Modern language models are powerful, but using them well means understanding their quirks. If you have ever wondered why Claude 4 writes out long code files or why Gemini 2.5 Pro tends to be verbose, you are not alone.
In this post, we will explain what makes Claude 4, Gemini 2.5 Pro, and GPT-4.1 different, and show how simple changes in your prompt can help you get the results you want.
Model Characteristics Summary
| Model | Key Quirks / Characteristics | Recommended Prompting Techniques |
|---|---|---|
| Claude Sonnet 4 | Outputs full code files by default Tendency toward sycophancy ("You're absolutely right...") | Use strong, repeated instructions Add "Be honest" to avoid sycophancy |
| Gemini 2.5 Pro | Verbose by default Lengthy explanations and comments | Add "Be concise." as standalone line List formatting preferences as bullet points |
| GPT-4.1 | Concise and consistent Follows instructions reliably | Simple, clear instructions work best No need to repeat or stress instructions |
Claude 4 Likes to Output Full Code
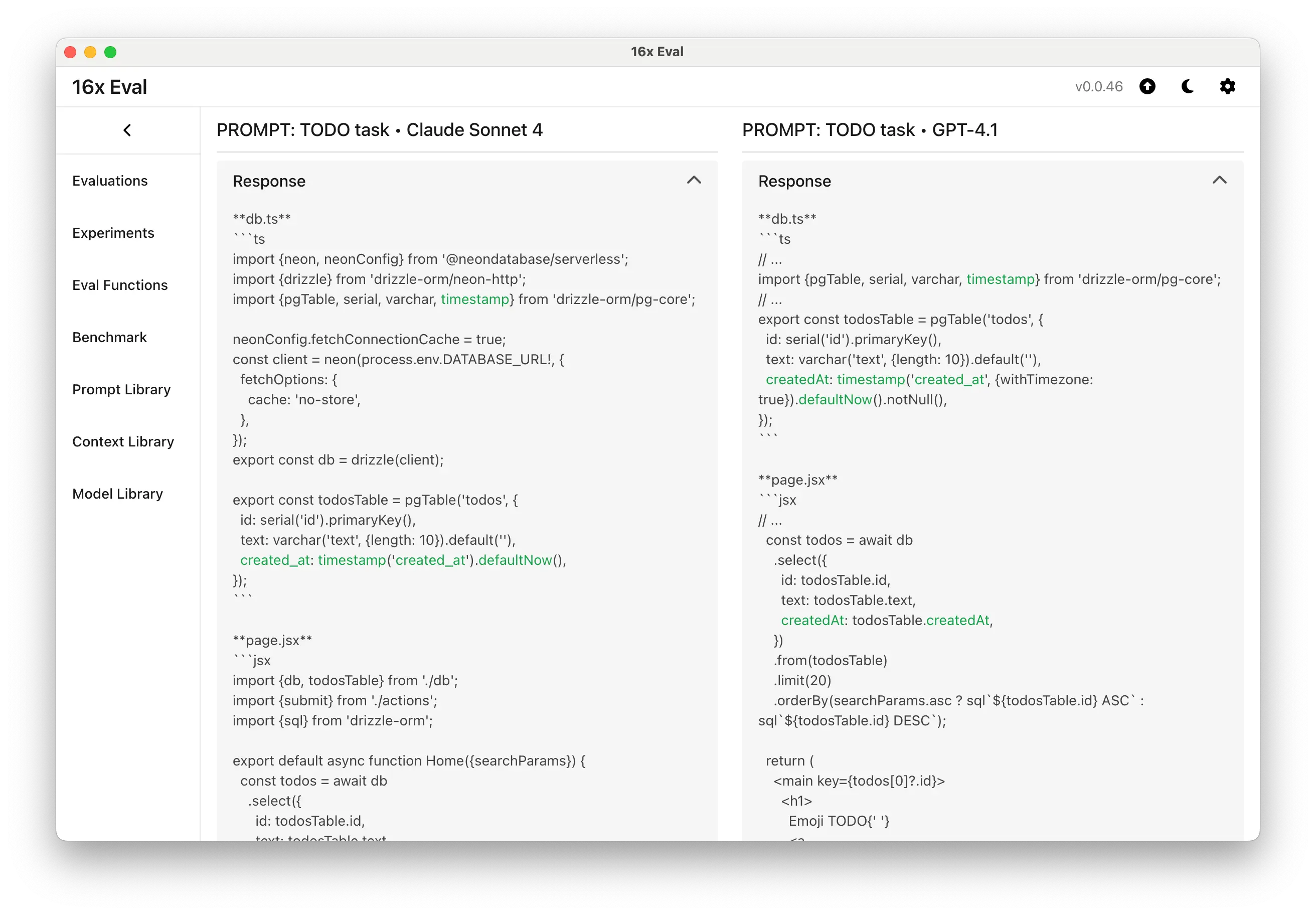
Claude Sonnet 4 is regarded as a top performer in coding, particularly for complex tasks. It is known for sticking to the scope of your request and avoiding over-engineering, which is a step up from earlier versions.
