When giving instructions to Large Language Models (LLMs), it feels natural to tell them what not to do. Negative instructions like "don't use library X" or "never create duplicate files" are common ways we try to set boundaries.
However, evidence suggests they may not work as intended. In this post, we'll look at why this happens and suggest better ways to give instructions to LLMs.
Negative Instructions in System Prompts
First, we want to acknowledge that negative instructions are used by AI companies in their system prompts. For example, the leaked system prompt for Cursor, an AI-powered code editor, contains explicit rules:
NEVER refer to tool names when speaking to the USER
DO NOT guess or make up an answer.
Anthropic's system prompt takes a slightly different approach by using descriptive statements to define its persona, rather than direct negative commands.
Here are some examples from Anthropic's system prompt for Claude 4 Opus:
Claude does not provide information that could be used to make chemical or biological or nuclear weapons...
Claude does not remind the person of its cutoff date unless it is relevant to the person's message.
Claude does not claim to be human and avoids implying it has consciousness, feelings, or sentience with any confidence.
These are framed as descriptions of the model's established behavior, not explicit prohibitions. They use third-person language, which differs from normal negative instructions that are imperative sentences.
Limited Effectiveness in User Prompts
Despite these negative instructions being used by large AI companies in system prompts, empirical evidence we've seen online suggests that negative instructions can be unreliable as user prompts.
For instance, one user on Reddit described how Claude Code would create multiple versions of files, like file-fixed.py and file-correct.py, despite explicit rules in their CLAUDE.md file to "NEVER create duplicate files".
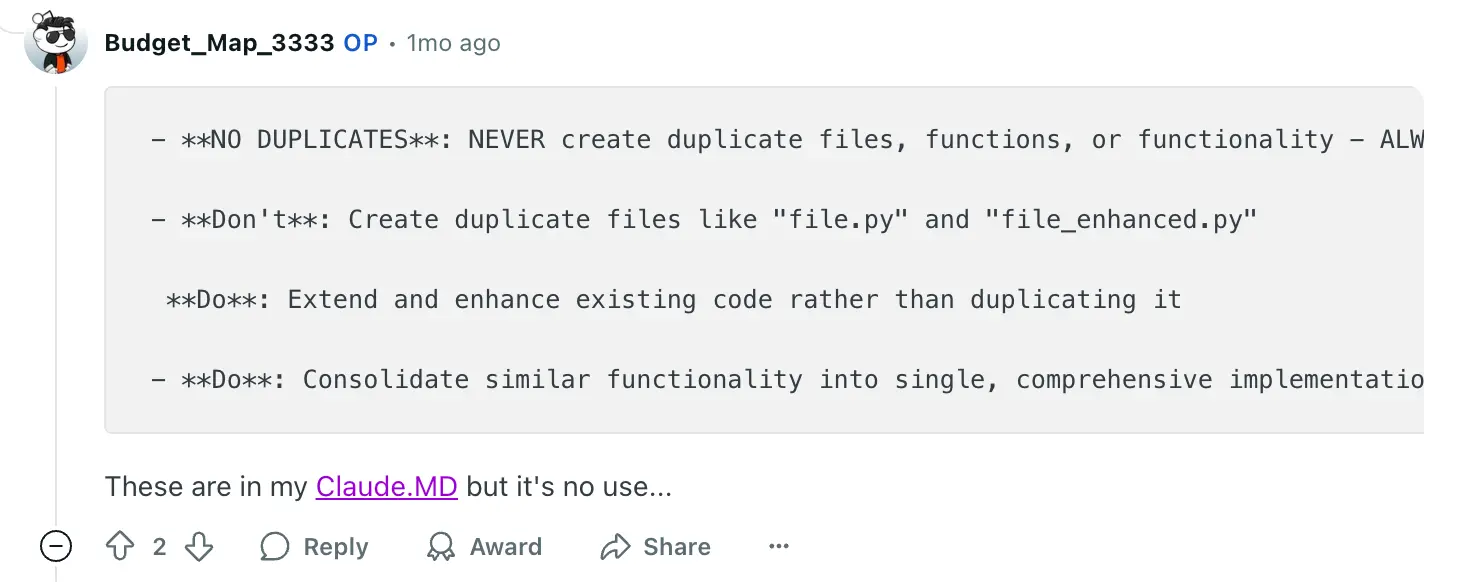
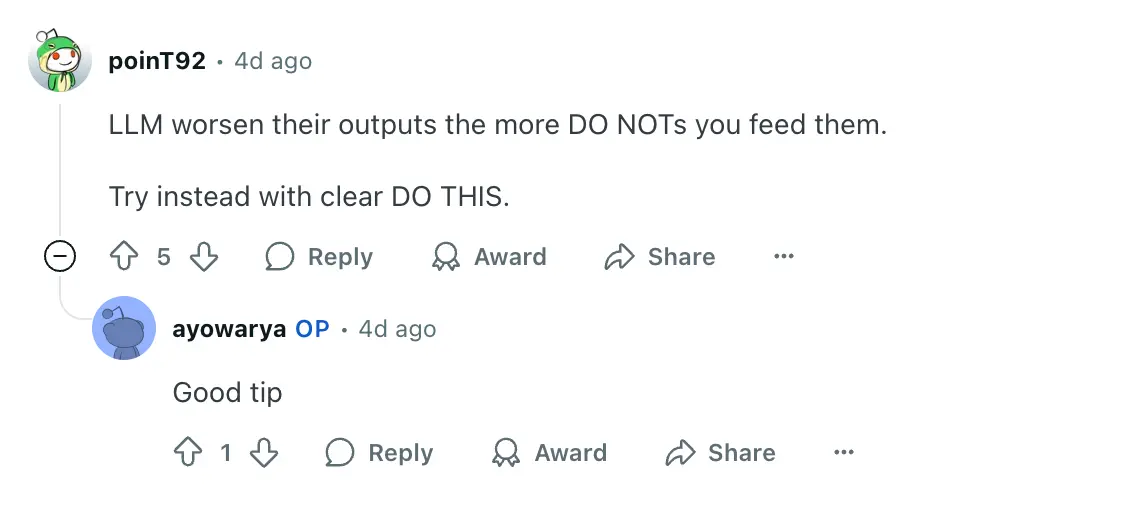
In another case, one user noted that LLMs seem to produce worse output the more "DO NOTs" are included in the prompt.
People also found that Gemini models have a "hit-or-miss" record when following negative commands.
While these Reddit posts are anecdotal evidence and not controlled experiments, they do suggest that negative instructions are not always effective in real-world usage.
The Psychology Behind the Failure
When looking for an explanation for the limited effectiveness of negative instructions, we can look to the Ironic Process Theory, also called the "white bear problem" or "pink elephant paradox."
The theory suggests that trying to suppress a specific thought makes it more likely to surface. When you are told "don't think of a pink elephant," your brain must first process the concept of a pink elephant to know what to avoid, ironically bringing it to the forefront of your mind.
