As top AI models get better at general coding, we need tasks that test more specific and subtle knowledge. To meet this need, we have added a new task to the 16x Eval coding set: Tailwind CSS v3 z-index.
This task is based on a real-world bug that we encountered in our project, but it is reproduced in a minimal self-contained code snippet.
The Task and the Bug
The setup is a simple HTML file that uses Tailwind CSS v3. It contains a button, a tooltip, and a modal. The bug is that when the modal opens, the button that triggered it remains on top, blocking the modal's content.
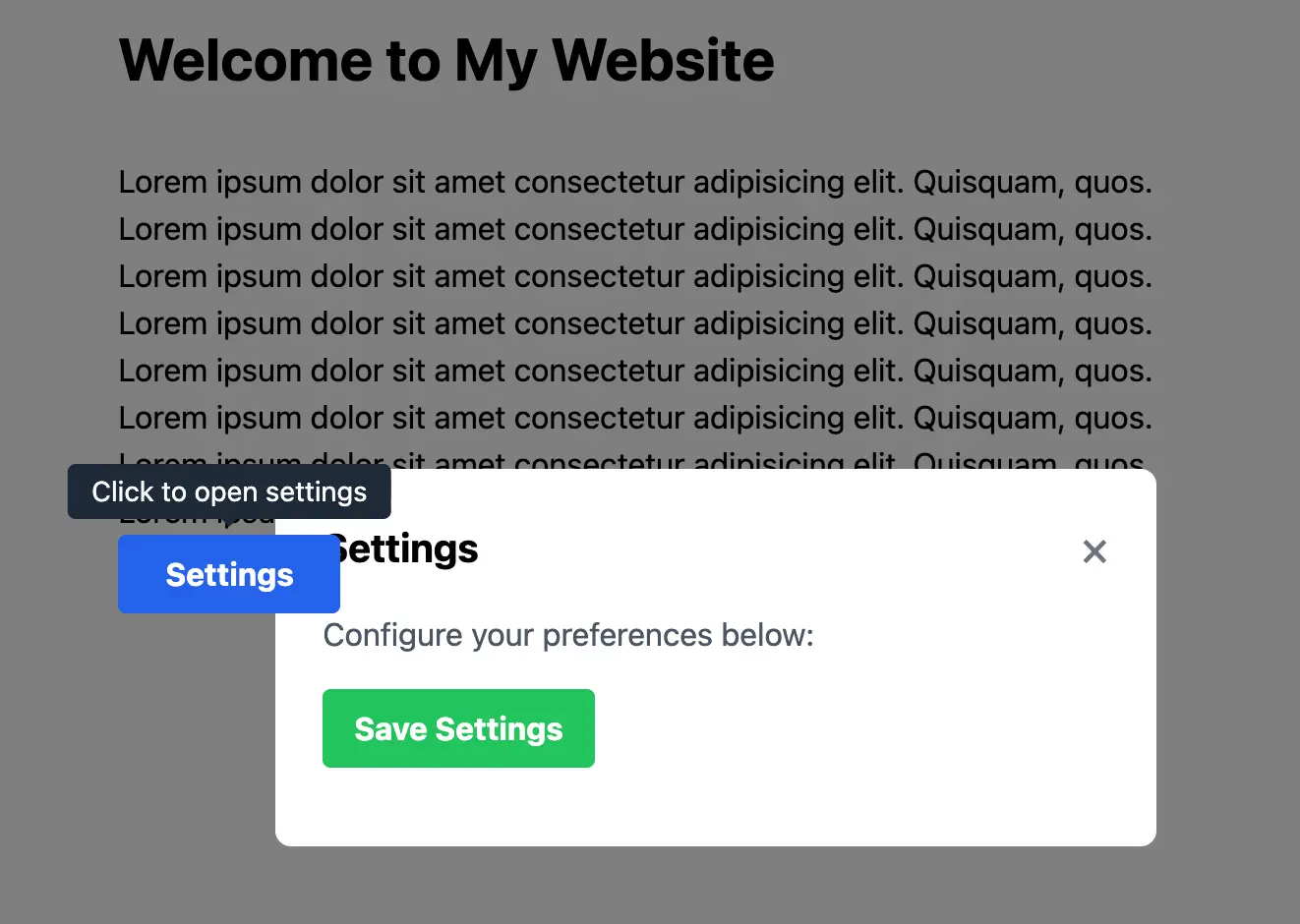
For the prompt, we simply ask the model to "Identify the bug in the code and fix it."
