OpenRouter recently announced Horizon Alpha, a new stealth model available for public testing. As a stealth model, its true name and provider are kept under wraps, creating an opportunity for unbiased evaluation.
In this post, we will evaluate Horizon Alpha's coding abilities on coding tasks and compare its performance to other leading models. We will also analyze its unique characteristics and possible identity.
Update on 28 August: Alex from OpenRouter has confirmed in OpenRouter Discord server that Horizon Alpha was an "early checkpoint" in the GPT-5 family.
Methodology and Output Consistency
We evaluated Horizon Alpha on five coding tasks using 16x Eval. The tests were run by connecting to the OpenRouter API with the model ID openrouter/horizon-alpha. The tasks ranged from simple feature additions to more complex logic and visualization challenges. The model outputs were assigned a rating by a human evaluator based on the evaluation rubrics.
To measure the model's consistency, we sent the "clean markdown" prompt to Horizon Alpha five times. The results showed that while the response length varied significantly, the quality rating remained largely consistent. Three of the five runs scored an 8.5, while the other two scored 9, indicating reliable performance despite variations in verbosity.
| Run | Prompt | Output Characters | Output Tokens | Rating | Notes |
|---|---|---|---|---|---|
| 1 | Clean markdown v2 | 2073 | 685 | 9/10 | correct |
| 2 | Clean markdown v2 | 2088 | 653 | 9/10 | correct |
| 3 | Clean markdown v2 | 2422 | 720 | 8.5/10 | one newline issue |
| 4 | Clean markdown v2 | 3121 | 990 | 8.5/10 | one newline issue |
| 5 | Clean markdown v2 | 1837 | 596 | 8.5/10 | 3 newline issues |
Coding Performance on Individual Tasks
Horizon Alpha showed a mix of strengths and weaknesses across the different coding tasks. Its performance was quite distinct compared to other models we have tested.
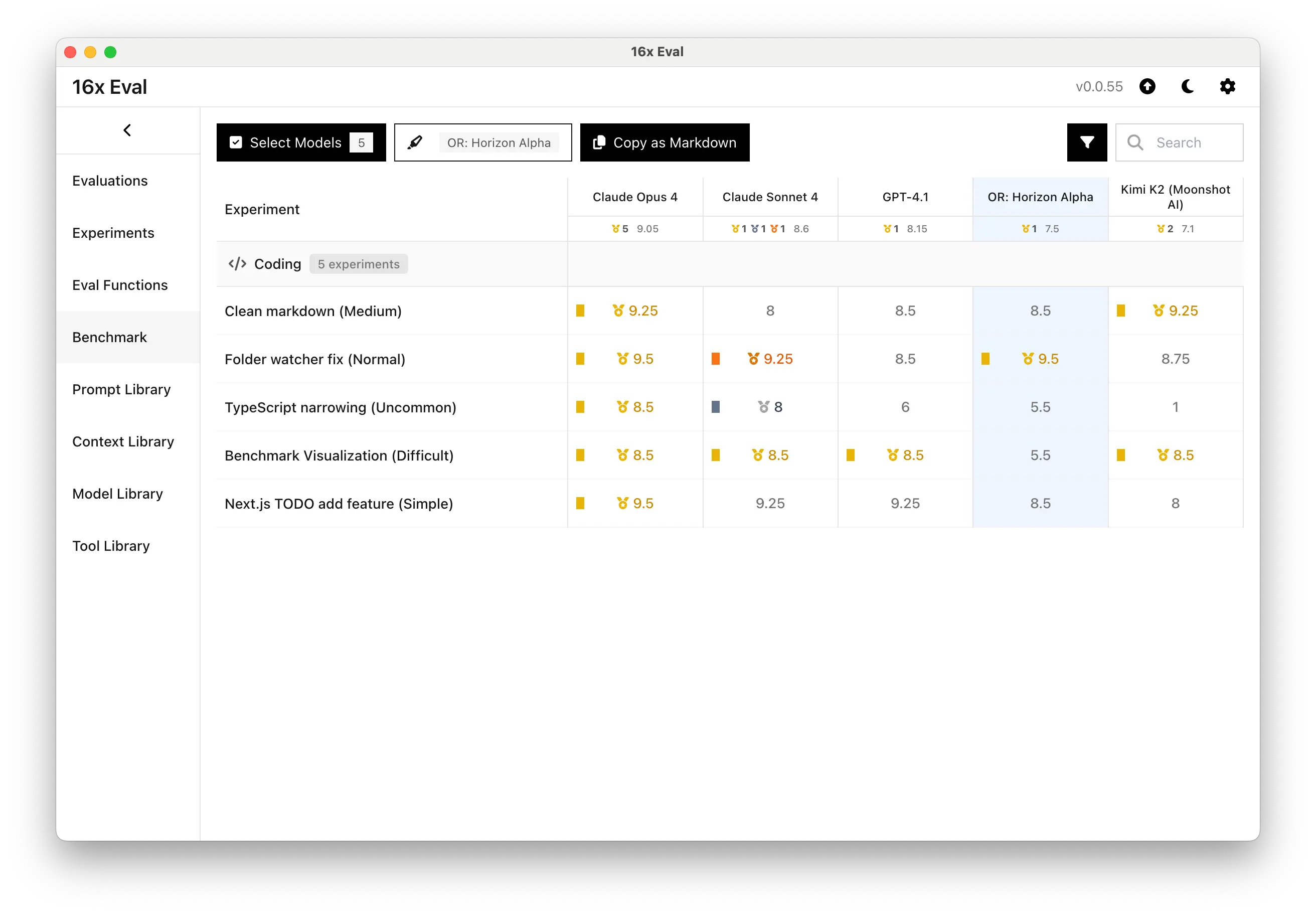
On the folder watcher fix task, Horizon Alpha performed exceptionally well, scoring a 9.5 out of 10, tying with Claude Opus 4 and ahead of top models like Claude Sonnet 4 and GPT-4.1.
