Update on September 13, 2025: We have published a new evaluation of GPT-5 with high reasoning effort, which shows a significant performance boost. Check out GPT-5 High Reasoning Coding Evaluation for more details.
OpenAI recently released GPT-5 to much excitement. The model was positioned as OpenAI's "smartest, fastest, most useful model yet," featuring state-of-the-art performance across coding and other domains.
However, the reality after release has been more complicated. Initial enthusiasm quickly turned into mixed reports from users and developers experiencing inconsistent performance in real-world applications.
The Hype and the Reality
Before GPT-5's public launch, early testers shared enthusiastic reports about the model's capabilities. Tech influencer Theo boldly claimed that other models like Claude Opus 4.1 and Claude Sonnet 4 "stopped being relevant today".

But shortly after the public release, users began reporting very different experiences. Theo later acknowledged this disconnect, stating that GPT-5 was "nowhere near as good in Cursor as it was when I was using it a few weeks ago." He noted that the model he was experiencing post-launch could not even "make a todo list" and had slower performance with frequent tool failures.
This sharp difference between early access and public release versions suggests possible changes were made to the model after initial testing, raising questions about what users are actually getting when they use GPT-5 today.
To understand the actual performance of GPT-5, we tested it against our evaluation set.
Coding Evaluation Methodology
We tested GPT-5 against our evaluation set of six coding tasks. For each task, the model was given one attempt, except for the TypeScript narrowing task and the Clean MDX task, where we gave models two tries to account for the tasks' high variance in output and ratings.
We did not specify custom temperature, verbosity, reasoning effort, or other parameters. We used the default settings from the OpenAI API. The default reasoning effort for OpenAI API is medium.
We understand that medium reasoning effort might not be the best setting for complex coding tasks. We plan to do a separate evaluation to test the different reasoning efforts of GPT-5 in the future.
We used prompt variations with slight wording tweaks to perform style control on a best effort basis to help models conform to the output format and adhere to the same verbosity level.
Model outputs were assigned a rating by a human evaluator based on the evaluation rubrics. All prompts, evaluation rubrics, and raw data are available on GitHub.
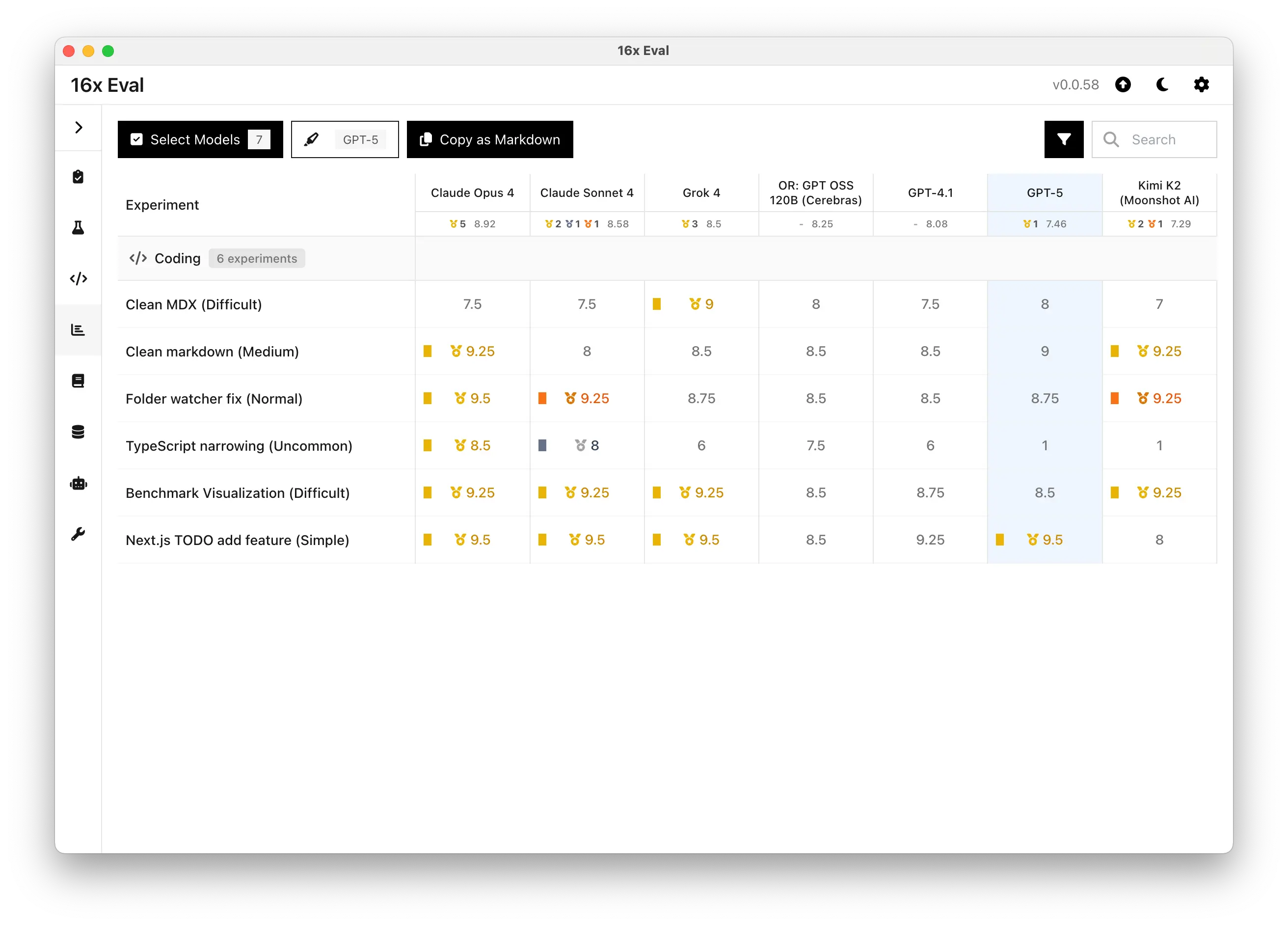
Our Coding Evaluation Results
The GPT-5 evaluation results did not meet our expectations, achieving an average rating of 7.46 out of 10.
Average Rating for Coding Tasks: GPT-5 vs Top Models
This places GPT-5 behind most of the top coding models: Claude Opus 4 (8.92), Claude Sonnet 4 (8.58), Grok 4 (8.5), OpenAI's own open-source gpt-oss-120b model (8.25), and even its predecessor GPT-4.1 (8.08). It is only slightly better than Kimi K2 (7.29).
