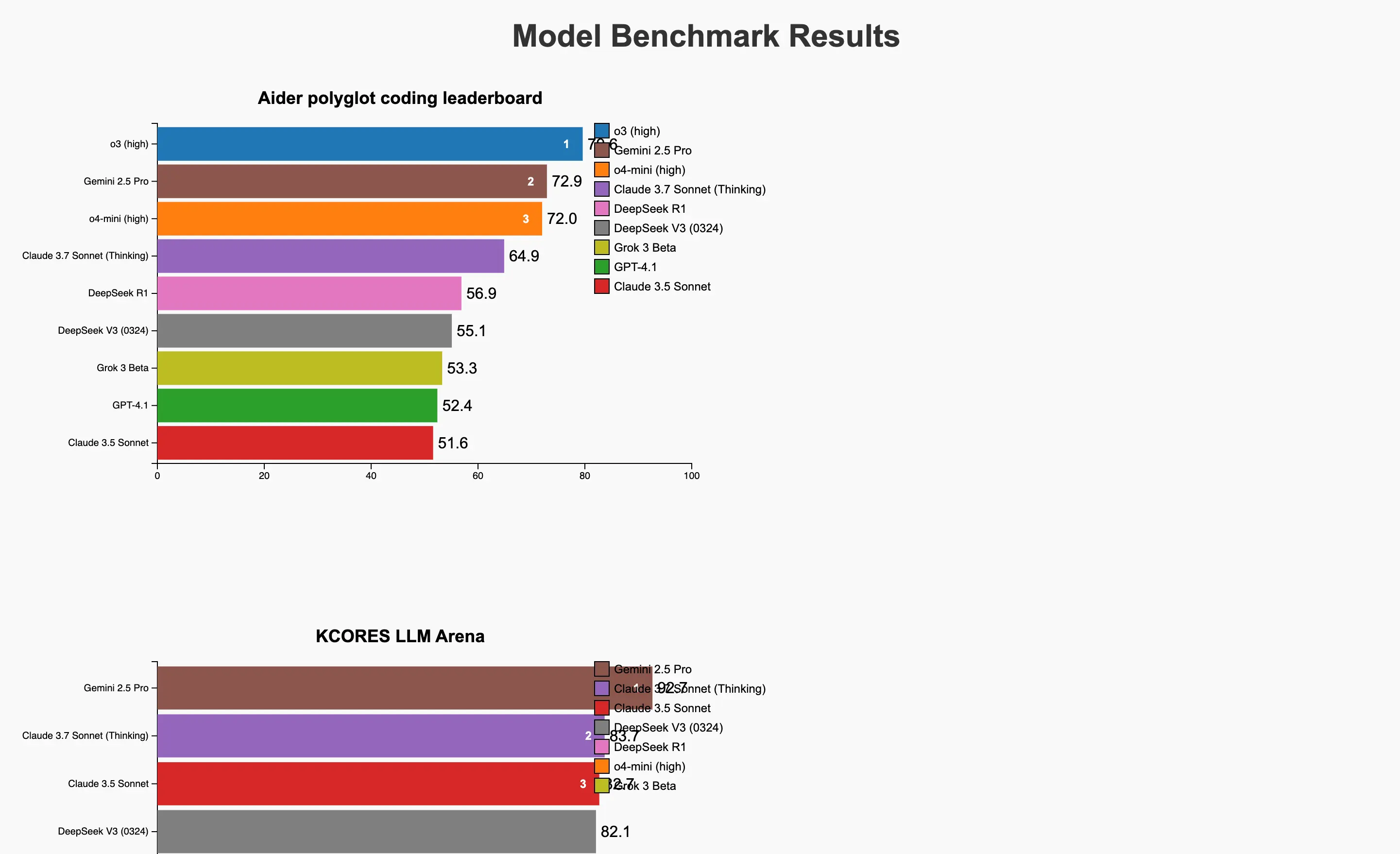
Alibaba recently released Qwen3 Coder, a new coding-focused language model designed for agentic coding tasks. This 480B-parameter Mixture-of-Experts model with 35B active parameters supports 256K context length natively and up to 1M tokens with extrapolation methods.
In this post, we take a look at how Qwen3 Coder performs on core coding benchmarks, comparing it with other top open and proprietary models, including Kimi K2, DeepSeek V3 (New), Gemini 2.5 Pro, and Claude Sonnet 4.