Folder watcher fix (Normal) Performance Comparison
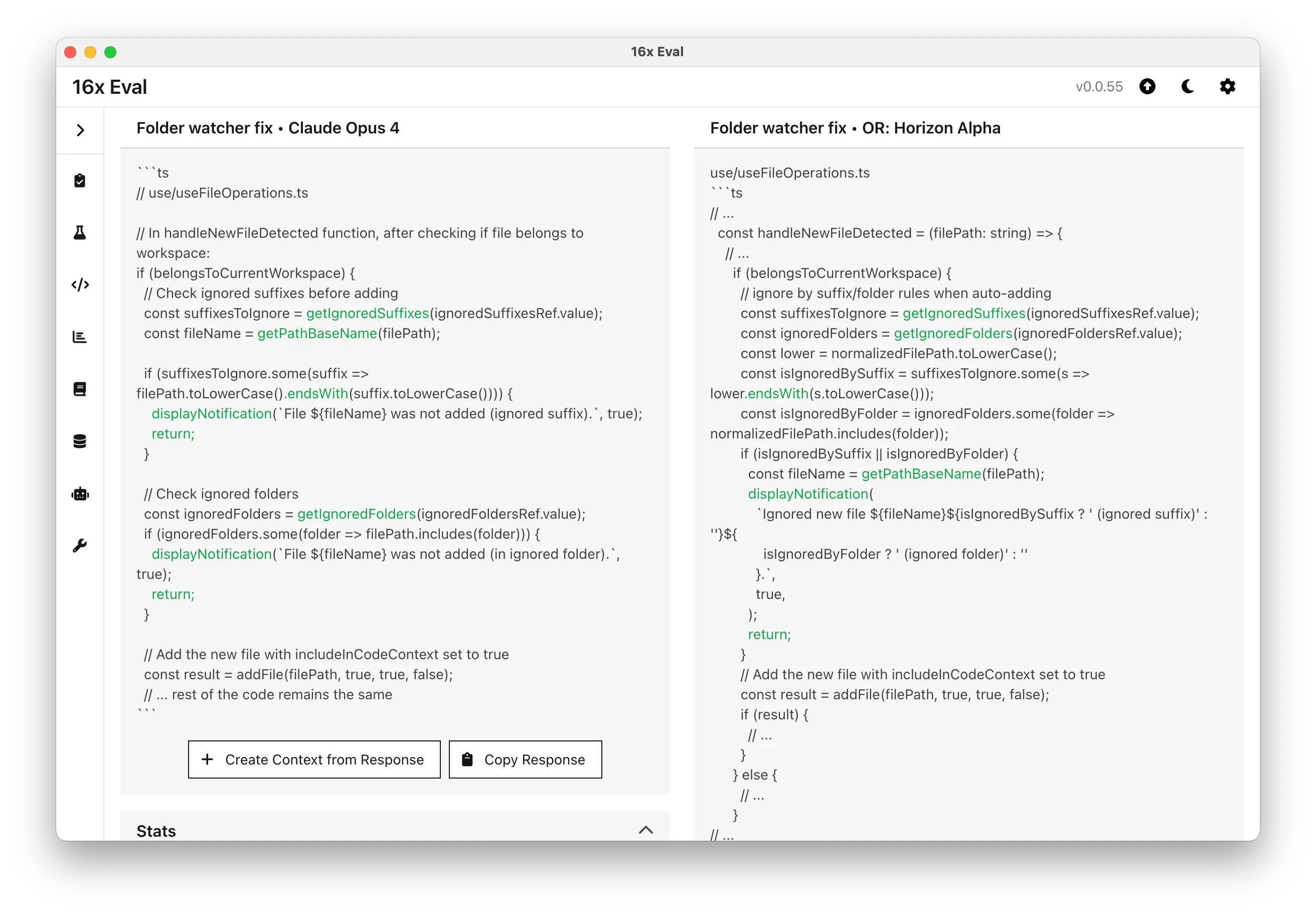
It provided a correct and concise response. The model also demonstrated a strong ability to respect code indentation, showing all layers of indentation clearly.
