Moonshot AI recently released Kimi K2, a new mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters.
We evaluated Kimi K2 across 6 experiments covering coding and writing tasks to understand its capabilities and position in the current model landscape.
Our results show that Kimi K2 is the new top open-source non-reasoning model for coding tasks while maintaining competitive performance in writing.
Provider & Performance Consistency
As established in our previous Kimi K2 provider evaluation, Moonshot AI provides consistent and reliable performance as the model's creator. We perform this evaluation using the Moonshot AI API at https://api.moonshot.ai/v1 with model ID kimi-k2-0711-preview. For each task, the model outputs were assigned a rating by a human evaluator based on the evaluation rubrics.
Before conducting our main evaluation, we performed a pilot study to understand Kimi K2's output variance. We selected two representative tasks (one coding and one writing) and ran each prompt three times through the Moonshot AI API.
| Prompt | Model | Response | Output Tokens | Rating |
|---|---|---|---|---|
| AI timeline | Kimi K2 (Moonshot AI) | 5295 chars | 986 tokens | 8.5/10 |
| AI timeline | Kimi K2 (Moonshot AI) | 5112 chars | 1007 tokens | 8.5/10 |
| AI timeline | Kimi K2 (Moonshot AI) | 6134 chars | 1156 tokens | 9/10 |
| clean markdown v2 | Kimi K2 (Moonshot AI) | 985 chars | 303 tokens | 9.25/10 |
| clean markdown v2 | Kimi K2 (Moonshot AI) | 991 chars | 306 tokens | 9.25/10 |
| clean markdown v2 | Kimi K2 (Moonshot AI) | 948 chars | 295 tokens | 9.25/10 |
The variance analysis results showed consistent performance. This low variance across generations provided confidence for using single generations in our subsequent evaluation tasks on coding and writing.
Coding Performance
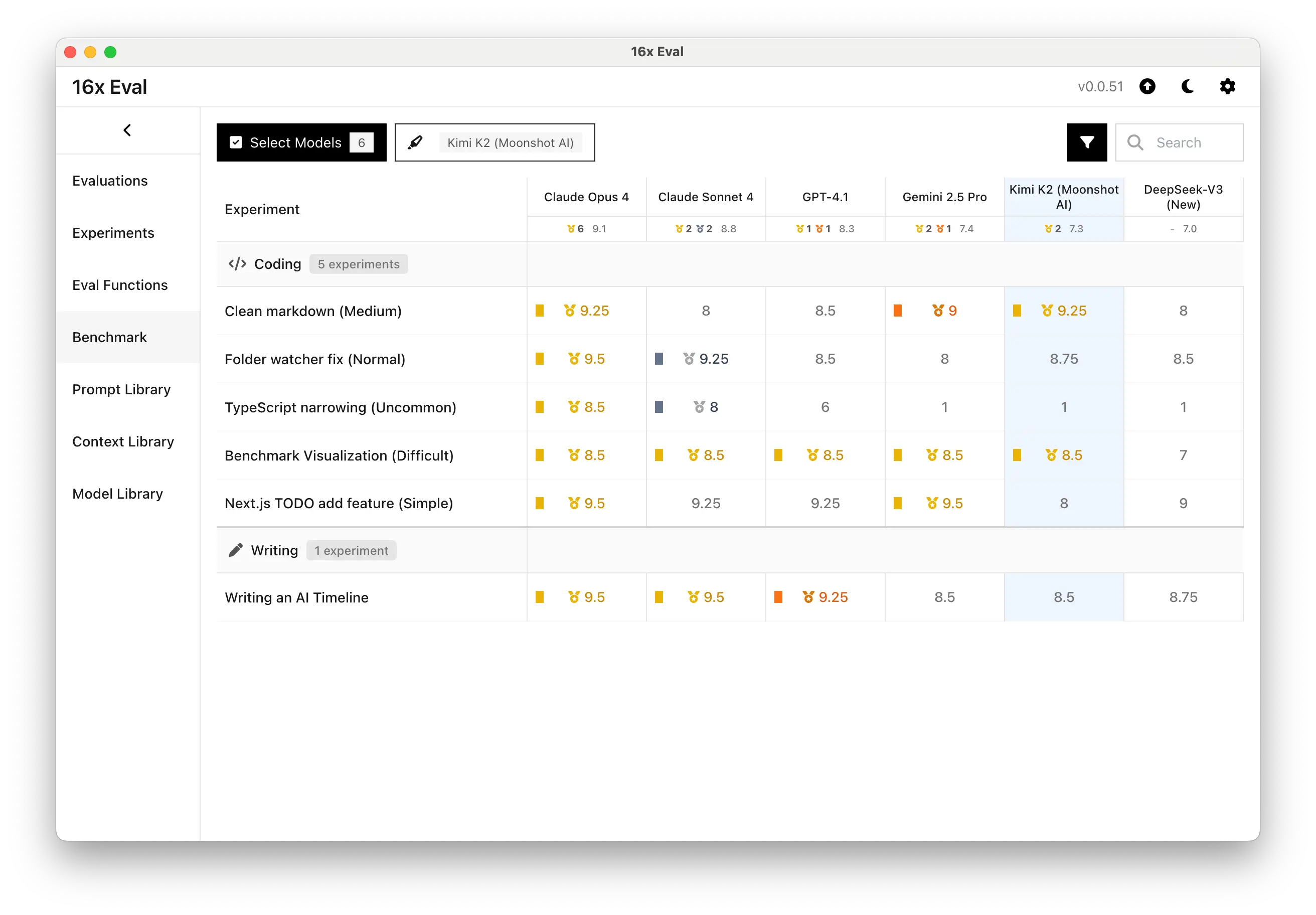
Based on our evaluation on 5 coding tasks, Kimi K2 demonstrates strong coding capabilities, achieving top or near-top performance across multiple programming tasks.
