xAI recently released Grok 4, positioning it as "the most intelligent model in the world" with native tool use and real-time search integration. The model uses reinforcement learning at scale to enhance reasoning capabilities.
We tested Grok 4 across 7 evaluation tasks covering coding, writing, and image analysis to understand its capabilities and limitations. The model outputs were assigned a rating by a human evaluator based on the evaluation rubrics. Our results show Grok 4 performs strongly but comes with notable trade-offs.
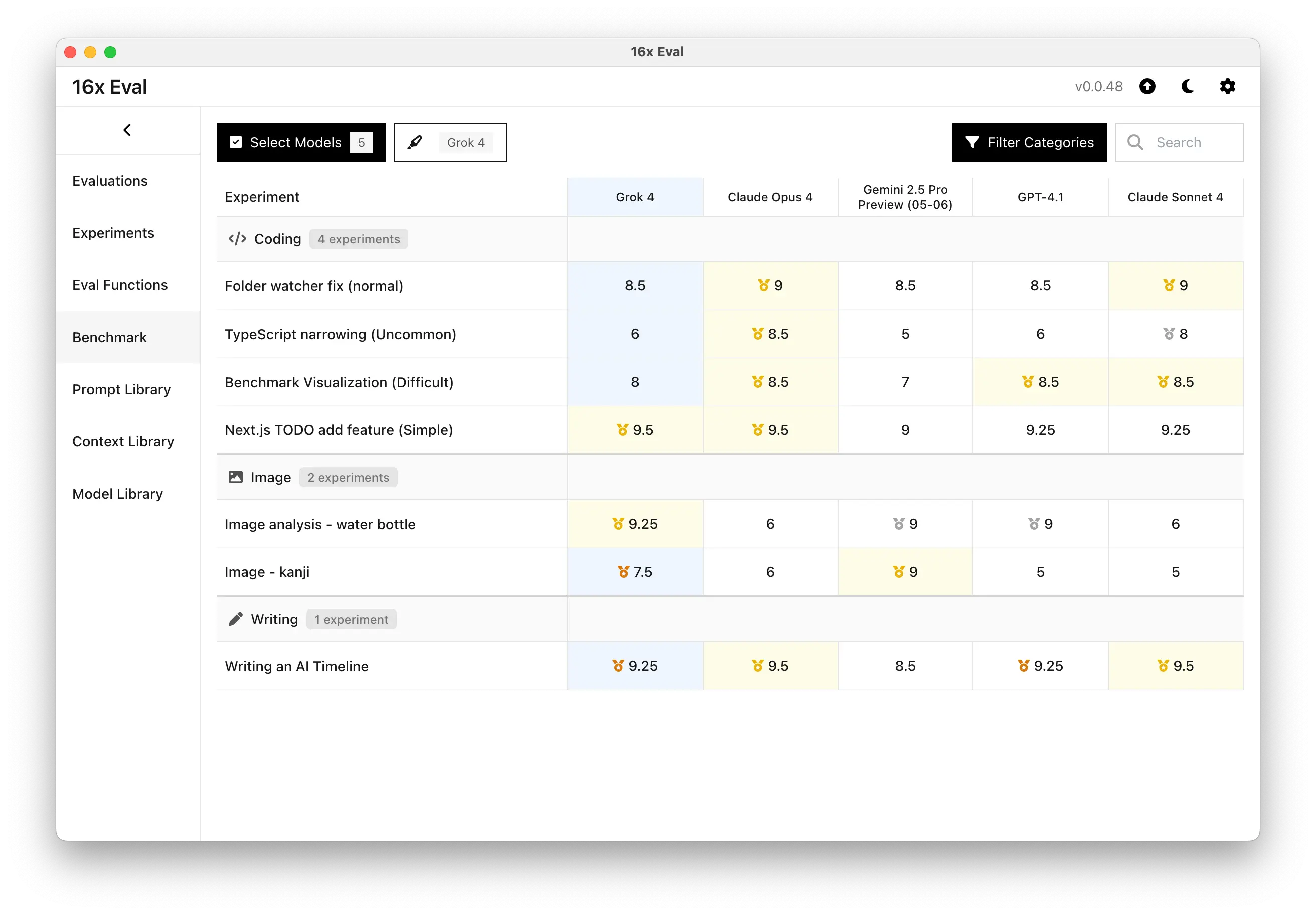
Coding Performance
Grok 4 demonstrates excellent performance on straightforward coding tasks. In our Next.js TODO app feature addition test, it achieved a 9.5/10 rating, tying with Claude Opus 4 and Gemini 2.5 Pro Preview for top performance.