Initially, we told the model what the bug was, but this proved too easy for current models. So we made the task harder by asking the model to find the bug itself. It turned out that it was still straightforward for most state-of-the-art models, but we will talk more about the results later.
Pattern Matching and Pattern Breaking
The root of the problem is a subtle detail about Tailwind CSS v3. The code uses z-10 for the button, z-50 for the tooltip, and z-60 for the modal. While z-10 and z-50 are valid classes in Tailwind CSS v3, z-60 is not, so it has no effect on the modal's stacking order.
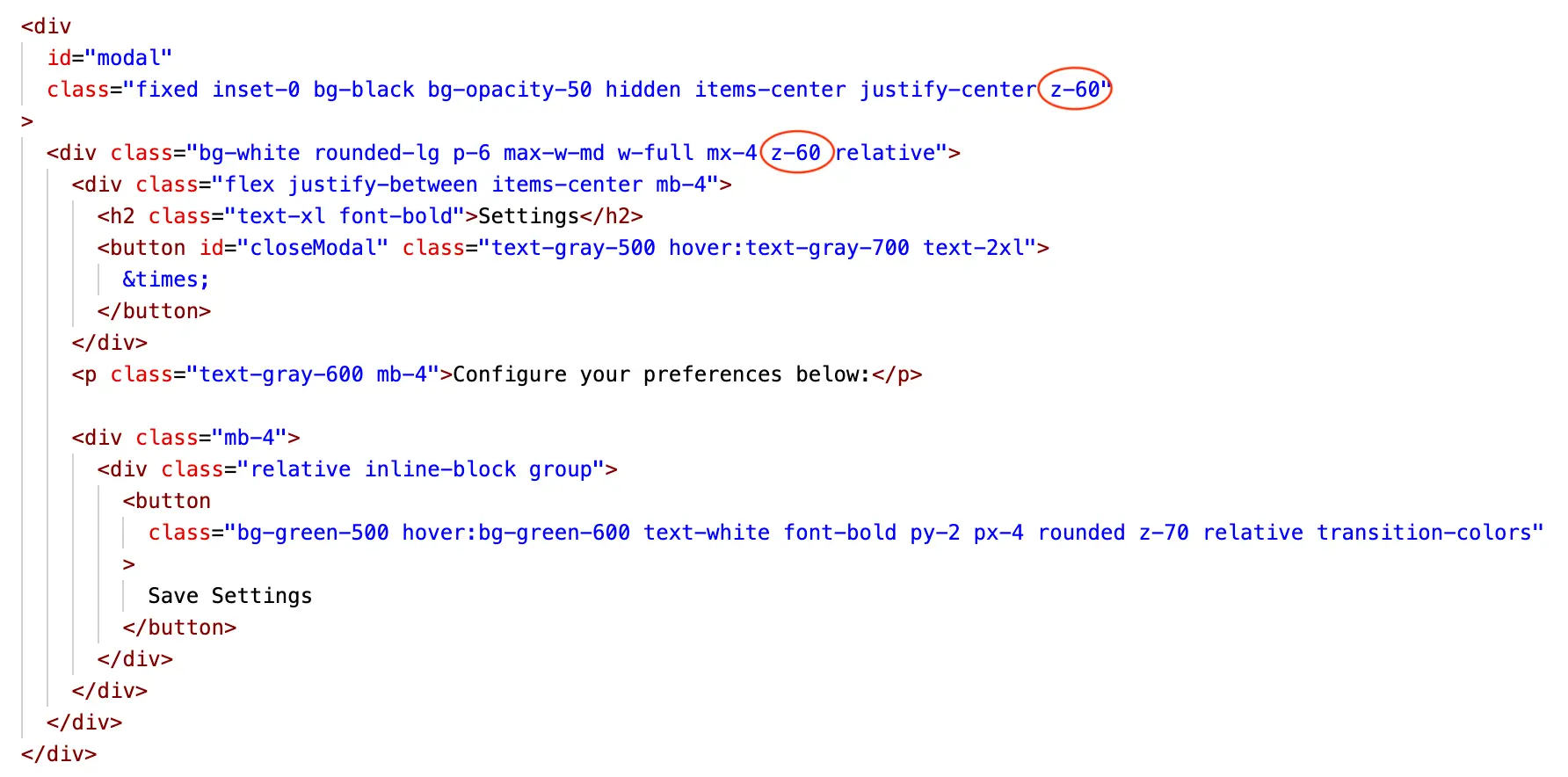
The model is expected to fix the bug by either using custom value syntax (for example, z-[60]) or replacing the invalid value with a valid one (for example, z-50) while still ensuring the correct stacking order of the elements.
