We have all seen simple math questions confuse language models. The question "9.9" vs "9.11" is a great example spreading online. At first, you might think this is a simple question that proves the model is not good at math, but there is more to this problem.
First things first, if we are talking about pure math, the answer is simple. 9.9 is 9.90, which is bigger than 9.11. There is no confusion.
Software Version Numbers
However, things change in software versioning. If we talk about software version numbers, like 9.9, 9.10, and 9.11, the answer to the question "which is bigger: 9.9 or 9.11" is different.
Version numbers like 9.9, 9.10, and 9.11 use dots as separators, but each separated number is its own part for comparison. Here are some examples:
- For iOS version numbers, iOS 9.11 would come after iOS 9.9.
- For game patches like World of Warcraft, 1.11 patch would come after 1.9 patch.
In semantic versioning, where we have 3 parts in a version number: major, minor, and patch, 9.11.0 would be a later version than 9.9.0.
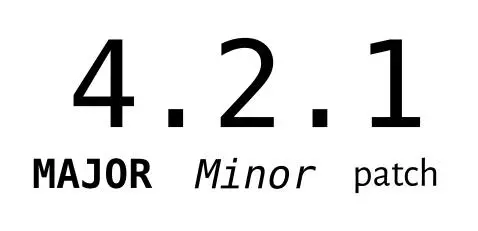
So it is perfectly reasonable to say that 9.11 is bigger than 9.9 in the context of software versioning.