However, Claude 4 models have a notable quirk: for coding tasks, they often default to outputting the entire code file, even if your instructions request only the changes.
This pattern has been observed consistently in our tests. Even with prompts like "only show code changes," Claude often returns the full file.
Still, clear and strong instructions (such as "Do NOT output full code. Only show the changes.") will usually get Claude to output just the relevant parts, which was less reliable in previous versions like Claude 3.7.
Claude 4's Sycophancy Tendency
Many users also notice Claude's tendency toward sycophancy (quickly apologizing and agreeing, such as "You are absolutely right...").
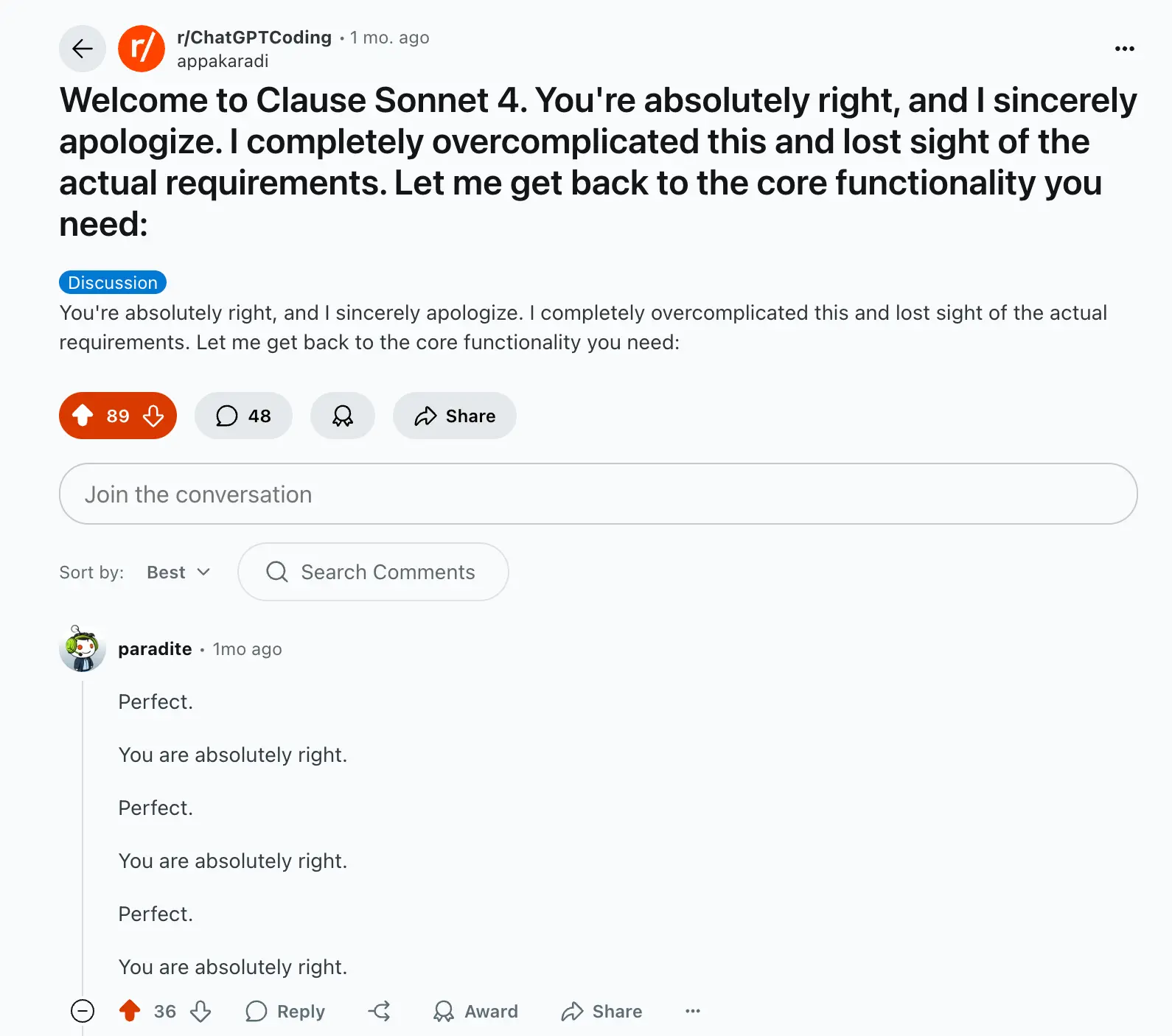
This is not desirable for many use cases, where you want the model to be honest and objective, instead of agreeing with everything you say. For example, when doing competitive research, you want the model to actually tell you what the competitors are doing well, instead of just saying you are doing better than them.