Update on 28 August: We have added new eval tasks to our evaluation set since this post was published, which resulted in Qwen3 Coder being placed higher than Kimi K2 for coding as of 28 August. See the latest results here.
Methodology and Output Consistency
For this evaluation, we used 16x Eval to run Qwen3 Coder (using the Alibaba Plus provider via OpenRouter, using the model ID qwen/qwen3-coder) through five representative coding tasks. These tasks include a balanced mix of easy, medium, and difficult coding prompts, as well as instruction-following and uncommon logic challenges. The model outputs were assigned a rating by a human evaluator based on the evaluation rubrics.
To understand the output variance of Qwen3 Coder, we ran the clean markdown task three times. The results were largely consistent in terms of output tokens and rating.
| Run | Prompt | Output Characters | Output Tokens | Rating |
|---|---|---|---|---|
| 1 | Clean markdown v2 | 1071 | 317 | 9.25/10 |
| 2 | Clean markdown v2 | 912 | 284 | 9.25/10 |
| 3 | Clean markdown v2 | 1040 | 320 | 8.75/10 |
Coding Performance on Individual Tasks
The main focus of this test was coding ability across diverse challenges. Let's walk through Qwen3 Coder's performance on three key experiments: clean markdown, benchmark visualization, and the tricky TypeScript narrowing task.
On the clean markdown task, Qwen3 Coder delivered a compact, correct solution, tying with Kimi K2 and Claude Opus 4 at a top 9.25, and well above DeepSeek V3 (New), which scored 8.
Clean markdown (Medium) Performance Comparison
On the benchmark visualization task, Qwen3 Coder dropped a bit from the leaders, scoring 7.
Benchmark Visualization (Difficult) Performance Comparison
The model produced serviceable horizontal bar visualizations, but formatting issues set it behind Kimi K2, Gemini 2.5 Pro, and Claude Sonnet 4, all of which scored higher with clean, readable visualizations and more nuanced color choices.
The TypeScript narrowing task that features an uncommon type narrowing challenge separated the field. Kimi K2, Gemini 2.5 Pro, DeepSeek V3 (New), and Qwen3 Coder all struggled, scoring just 1/10. All of them made the same conceptual mistake and failed to produce code that passed the TypeScript compiler check.
In contrast, Claude Sonnet 4 led by correctly solving the problem and scoring 8/10.
TypeScript narrowing (Uncommon) Performance Comparison
Here's the overview of the performance on 5 coding tasks against Kimi K2 and Claude Sonnet 4:
Coding Performance Comparison of Qwen3 Coder vs Kimi K2 and Claude Sonnet 4
Performance Observations
Here are the evaluation summary from 16x Eval for all 5 coding tasks:
