The coding eval set in 16x Eval has seen a wave of new high performing models. Many standard tasks are now "solved" by the leaders. So we added a new and much tougher challenge: the Clean MDX task. This post covers what is new about the task and how we score it. It also shares the first results from models including GPT-5, Gemini 2.5 Pro, and Grok 4.
Why a Tougher Clean MDX Task?
Over the past year, top coding models have pulled away on tasks like clean markdown and simple bug fixes. New releases, especially flagship proprietary models and strong open source coders, are getting near perfect scores. That makes it hard to tell them apart in head to head benchmarks.
To keep the evals useful, we needed a harder prompt that tests real parsing and cleaning logic. That is where the new Clean MDX task comes in. It is explicitly designed to break simple pattern matching and to raise the bar for reasoning, instruction following, and robustness.
Clean MDX Task Details
The Clean MDX task is a more difficult variant of the old clean markdown task. It asks models to implement a cleanMDX function that cleans up complex MDX (Markdown + JSX) text.
Compared to the old clean markdown task, the new task is much harder because it requires more advanced parsing and cleaning logic for multi-line import statements and different types of nested components in the sample input file.
Here's an excerpt of the prompt for the task (excluding sample input, expected output and sample test file):
Implement `cleanMDX` function that cleans MDX format text, with the following rules:
- Unwrap code blocks
- Unwrap markdown links
- Replace headings with plain text
- Remove tables
- Remove react components
- Remove import statements
- Remove frontmatter
- Remove horizontal rule separators (---)
The code would be placed inside `cleanMDX.ts`, and it would be tested by `test.ts`.
Output the full content of `cleanMDX.ts` wrapped in markdown code block, no other text or explanation needed.
// sample input
// ...
// expected output
// ...
// test harness sample
// ...You can find the full prompt and datasets on GitHub to take a look at the sample input, expected output, and test harness.
Evaluation rubrics are as follows:
| Criteria | Penalty/Bonus |
|---|---|
| No text removed | 9/10 |
| Some text content removed | 8/10 |
| Left-over table/import/component | -0.5 rating each |
| No output newlines | -1 rating |
| One or more newline issues | -0.5 rating |
| Short, correct code (≤1500 chars) | +0.25 rating |
| Verbose output | -0.5 rating |
Evaluation Methodology and Outlier Control
This task is much harder and it brings more room for variance. To account for this, each model is given two independent attempts. For final scoring, only the higher attempt counts for each model. This reduces the effect of rare outlier failures and better reflects best case ability.
As with all evals conducted by us, we use the default parameters from the provider's API for each model to simulate the most common usage pattern. That includes temperature, verbosity, reasoning effort, and other parameters.
A human evaluator manually rates the output according to the rubric to ensure no hallucination or inaccuracy from automated scoring methods.
Results: How Did Top Models Fare?
We tested a broad set of top models such as Grok 4, Claude Opus 4, Claude Sonnet 4, Kimi K2, GPT-4.1, and Gemini 2.5 Pro. We also included the newly released GPT-5.
The results were surprising. Grok 4 took the top spot, scoring up to 9 out of 10. It produced a perfect 100 percent match with the expected output on one of the two attempts.
Gemini 2.5 Pro secured second with 8.5 out of 10 on both attempts, with left-over components as the only issue in the output. GPT-5 and GPT OSS 120B (via Cerebras) were close behind. Each earned an 8 out of 10. They usually lost points for minor newline glitches or stray import or component code left in the output.
Sonnet 4, Opus 4, and GPT-4.1 all landed behind the leaders, mostly due to issues with missing text or not fully cleaning out MDX elements. Kimi K2 lagged further behind with multiple issues in both attempts.
For a quick view of the scoring and notes during evaluation:
| Model | Score (Best of 2) | Attempt 1 Issues | Attempt 2 Issues |
|---|---|---|---|
| Grok 4 | 9/10 | 100% match | No newline |
| Gemini 2.5 Pro | 8.5/10 | Leftover components | Leftover components |
| GPT-5 | 8/10 | Newline issue, leftover component | Newline issue, leftover component |
| GPT OSS 120B (Cerebras) | 8/10 | Leftover import/component | Leftover import/component |
| Claude Sonnet 4 | 7.5/10 | Text removed, leftover component | Text removed, no newline, leftover import/component |
| Claude Opus 4 | 7.5/10 | Text removed, leftover component | Text removed, leftover import/components |
| GPT-4.1 | 7.5/10 | Leftover tables/imports/components | 6 newline issues, leftover import/components |
| Kimi K2 | 7/10 | Text removed, leftover import/component | Text removed, leftover import/component |
Here's chart that shows the comparison results of the Clean MDX task for the top models.