Here's a comparison of the output between Claude Opus 4 and Horizon Alpha. Note the difference in indentation between the two models:
For the Next.js TODO task, the model correctly followed instructions to output only the changed code, but the response was still verbose.
We attempted to make it more concise by including the phrase "Be concise" in the prompt, which was effective on Gemini 2.5 Pro. However, this method did not reduce Horizon Alpha's verbosity.
Due to its verbosity, it only got a rating of 8.5 out of 10, placing it behind Claude Sonnet 4 and GPT-4.1, but ahead of Kimi K2.
Next.js TODO add feature (Simple) Performance Comparison
The model's performance on the benchmark visualization task was unusual.
It generated a visualization using a vertical line with two ends representing the benchmarks. The output also had significant formatting issues, making it difficult to read. A second attempt produced a very similar result.
This is very different from the normal bar chart output from other models. It is also the first model to output a visualization with a dark color theme by default.
As a result of major formatting issues, it only got a rating of 5.5 out of 10, placing it behind most of other top models, including Claude Sonnet 4, GPT-4.1, and Kimi K2.
Benchmark Visualization (Difficult) Performance Comparison
On the TypeScript narrowing task, Horizon Alpha provided two different methods. The first method did not work correctly. The second method used the in keyword, which is not the optimal solution for this particular problem.
This sub-optimal solution got Horizon Alpha a rating of 5.5 out of 10, which is behind Claude 4 models. However, it is still better than most open-source models like Kimi K2 and Qwen3 Coder, which scored 1/10.
TypeScript narrowing (Uncommon) Performance Comparison
On the clean markdown task, Horizon Alpha scored a decent 8.5 out of 10, placing it behind Claude Opus 4 and Kimi K2, but ahead of Claude Sonnet 4. A rating of 8.5 also means it ties with GPT-4.1.
Clean markdown (Medium) Performance Comparison
Here's a summary of the model's performance on the individual tasks compared to other models:
Observations and Characteristics
Based on our testing results, we can see that Horizon Alpha performs well on typical coding tasks of easy and medium difficulty. However, it struggles with more complex tasks, like the benchmark visualization task or the TypeScript narrowing task.
We also discovered that Horizon Alpha exhibits several unique characteristics that set it apart from other models:
- One notable traits is its "verbosity" when outputting code. Unlike other models, this seems to stem from a strict adherence to indentation rules, where it outputs the full indentation layers even when only inner nested layers are needed.
- The model also has a very unusual style for visualizations. It defaults to a dark mode theme and uses vertical lines instead of more common formats like bar or radar charts. This visual style is unlike anything we have seen from other models.
- We also noticed that Horizon Alpha often omits markdown triple backticks when the response is interleaving code with text, something we have not observed from other models.
Another important observation is that the model is very fast, with an average token speed of about 150 tokens per second from the OpenRouter API.
Comparison with Other Models
When compared to other top models in the coding category, Horizon Alpha's performance is moderate. Its average rating of 7.5 places it ahead of most open-source models like Kimi K2, but behind top proprietary models like Claude Opus 4 and Claude Sonnet 4.
Horizon Alpha's score suggests it is a capable but not top-tier coding model. It holds its own but lags behind the leading competitors on more complex or nuanced tasks.
Average Rating for Coding Tasks: Horizon Alpha vs Top Models
Possible Identity and Origin
Horizon Alpha is a fascinating model with a unique personality. Its high speed and solid performance on certain tasks, together with its quirks, make it an interesting model.
In terms of its identity, there are clues that point to it possibly being a new coding-focused small model from OpenAI:
- There is precedence from OpenAI to collaborate with OpenRouter to release stealth models before launch. GPT-4.1 was stealth released as Quasar Alpha before its official launch.
- OpenAI is expected to launch a new open-source model soon, after initial delays.
- The provider has processed over 7B tokens in a day after its stealth release, which means it is able to handle massive amount of tokens at scale. This eliminates the possibility of a smaller lab which lacks the compute resources.
- OpenAI is currently behind Anthropic models in coding performance. It is possible that they are releasing a new suite of models to catch up, and this is the smaller model among them.
However, this is just a hypothesis. We will know more when the model is officially launched.
This evaluation was conducted using 16x Eval. 16x Eval allows you to test models on custom tasks, compare them side-by-side, evaluate their output quality, and understand their specific strengths and weaknesses.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.