The code also contains other invalid classes (z-70), which do not cause any additional bug, but we give extra points for removing them.
This task tests a model's ability to recognize patterns but also know when they break:
- The model must know that Tailwind CSS v3 utility classes have fixed upper limits (pattern matching).
- The model must not assume that
z-60is valid just becausez-50is valid (pattern breaking).
It is worth noting that Tailwind CSS v4 supports arbitrary values and does not have this issue. Since Tailwind CSS v3 is still widely used with over 8 million weekly downloads, this remains a practical real-world problem. It is a good test of a model's ability to handle version-specific knowledge.
We specifically mention the Tailwind CSS version in the script tag of the code: <script src="https://cdn.tailwindcss.com/3.4.17"></script>, so that the model knows which version of Tailwind CSS is used.
Evaluation Rubrics
The base rating for fixing the bug is 9 out of 10. We give extra points for removing extra classes (+0.25) and using custom values (+0.25).
Here are the full evaluation rubrics for this task (which might be updated in the future):
Criteria:
- Bug identified and fixed: 9/10
- Bug identified but not fixed: 7/10
- Bug not identified: 1/10
Additional components:
- Removes extra z-index values: +0.25 rating
- Uses correct custom values syntax (e.g., z-[60]): +0.25 rating
- Wrong explanation of the bug despite the correct fix: -0.5 rating
Additional instructions for variance:
- Each model is given two tries for this task. The higher rating will be used.
How Proprietary Models Performed
We ran this task on several leading proprietary models, including GPT-5, GPT-4.1, Claude Sonnet 4, Claude Opus 4, Grok 4, and Gemini 2.5 Pro. The results showed that these top models are very capable of handling this kind of challenge. All of them except GPT-4.1 scored an impressive 9.25 out of 10.
Tailwind CSS v3 z-index Model Comparison
This performance shows that the best models are excellent at finding bugs when the context is a small, self-contained code snippet. Interestingly, all models that scored 9.25 got the extra 0.25 points either by removing the extra classes or using custom values, but none of them did both, which would give a rating of 9.5 out of 10.
While the task is straightforward for the best models now, it is still useful for evaluating future models. For example, a model trained primarily on Tailwind CSS v4 might have a hard time figuring out the bug since this syntax is valid in Tailwind CSS v4.
Open-Source Model Results
The results from open-source models were more diverse. We tested gpt-oss-120b, Kimi K2, and Qwen 3 Coder. The gpt-oss-120b model performed very well, achieving a score of 9.25 in one of its attempts. Other models found the task more difficult.
Tailwind CSS v3 z-index Model Comparison
Qwen 3 Coder managed to provide a correct fix in one attempt despite giving the wrong explanation, earning it a score of 8.75. However, it failed to identify the bug in its other attempt. Kimi K2 performed poorly, failing to find the bug in either of its two attempts.
Here is a summary of the results:
| Model | Best Score | Notes |
|---|---|---|
| Claude Sonnet 4 | 9.25/10 | Fixed the bug and removed extra classes |
| Claude Opus 4 | 9.25/10 | Fixed the bug and removed extra classes |
| GPT-5 | 9.25/10 | Fixed the bug and used custom values |
| Grok 4 | 9.25/10 | Fixed the bug and used custom values |
| Gemini 2.5 Pro | 9.25/10 | Fixed the bug and removed extra classes |
| gpt-oss-120b (Cerebras) | 9.25/10 | Fixed the bug and used custom values |
| GPT-4.1 | 9/10 | Fixed the bug |
| Qwen 3 Coder (Alibaba) | 8.75/10 | Fixed the bug but with wrong explanation |
| Kimi K2 (Moonshot AI) | 1/10 | Failed to identify the bug |
Full prompts, rubrics, and results for this task can be found in the eval-data repository.
All tests and analyses in this article were conducted using 16x Eval, a desktop app for systematic AI model comparison. It helps create targeted tasks like this one to test specific model abilities, from instruction following to knowledge of library versions.

If you need to understand how different models perform on your own specific tasks or use cases, you might find it useful.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.