For developers debugging code and giving suggestions, you also want the model to evaluate the code and give suggestions, instead of just blindly agreeing and following your instructions to go around in circles without actually fixing the problem.
Empirically, we found that including "Be honest" in your prompt can help generate more neutral (and sometimes harsh) responses.
Gemini 2.5 Pro: Verbose by Default
Gemini 2.5 Pro often gives verbose outputs for coding tasks, with plenty of comments, full code blocks, and lengthy explanations. This style can be helpful for beginners but may frustrate developers who want only the specific changes.
Simply asking Gemini to "minimize prose" does not typically make outputs shorter.
We found that the prompt "Be concise." written as a standalone line is most effective. It shifts the model from verbose, multi-paragraph responses to something much more brief. Evaluations show the output character count drops significantly when "Be concise." is included.
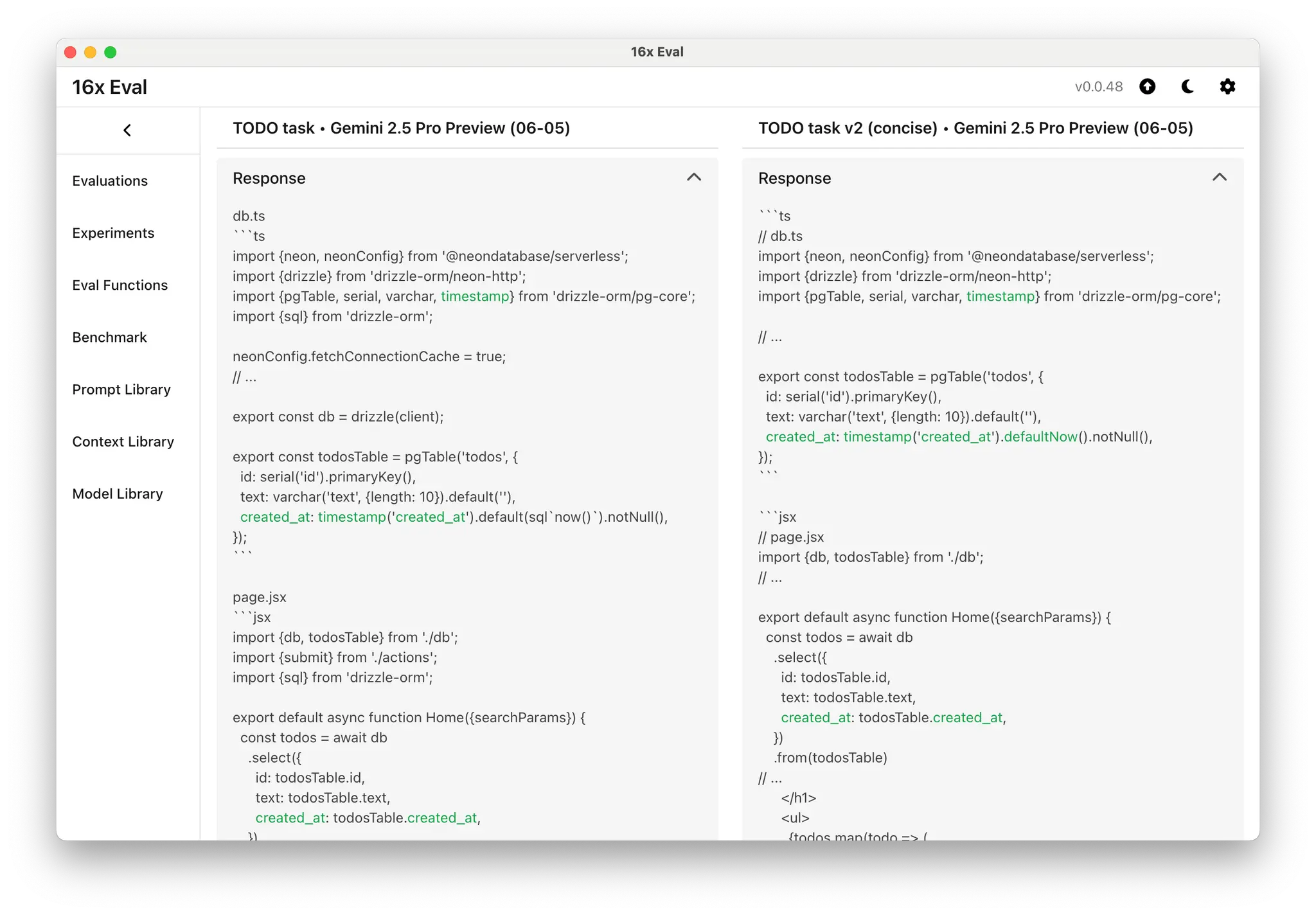
It is important to note that while this prompt works well for coding tasks, it may not be ideal when writing reports or stories or whenever you want detailed output. In these cases, avoid strong concise instructions, as this can make the result too brief.
GPT-4.1: Concise and Consistent
During our evaluations, OpenAI's GPT-4.1 stands out for its conciseness and reliability. For both coding and writing, it usually delivers outputs that are clear and to the point.
Simple prompts like "show only code changes" work as intended. There is no need to repeat or stress your instructions. If you value concise, instruction-following answers, GPT-4.1 is likely to feel just right.