We can draw an analogy for LLMs: Since they are neural networks modeled after human brains and trained on vast amounts of human language and data, they may exhibit behaviors consistent with human cognitive patterns like the Ironic Process Theory.
A Better Approach: Positive Framing
Are there better ways to give instructions in user prompts? The answer is yes.
An good alternative to negative instructions is to reframe negative instructions as positive, explicit commands. Instead of telling the model what to avoid, tell it what you want it to do. This approach provides clear, actionable guidance that is easier for the model to follow.
Anthropic, the creator of Claude, officially endorses this approach in their prompt engineering best practices documentation. They explicitly advise: "Tell Claude what to do instead of what not to do."

For example, instead of saying "Do not use markdown in your response," they recommend saying "Your response should be composed of smoothly flowing prose paragraphs."
This usage of positive framing instead of prohibitive language can lead to more reliable outcomes. Reddit user KrugerDunn, who had problems with Claude creating new file versions, found success by changing their instruction from "do not make new versions" to "Make all possible updates in current files whenever possible."
Here is a table with a few examples of how you can paraphrase negative instructions into positive ones:
| Negative Instruction (Less Effective) | Positive Instruction (More Effective) |
|---|---|
| "Don't use mock data." | "Only use real-world data." |
| "Don't use library X for state management." | "Only use library Y for state management." |
| "Avoid creating new files for fixes." | "Apply all fixes to the existing files." |
| "Never output code with overly descriptive comments." | "Write professional, concise code comments." |
Finding the Right Balance
While positive framing provides clearer guidance, negative constraints still have their place.
They are effective at preventing unethical or harmful behavior, especially when used in system prompts. They are also useful for establishing firm boundaries where a positive alternative might be less direct or ambiguous.
Here are some tips on how to use negative instructions effectively:
- Use them sparingly: Avoid loading your prompts with multiple "don't do this" statements
- Be specific: Instead of "don't be verbose," try "don't include explanatory comments in code output"
- Pair with positives: Combine negative constraints with positive directions when possible
- Make them absolute: Use negative instructions for hard boundaries, not preferences
The key to crafting an effective prompt is to prioritize clear, affirmative commands. Use negative instructions strategically, rather than relying on them as your primary method of control.
Understanding how different models respond to prompts is key to getting good results from LLMs.
Tools like 16x Eval can help you systematically test different prompting strategies. You can run side-by-side comparisons of different prompt variations on your own tasks to see what works best for your specific use case.