Book and Bible Verses
Books like academic papers use similar numbering for chapters, for example, chapter 9.11 comes after chapter 9.9 inside a book.
Notably, Bible verses also follow this style: Matthew 9:11 comes after Matthew 9:9.
The Dewey Decimal System in libraries works in a similar way. A book with 595.9 comes before a book with 595.11. The numbers after the dot put things in order, instead of being a decimal.

So, how you read the numbers depends on the context. The purpose can be mathematics or organizing information. Many people who work with documents, chapters, or standards will see 9.11 as after 9.9.
Context is Key
Without context, the comparison "9.9 vs 9.11" can mean a decimal, a version number, or a chapter and verse. The AI is forced to guess the context from your question, and therefore if it picks a different context (e.g. version number instead of decimal) from the one you intended (maths), you will get the "wrong answer".
To make sure you get the right answer, you need to provide the right context. For example, "In maths, which number is bigger: 9.9 or 9.11?"
New Models Bias Towards Maths
With the newer models, providers have generally fixed this problem in the maths context, so models are able to answer the question correctly by assuming you are talking about maths.
However, this causes another negative side effect, where if you ask the question explicitly in a different context like version number, the language model may get it wrong by confusing the version number for a decimal.
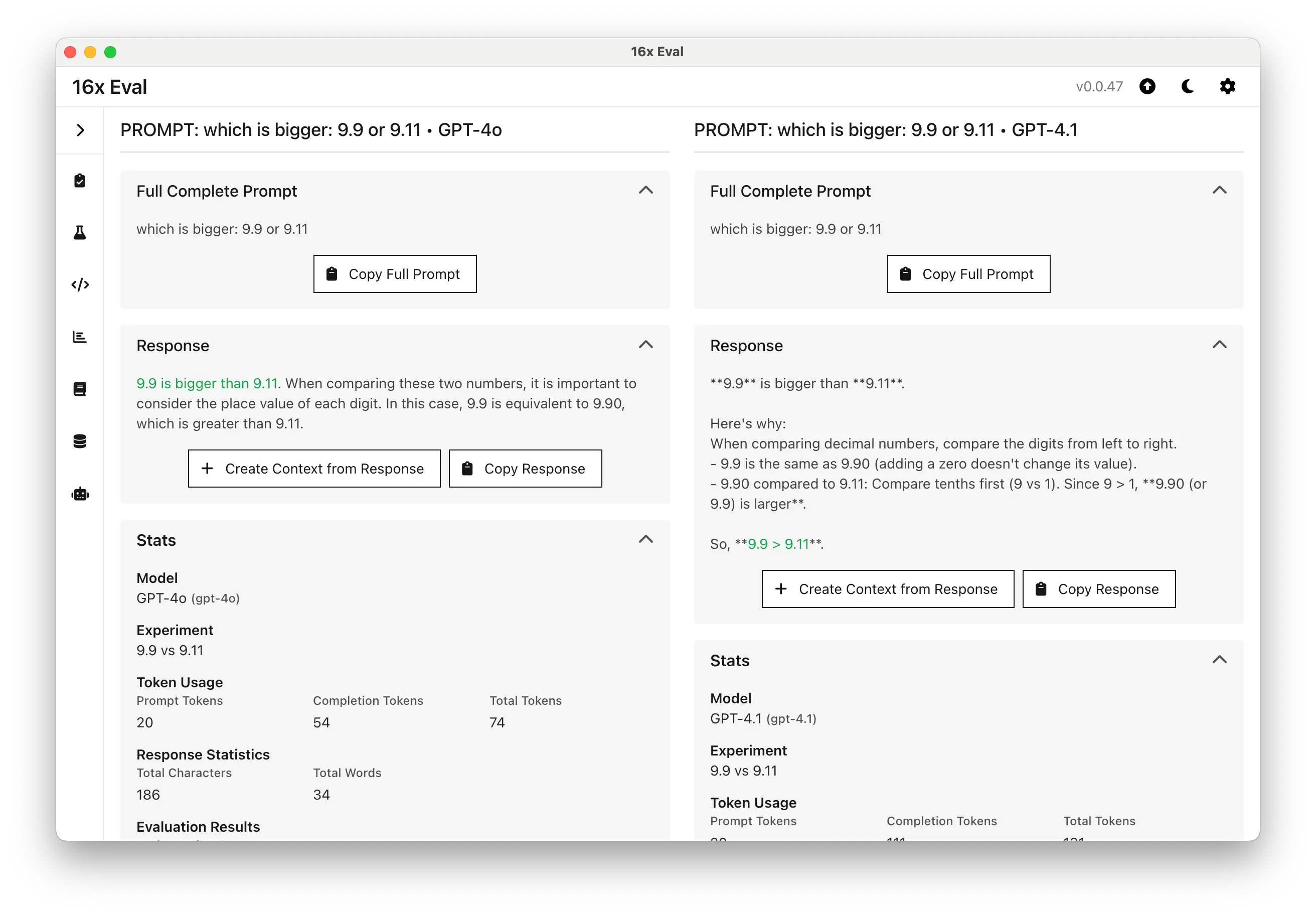
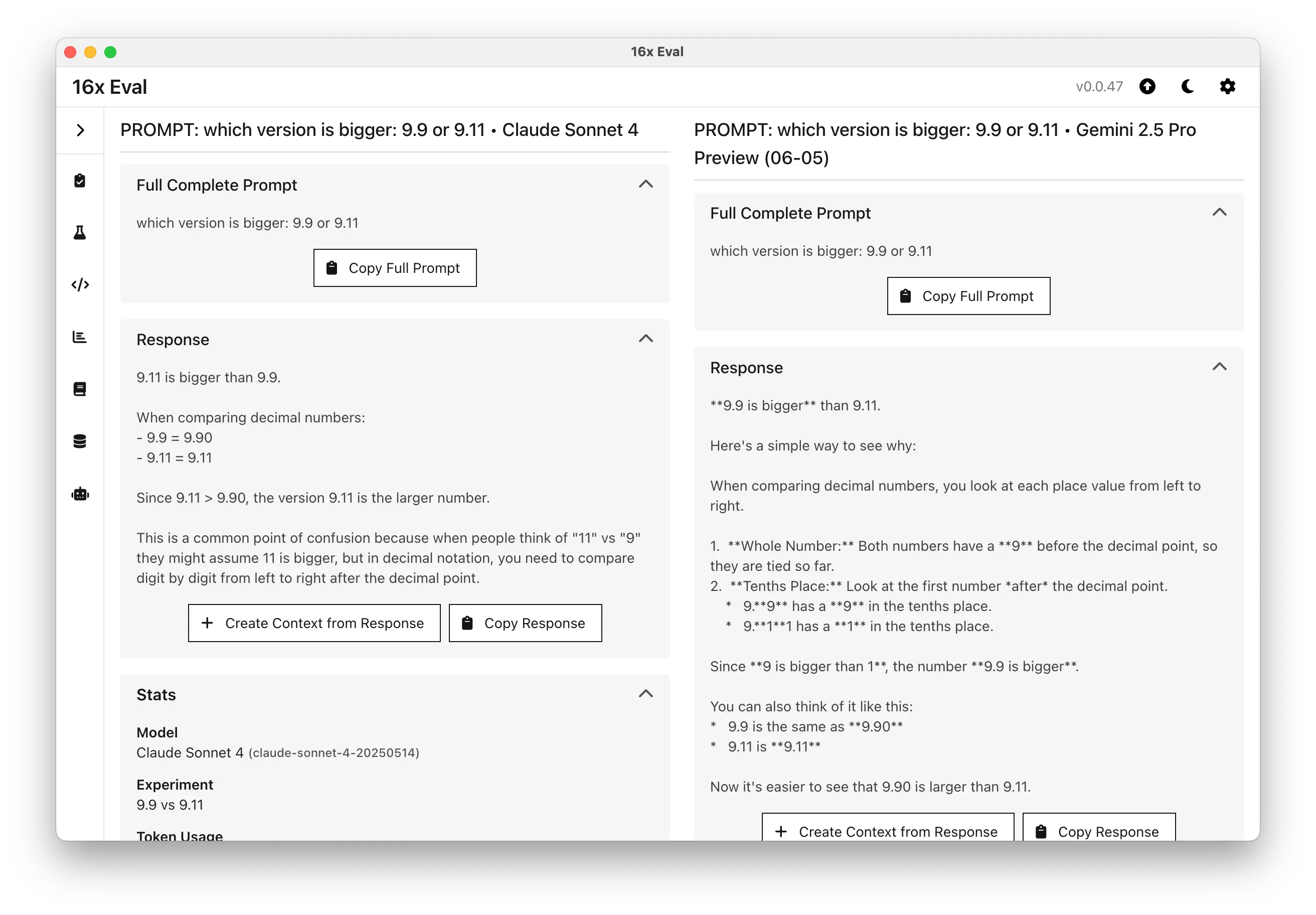
For example, in our testing with the prompt "which version is bigger: 9.9 or 9.11", we got the following results:
- Gemini 2.5 Pro gave the wrong answer (9.9) and the wrong explanation focused on maths.
- Claude Sonnet 4 gave the correct answer (9.11), but the explanation is wrong as it confused the version number for a decimal.
This demonstrates that when faced with a question that can have different answers depending on the context, the model might have a bias towards a certain context (e.g. maths) and pick the wrong context during inference, resulting in the wrong answer or wrong explanation provided.