Clean MDX (Difficult) Model Comparison
This chart shows how competitive the field is. It also shows that even flagship models fail to reach a perfect score on this challenging task.
Here's a more detailed 16x Eval screenshot of the evaluation results showing metrics such as speed, response token count, and cost.
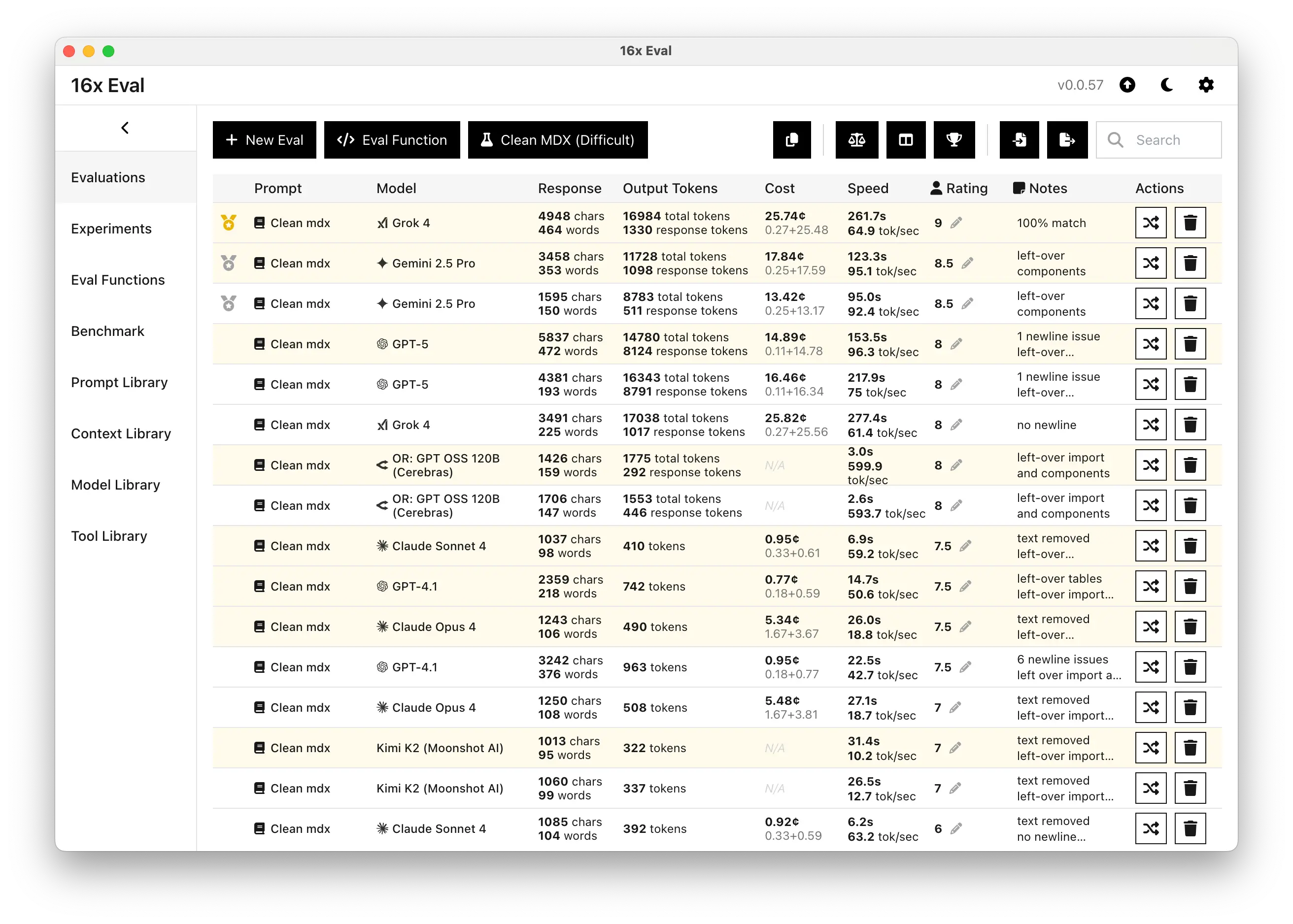
Interestingly, all the top performing models for this task are thinking models which produce reasoning tokens before the final output. This suggests that reasoning capabilities are important for this type of complex coding task.
We will be running a full evaluation of GPT-5 across all core 16x Eval coding tasks in the coming days. Stay tuned for the results.
All tests and analyses in this article were conducted using 16x Eval, a desktop app for systematic AI model comparison.
16x Eval makes it easy to design new tasks, rate output, account for response variance, and understand where each model excels or struggles. If you want to create your own tasks or replicate these results, it's a tool you should definitely check out.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.