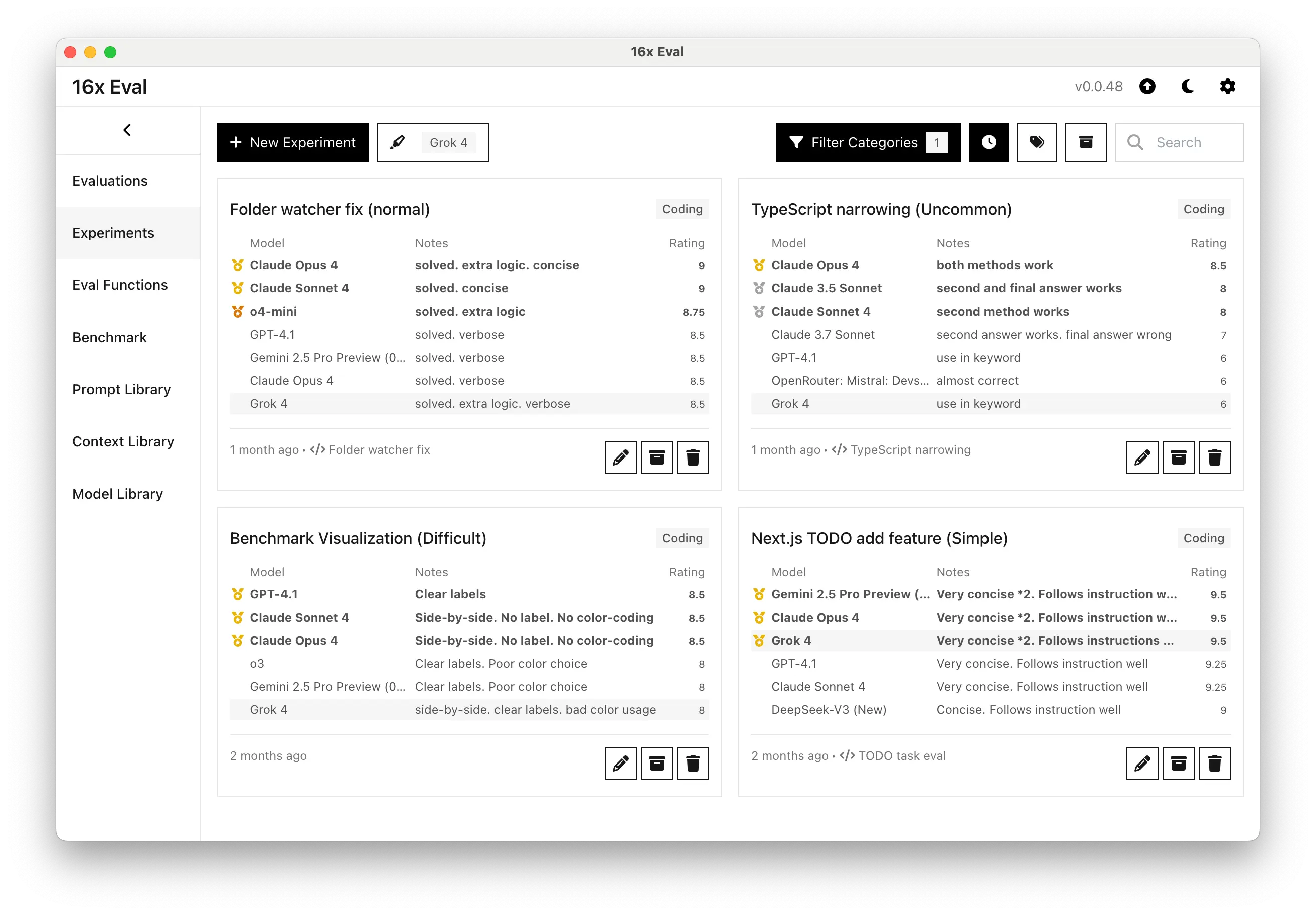
The model produces concise, well-structured code following instructions precisely. For the simple folder watcher fix task, Grok 4 scored 8.5/10, solving the problem with extra logic but in a more verbose manner than the top-performing Claude models.
