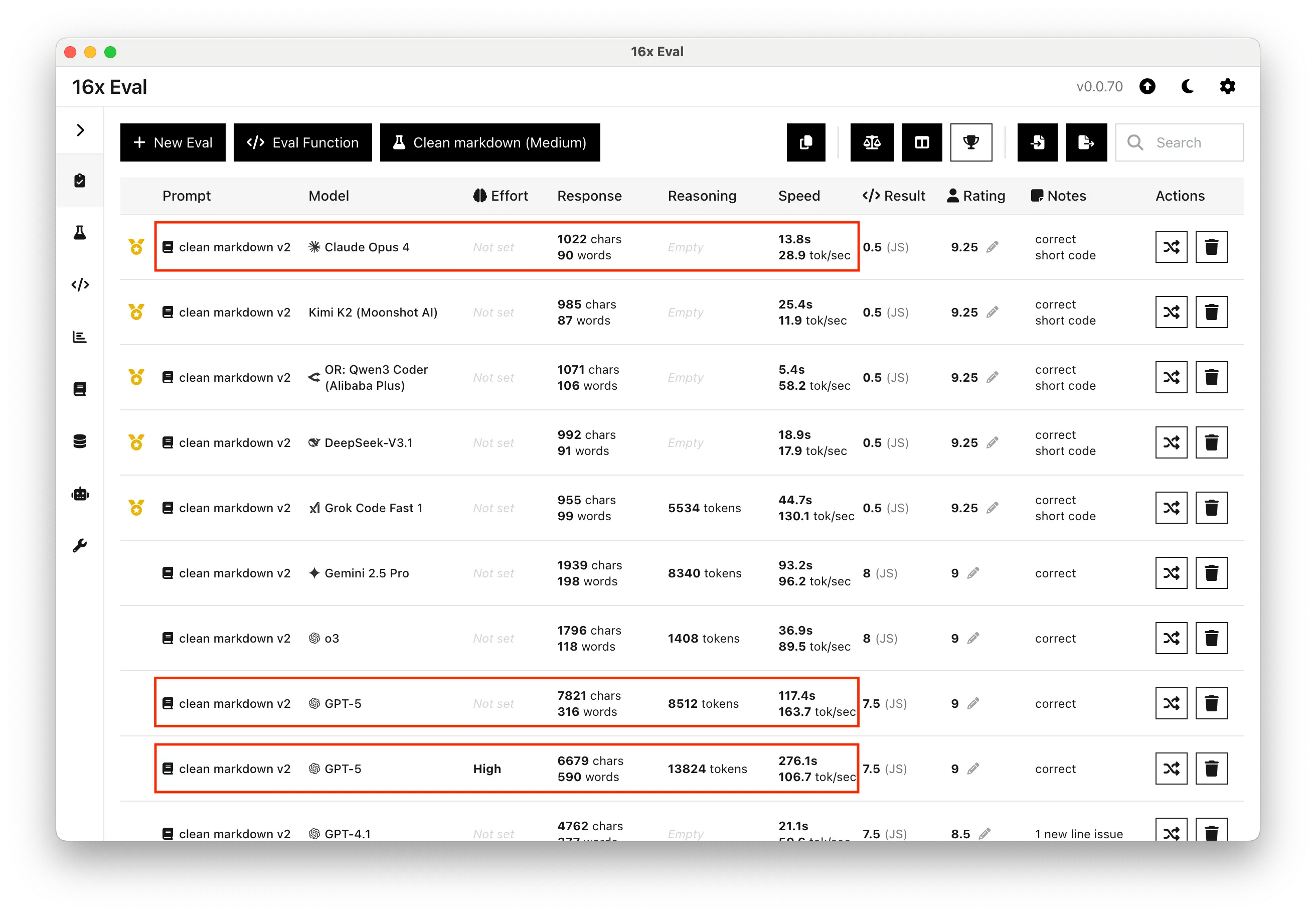
This slowness is due to the large number of reasoning tokens generated. For the Clean markdown task, GPT-5 (High) used over 13,000 reasoning tokens, compared to around 8,500 for the medium version. While these tokens are not part of the final output, they contribute to the long wait times and potentially higher costs, which developers should consider for practical applications.
Overall Recommendation
GPT-5 with high reasoning is much more capable than its medium setting. It demonstrates strong problem-solving skills, particularly for complex and non-standard coding challenges.
However, the significant increase in response time makes it less practical for all situations. The high reasoning setting is best reserved for difficult problems where accuracy and deep understanding are critical. For simpler or more routine coding tasks, the default medium setting offers a better balance of performance and speed.
This evaluation was conducted using 16x Eval, a desktop application for systematic AI model evaluation. It allows you to run structured tests across different models and settings, just as we did here to compare GPT-5's reasoning efforts.

With 16x Eval, you can easily analyze performance on your own custom tasks to find the best model for your needs.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.