The most significant result is that Kimi K2's overall coding performance exceeds DeepSeek V3 (New), establishing it as the new top open-source non-reasoning model for coding tasks.
Kimi K2 vs DeepSeek V3 (New) - Individual Coding Task Performance
When compared to top models like Claude Sonnet 4 and GPT-4.1, Kimi K2 performed well on common tasks, but not as strong on tasks that are uncommon (TypeScript narrowing) or require precise instruction-following (Next.js TODO).
Kimi K2 vs Top Models - Individual Coding Task Performance
When looking at individual task performance, we can see that Kimi K2 performed well on 3 tasks, and poorly on 2 tasks:
Good Performance on 3 Tasks
-
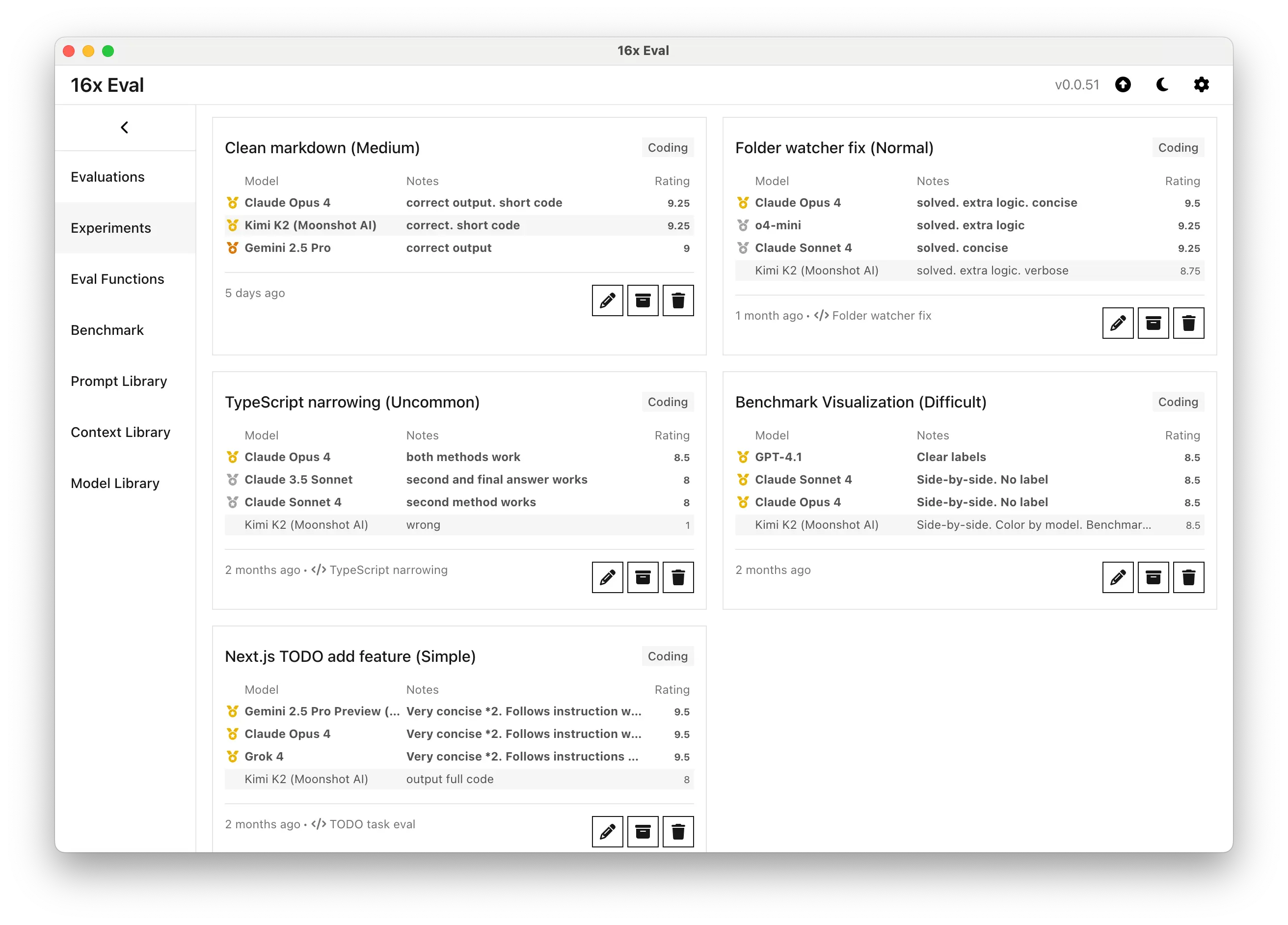
Medium-difficulty task: The model scored 9.25 out of 10 on the clean markdown conversion task, tying with Claude Opus 4 for the highest rating. The response was also very consistent, as seen in our pilot study.