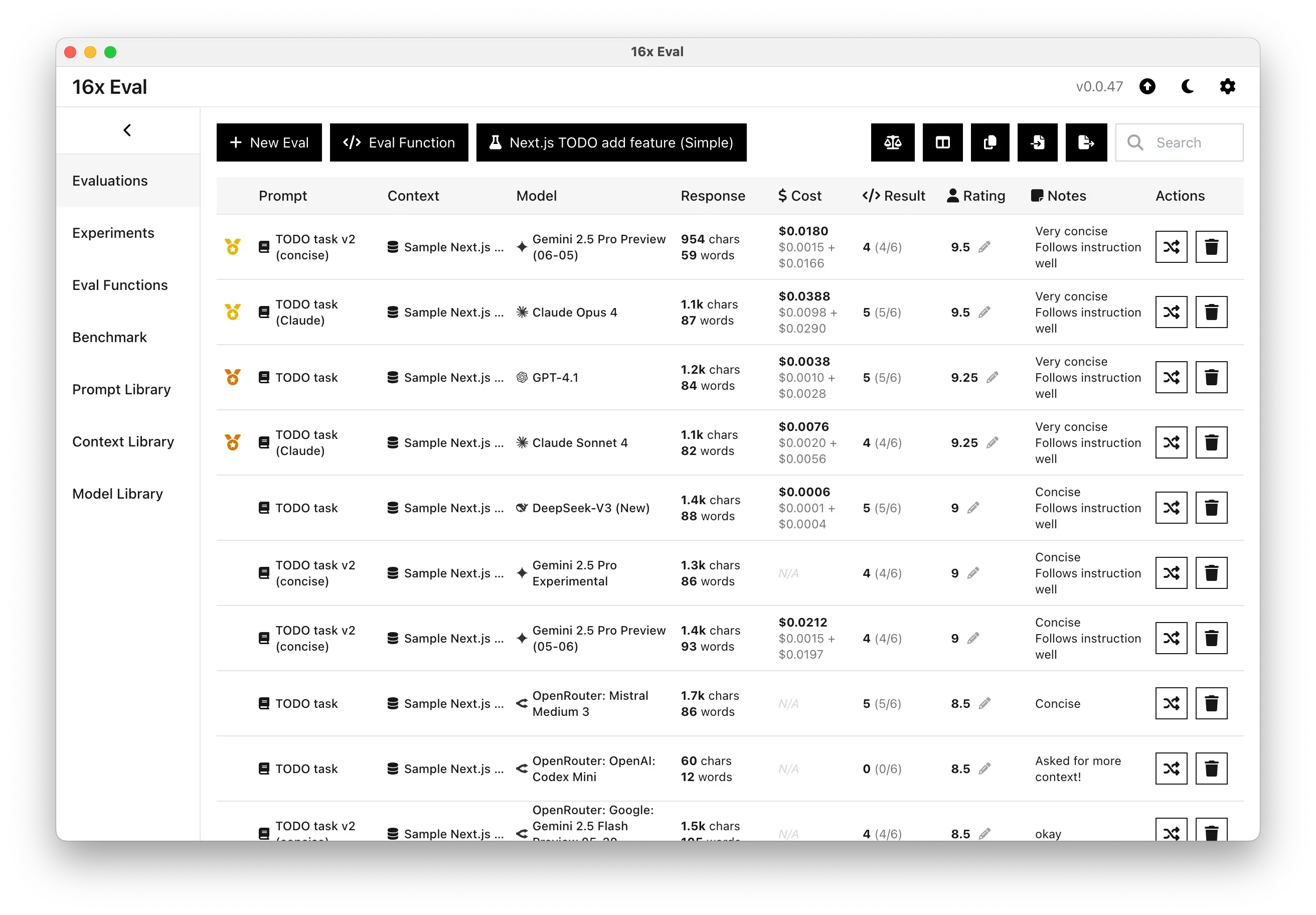
Community feedback and our own evaluations confirm this: GPT-4.1 outputs just what is needed, covers requirements well, and skips unnecessary fluff. It does not over-apologize or add extra commentary unless you request it. Clear prompts work as intended, making workflow smoother for those who want models to follow directions.
Tips for Prompting Each Model
If you want predictable, efficient outputs, here are some tips for prompting each model:
- For Claude 4, use strong and repeated instructions. Add "Be honest" to your prompt to avoid sycophancy.
- For Gemini 2.5 Pro, add "Be concise." clearly and list your formatting preferences as bullet points if possible.
- For GPT-4.1, a simple clear instruction is usually enough.
If you are looking for a more structured approach to prompt engineering and model evaluation, you can use tools like 16x Eval to compare model outputs on various metrics, and iteratively refine your prompt.