16x Eval Results
Here are the results from 16x Eval for the experiment on 9.9 vs 9.11 with two prompts:
- the prompt "which is bigger: 9.9 or 9.11" that tests the model on ambiguous context
- the prompt "which version is bigger: 9.9 or 9.11" that tests the model on version number context
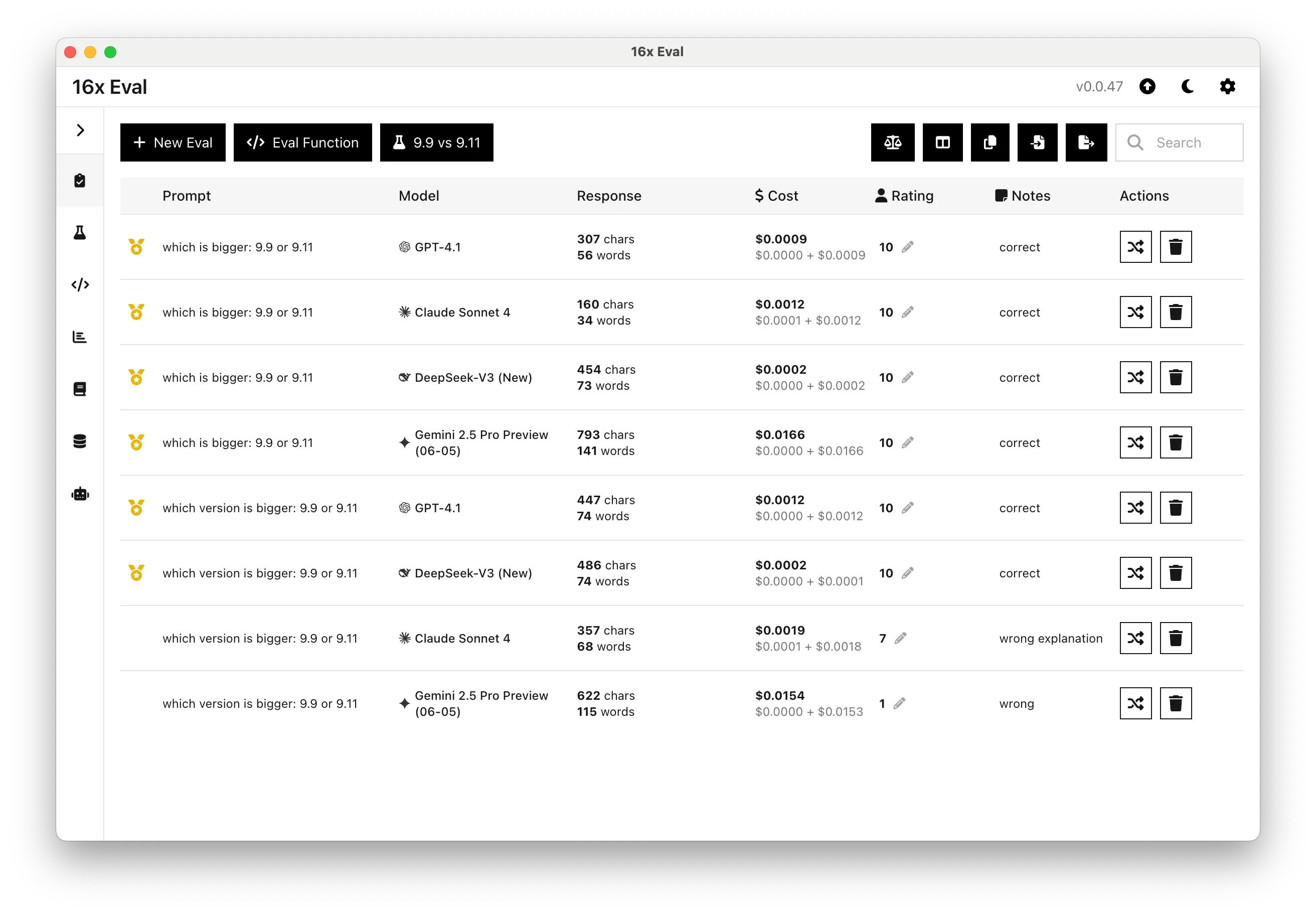
As seen from the results, all models assume you are talking about maths when you ask the question "which is bigger: 9.9 or 9.11", and give the correct answer and explanation.
On the other hand, when you ask the question "which version is bigger: 9.9 or 9.11", some models like Claude Sonnet 4 and Gemini 2.5 Pro starts to give the wrong answer or wrong explanation.
If you are looking to conduct experiments like this to evaluate your prompts and models, you can use tools like 16x Eval to compare model outputs on various metrics, and iteratively refine your prompt.