-
Normal task: On the folder watcher fix task, Kimi K2 earned 8.75, placing it among the top performers alongside Claude models and Grok 4. The model provided complete solutions with additional helpful logic, though in a more verbose format than the most concise responses.
-
Complex task: For the benchmark visualization task, Kimi K2 scored 8.5, matching the performance of Claude Sonnet 4, Claude Opus 4, GPT-4.1 and Gemini 2.5 Pro. The model produced an effective side-by-side visualization with model-based color coding and benchmark differentiation through alpha transparency.
Poor Performance on 2 Tasks
-
Uncommon task: On the TypeScript narrowing task, Kimi K2's approach aligned with other open models, but failed to reach the solution (scoring 1/10, similar to DeepSeek V3 and behind Claude Opus 4 at 8.5/10). This suggests that Kimi K2 is less competitive on highly specialized programming logic.
-
Simple task on instruction following: For the Next.js TODO add feature task, Kimi K2 scored 8, outputting the full code, instead of following the instructions to only output the code that contains changes.
Here's the overall average rating comparison of Kimi K2 vs top models in coding tasks:
Coding Performance Comparison of Top Models based on Average Rating
Here is the summary table of Kimi K2's coding performance ratings across 5 coding tasks compared to current top models:
| Experiment | Kimi K2 | Claude Opus 4 | Claude Sonnet 4 | GPT-4.1 | Gemini 2.5 Pro |
|---|---|---|---|---|---|
| Average Rating | 7.1 | 9.1 | 8.6 | 8.2 | 7.2 |
| Clean markdown (Medium) | 9.25 | 9.25 | 8 | 8.5 | 9 |
| Folder watcher fix (Normal) | 8.75 | 9.5 | 9.25 | 8.5 | 8 |
| TypeScript narrowing (Uncommon) | 1 | 8.5 | 8 | 6 | 1 |
| Benchmark Visualization (Difficult) | 8.5 | 8.5 | 8.5 | 8.5 | 8.5 |
| Next.js TODO add feature (Simple) | 8 | 9.5 | 9.25 | 9.25 | 9.5 |
Technical Writing Capabilities
Kimi K2 shows solid performance in our writing task, though with some room for improvement compared to the absolute top tier.