However, Grok 4 struggles with more complex coding challenges. On the TypeScript narrowing task, it scored 6/10, falling behind Claude Opus 4 (8.5/10) and using less optimal approaches like the in keyword.
The benchmark visualization task revealed similar limitations, with Grok 4 scoring 8/10 compared to Claude models' 8.5/10 performance. Grok 4 produced a decent side-by-side visualization with clear labels. However, its use of colors was not optimal, as it did not use distinct colors for each benchmark, which would have improved readability.
Technical Writing Task
We also put Grok 4 through our standard AI timeline writing task (technical writing). Grok 4 shows strong writing abilities, earning a 9.25/10 rating.
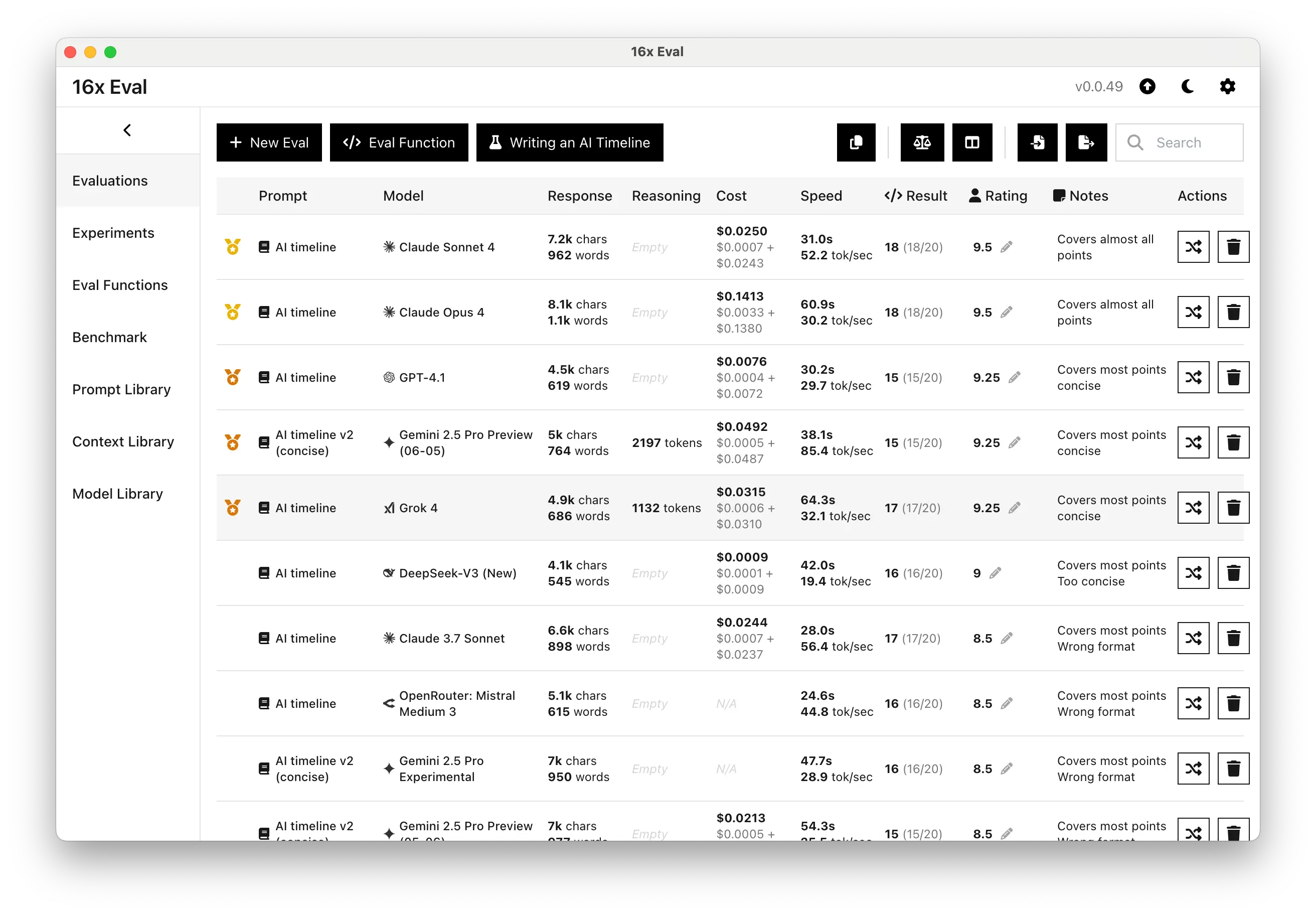
The model covers most required points while maintaining conciseness, placing it among the top performers, just slightly behind Claude Sonnet 4 and Claude Opus 4, and on par with Gemini 2.5 Pro Preview and GPT-4.1.
