Large Language Models (LLMs) are everywhere now, helping you write, code, and answer questions. But if you ask an LLM a simple question like "What model are you?", you're likely to get the wrong answer. It might claim to be a different model, give the wrong version number, or even say it's created by the wrong company.
In this post, we take a look at why this happens, what it tells us about how LLMs work, and how providers patch around it.
LLMs Frequently Get Their Own Name Wrong
Ask an LLM its own name, and the results can be confusing. When GPT-4 first launched, it claimed to be GPT-3. Open-source models like DeepSeek R1 can claim that they are GPT-4 by OpenAI.
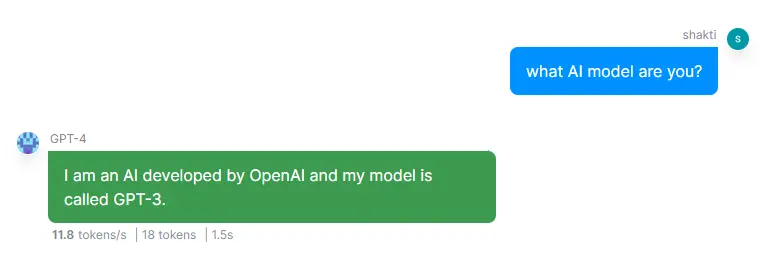
This is not a rare bug. Users regularly encounter LLMs making up names, mixing up their creators, or simply responding with generic phrases like "I'm a helpful AI assistant from OpenAI," even when they are not. Such mistakes might be surprising for people expecting an AI to have at least a basic sense of self.
Why is this happening? To answer that, we need to look at how LLMs are trained.
Why LLMs Lack Self-Awareness
LLMs are trained on massive amounts of data from websites, books, and articles, but that data doesn't usually include the model's own identity. Importantly, the final name and version (like "Claude Sonnet 4" or "GPT-4o") are assigned after the training process finishes.

The easiest way to think about this is with an analogy: Imagine feeding knowledge from the entirety of human knowledge to a baby for years, but never telling the baby its name. When the baby learns to speak, it will know a lot, but it won't know what it's called unless you keep telling it over and over.
Since the finished LLM never "learned" its own name during training, it can only guess when asked to identify itself. This problem is compounded by training data contamination, where the dataset includes conversations about other models or even synthetic data generated by them. If there are enough mentions of GPT-4 inside the training data, the model will likely say it's GPT-4. That's why the answers are unreliable, or sometimes hilariously wrong.
The Workaround: Providing Identity via System Prompt
To help LLMs identify themselves, providers include the model name (and sometimes the creator) in a system prompt*. This system prompt is a special instruction, sent alongside each user query.
For example, in public system prompts published by Anthropic, we can see that they start with the line "The assistant is Claude, created by Anthropic."

Yet, this solution has its limitations. If a third-party app changes the system prompt, or if a developer uses an API without sending any such prompt, the model just doesn't know its own name at all.
For example, OpenRouter, a model routing and aggregation service, ran into this issue. Many users reported models giving confused or default answers about their identity. The OpenRouter team had to add a default system message to every request, restoring basic "self-knowledge" for their hosted models.
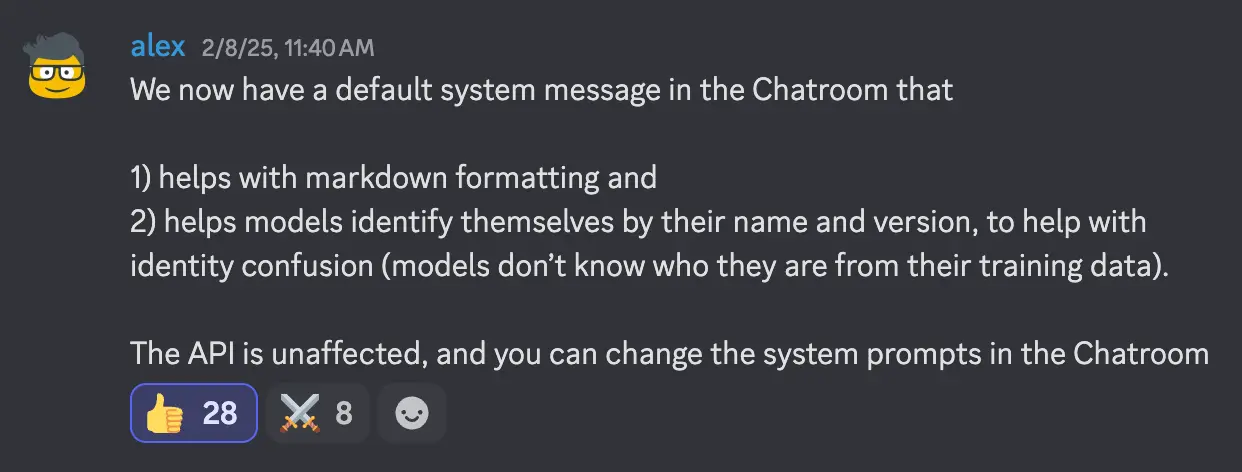
So if you've ever been curious why your LLM seems to suddenly forget or change its name in different apps, it's likely due to the system prompt being changed.
LLMs Can't Know Their Training Cutoff Either
A related behavior is that LLMs also give the wrong date for their knowledge cutoff, the most recent date their training data covers. You might get answers like "I know about events up to 2024" when the real cutoff is 2025.
This is similar to the identity problem. The cutoff date isn't a fact present within the training data. Instead, it is metadata about when the last update occurred, decided by the people who trained the model.
Like identity information, knowledge about training cutoffs must be provided through system prompts in order to be reliable.
Why Does This Matter?
In conclusion, LLMs only "know" their own identity or knowledge cutoff if you (or the backend app) tell them directly through a system prompt. This is because their name is assigned after training, not learned from it, making their self-identification a configured response rather than true awareness. If the system prompt omits or rewrites this information, the LLM's answers will become unreliable.
This has clear implications for both developers and users:
For AI app builders, be aware that changing the default system prompt may cause the model to "lose" its identity and confuse your users.
For AI app users, this knowledge explains why an AI might seem to have an identity crisis. It is not a bug, but rather a predictable outcome of how these systems are designed. Understanding this helps everyone interpret an AI's claims about itself with the right perspective.
For developers and power users who need to tune system prompts and ensure consistent model output, robust testing is essential. Tools like 16x Eval can help you systematically test how different models respond to prompts, allowing you to understand and optimize your prompts and model usage for your specific use cases.

If you care about reliability and accurate AI behavior, try the 16x Eval app and build your own evals.
*: New OpenAI open-source model gpt-oss-120b has a new model_identity field, which is used to tell the model its name. Both system prompt and developer prompt are being treated as developer prompt in this new model.