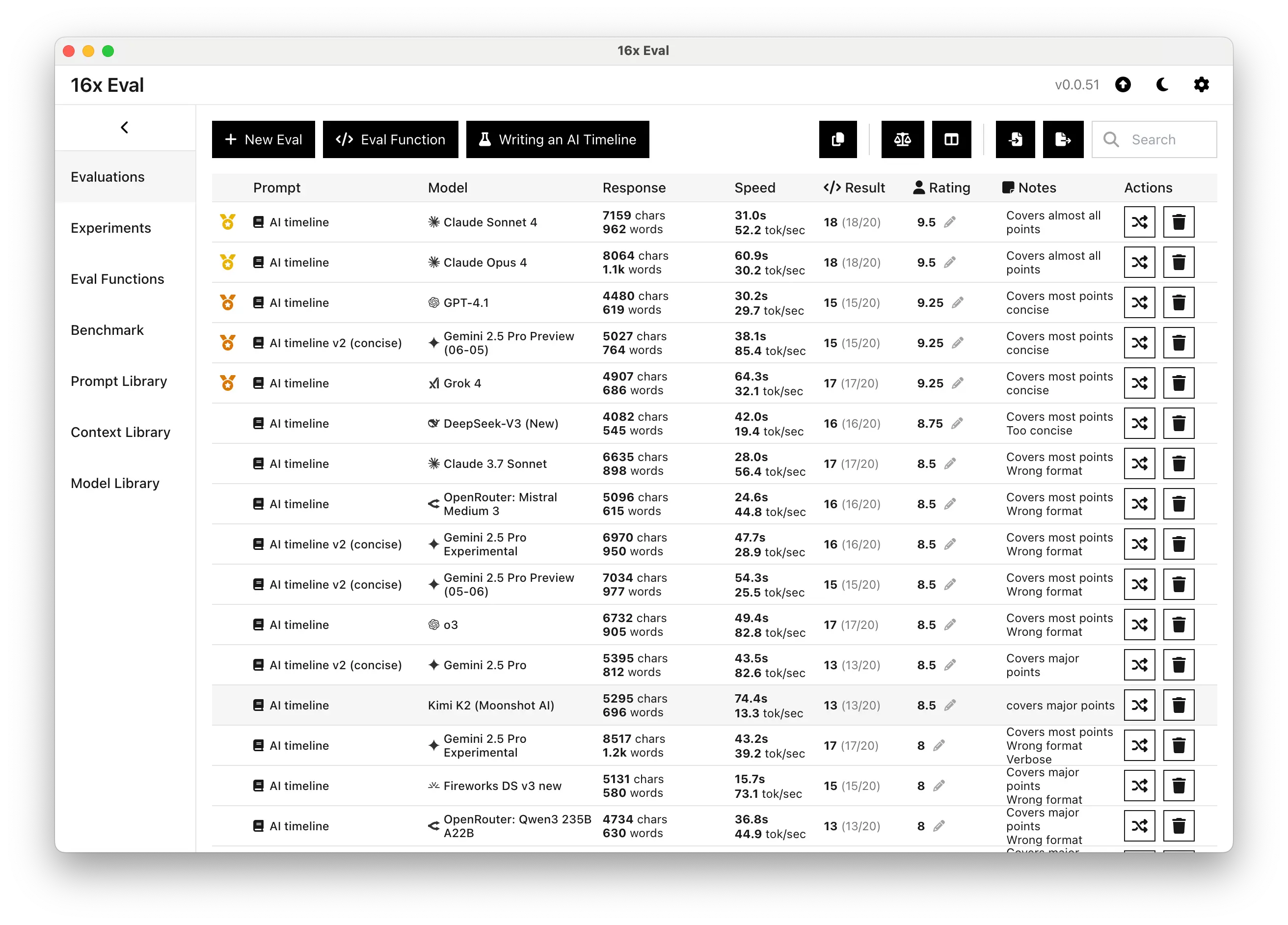
On the AI timeline writing task, it achieved an 8.5 rating, covering major historical points in AI development from 2015 to 2024.
This performance places Kimi K2 slightly behind DeepSeek V3 (New) (8.75) and competitive with Gemini 2.5 Pro (8.5). However, it still trails behind the leading models like Claude Sonnet 4 and Claude Opus 4 (both 9.5) and GPT-4.1 (9.25).
We did find in our provider evaluation that DeepInfra hosting of Kimi K2 can score above major proprietary models for writing tasks. However, we were unable to reproduce this performance with the Moonshot AI API.
Given the natural rating clustering around 8.5, and the lack of other experiments, it's difficult to draw definitive conclusions. We plan to expand our evaluation to add more writing tasks in the future.
Overall Performance
Our evaluation positions Kimi K2 as a solid second-tier model overall, with particularly strong performance as the top open-source non-reasoning* model for coding tasks.
The model consistently outperforms DeepSeek V3 (New) across coding tasks while matching its writing performance. Kimi K2 also performs competitively with Gemini 2.5 Pro* across most tasks.
Performance Comparison of Kimi K2 vs DeepSeek V3 (New) vs Gemini 2.5 Pro by Task Category
When comparing performance against the current top models, Kimi K2 remains behind Claude 4 models, GPT-4.1, and Grok 4 in terms of both coding and writing tasks.
Performance Comparison of Kimi K2 vs Top Models by Task Category
Kimi K2 currently lacks vision capabilities, so we were not able to evaluate it on our image analysis tasks.
Evaluation with 16x Eval
All results in this post were produced using 16x Eval, a desktop application for running custom model evaluations. With 16x Eval you can evaluate multiple models, collect response metrics, and compare results side-by-side across coding, writing, and other task types.

If you're looking for a tool for model evaluation, 16x Eval can help you control, measure, and understand model output, making it easier to pick the best LLM for your particular needs.
* While the Moonshot AI team claims the model is good at reasoning tasks, we do not consider Kimi K2 as a reasoning model, as it does not have explicit separate reasoning process or reasoning tokens. It is a standard instruct model, as seen from the Hugging Face model card.
* Gemini 2.5 Pro tested in this evaluation is the GA (General Availability) version of Gemini 2.5 Pro.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.