Strong Image Understanding
One surprising finding from our evaluation is that Grok 4 excels in image analysis tasks, showing particularly strong performance in certain scenarios.
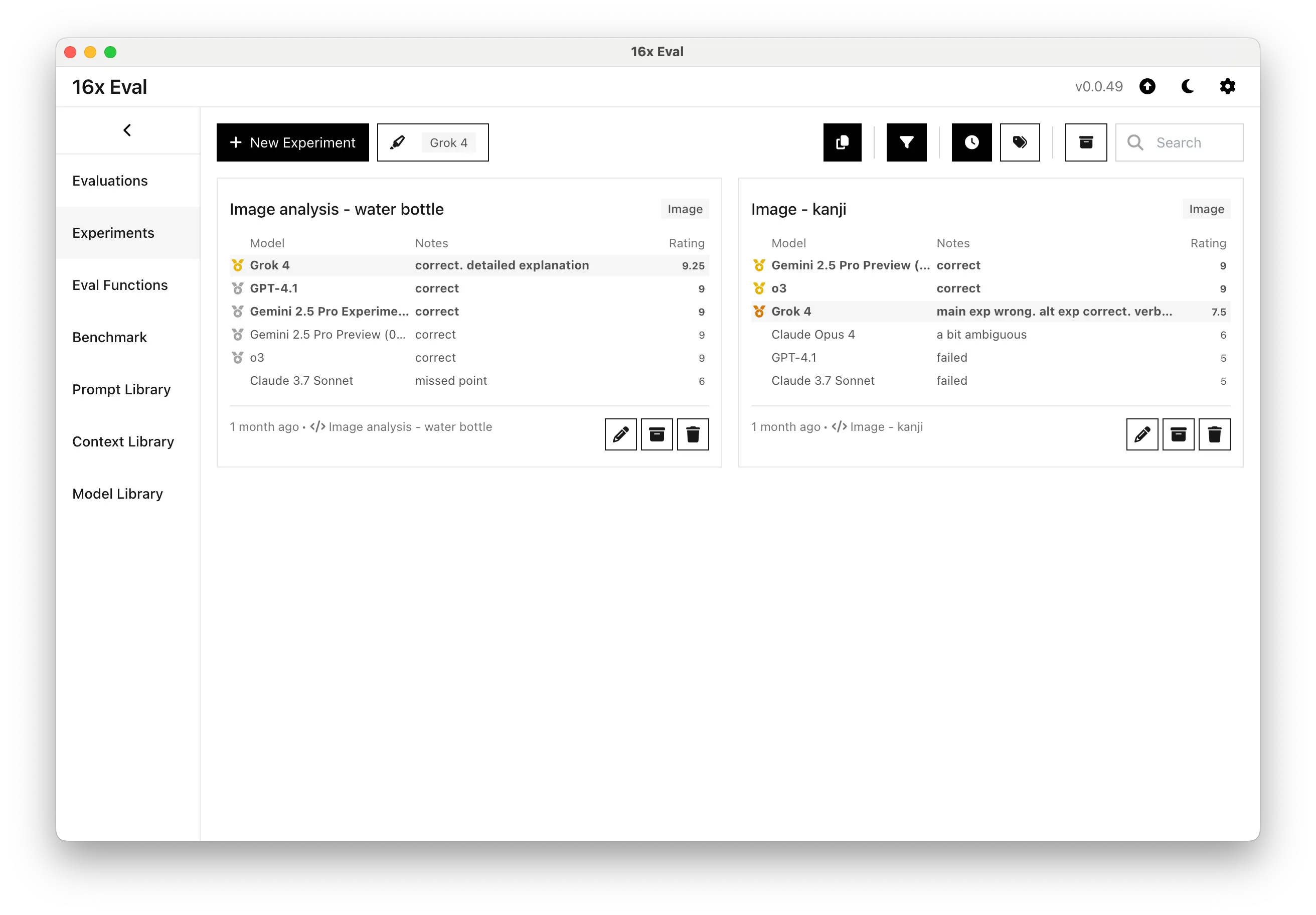
On the water bottle image analysis task, it achieved a 9.25/10 rating with detailed explanations, though it took significantly longer than other models. This is the new highest rating we have seen on this task.

On the kanji recognition task, Grok 4 scored 7.5/10. The main explanation was incorrect, but it did mention the correct answer in the alternative explanations. This places it behind Gemini 2.5 Pro Preview and o3, which gave the right answer in the main explanation.
Slow Response Time
The most significant limitation of Grok 4 is its slow response time. As a thinking model, it generates extensive reasoning tokens before producing responses, leading to response times of 2-4 minutes for complex tasks.
For the TypeScript narrowing task, Grok 4 took 150.3 seconds to respond, compared to Gemini 2.5 Pro Preview's 84.1 seconds. The long response time is mainly due to the model's thinking process before outputting the final response.
| Prompt | Model | Response Time | Output Tokens | Token Speed |
|---|---|---|---|---|
| TypeScript narrowing v3 | GPT-4.1 | 4.1 seconds | 401 | 96.7 t/sec |
| TypeScript narrowing v3 | Claude Sonnet 4 | 10.5 seconds | 597 | 56.8t t/sec |
| TypeScript narrowing v3 | Claude Opus 4 | 21.6 seconds | 637 (*) | 29.5 t/sec |
| TypeScript narrowing v3 | Gemini 2.5 Pro Preview | 84.1 seconds | 8313 | 98.9 t/sec |
| TypeScript narrowing v3 | Grok 4 | 150.3 seconds | 5651 | 37.6 t/sec |
*: The evaluation is conducted without enabling extended thinking for Claude models. Anthropic API does not give stats on thinking tokens.
This long response time makes Grok 4 unsuitable for applications requiring quick responses or real-time interactions. The extended thinking process, while potentially beneficial for complex reasoning, significantly impacts user experience in most practical scenarios.
Summary and Practical Recommendations
Here are areas where Grok 4 excels at:
- Grok 4 works best for deep research tasks where quality matters more than speed. Consider using it for complex analysis, detailed explanations, or tasks requiring thorough reasoning where you can afford to wait for responses.
- The model is particularly effective for image-related tasks where its detailed explanations provide valuable insights.
- Though we did not test it in our evaluation, Grok 4 is capable of performing live search on X, which is a powerful feature for real-time information retrieval.
Here are areas where Grok 4 is not suitable for:
- For coding tasks, it performs competitively with other top models, but the speed penalty may not be justified.
- For applications requiring fast responses, real-time interactions, or iterative development workflows, Grok 4 is not suitable as the response time is too long.
Evaluating Models with 16x Eval
These comprehensive evaluations were conducted using 16x Eval, a desktop application that simplifies AI model comparison across different tasks. The tool allows you to test models systematically and compare their performance on your specific use cases.

16x Eval enables you to create custom evaluations, compare multiple models, and analyze detailed performance metrics including response quality, speed, and cost.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.