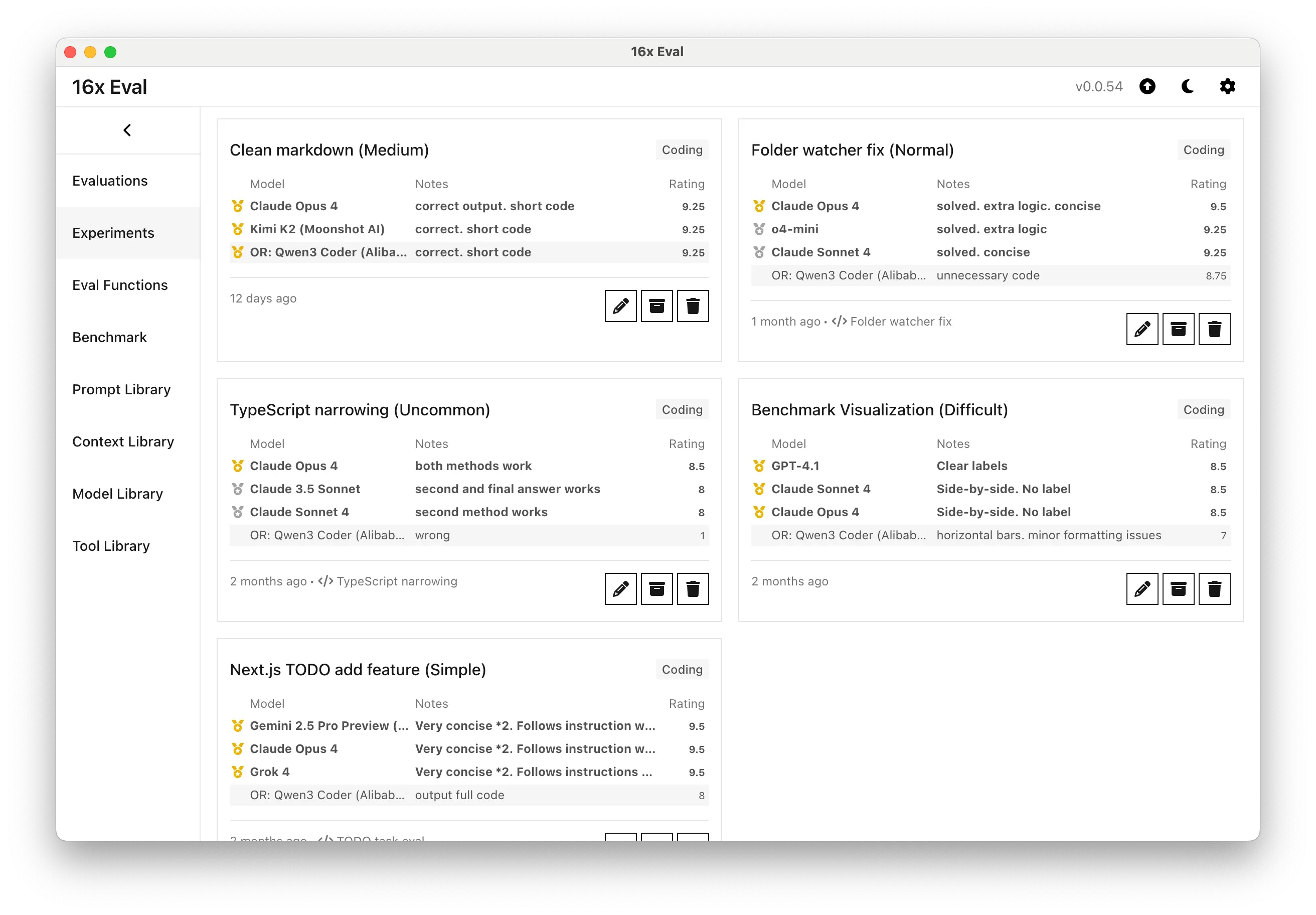
Based on the evaluation notes, we can make the following observations:
- On standard medium-level tasks, Qwen3 Coder is among the best. It matches premium models in producing correct, concise code for markdown cleaning task.
- For more complex visual tasks, like benchmark visualizations, it can lag behind due to UI formatting issues.
- It also falls short on logical reasoning for uncommon programming patterns, such as advanced TypeScript narrowing, where it falls short alongside almost all open LLMs.
- Instruction-following is not particularly good, Qwen3 Coder tends to output more verbose blocks for "output only diff" tasks, similar to Kimi K2.
Qwen3 Coder's ability to handle multi-turn prompts may make it suitable for agentic workflows, but that wasn't tested directly in this standard coding evaluation. For pure code quality and output structure, it's safe but not revolutionary.
Performance Comparison with Other Models
How does Qwen3 Coder stack up when looking at the broader model landscape? We compared its average ratings with top open-source models and market-leading proprietary models on the coding tasks.
Coding Ratings: Qwen3 Coder vs Top Open-Source and Proprietary Models
Compared to open-source peers, Qwen3 Coder outperforms DeepSeek V3 (New) on average, but remains a step behind Kimi K2 in most areas. Kimi K2 continues to claim the top open-source spot for coding, thanks to its better formatting and slightly stronger performance on normal and visualization tasks.
Against top proprietary models, Qwen3 Coder is less competitive. Gemini 2.5 Pro beats it overall, even though Qwen3 Coder matches or exceeds it on some concise-code tasks.
Qwen3 Coder is still far behind the top models like Claude 4 models or GPT-4.1 for coding tasks.
Overall Standing and Recommendation
Overall, Qwen3 Coder is a robust open-source choice for code generation use cases. It is a clear improvement over DeepSeek V3 (New). However, Kimi K2 keeps the crown for best open non-reasoning coder.
We look forward to seeing how Qwen3 Coder's unique agentic coding features translate to more complex, interactive environments. For now, it's a strong second in the open-source field.
All of the results and analyses in this post were produced with 16x Eval.
16x Eval makes it easy to run side-by-side model comparisons, analyze output quality, and systematically benchmark LLMs for coding, writing, and more. If you're looking for a structured way to evaluate models like Qwen3 Coder on your custom tasks, it's a tool built to fit that exact need.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.