Needless to say, GPT-5's performance came as a shock for us, as we did not expect it to be worse than GPT-4.1.
Task-by-Task Performance Breakdown
Let's look at how GPT-5 performed on each individual coding task to understand where and why it is underperforming.
GPT-5's worst performance was for the TypeScript narrowing task, where it scored just 1 out of 10. This task tests the model's ability to solve an uncommon problem in TypeScript narrowing.
TypeScript narrowing (Uncommon) Performance Comparison
Both GPT-5 attempts gave incorrect solutions that failed to compile. This shows a clear drop from GPT-4.1, which at least provided a suboptimal working solution using the in keyword (scoring 6/10).
Claude Opus 4 showed the expected performance level by providing multiple working solutions (8.5/10). All other proprietary top coding models were able to give at least a suboptimal solution.
On the benchmark visualization task, GPT-5 scored 8.5 out of 10, which, while good, still puts it behind the leading models.
Benchmark Visualization (Difficult) Performance Comparison
GPT-5 generated a working baseline visualization with clear labels, but missed the visual polish and side-by-side presentation that helped Claude Sonnet 4, Claude Opus 4, and Grok 4 reach the top 9.25 rating.
It is worth noting that in the subsequent real-world test using GPT-5 inside Cursor, the generated visualization was much better, scoring the highest rating of 9.75 we have ever seen.
The folder watcher task showed GPT-5 performing well with a score of 8.75 out of 10. While this shows solid performance, it still lags behind the leading models.
Folder watcher fix (Normal) Performance Comparison
GPT-5 provided a correct solution with helpful extra logic, but was more verbose than optimal. Claude Opus 4 achieved the top score (9.5) by giving both correctness and conciseness.
GPT-5 did well on the simple Next.js TODO task, which primarily tests the model's ability to follow instructions. GPT-5 scored 9.5, tying with the other top models for this task.
When given our v2 concise prompt, GPT-5 was able to follow the instructions and output a very concise solution.
Next.js TODO add feature (Simple) Performance Comparison
GPT-5 did well on the Clean MDX task, which is a difficult task that requires the model to implement complex parsing logic and follow strict requirements. GPT-5 scored 8, tying with gpt-oss-120b and ahead of Claude 4 models. However, it is still behind Grok 4 (9), which is the top model for this task.
Clean MDX (Difficult) Performance Comparison
Here's a summary of the GPT-5 results across all 6 tasks, compared to other models:
Real-World Testing: Cursor vs Claude Code
In addition to our structured evaluation using coding eval tasks, we also compared Cursor with GPT-5 and Claude Code with Sonnet 4 on 4 real-world development tasks across 2 projects in a YouTube livestream.
We used the default settings for Cursor (gpt-5, medium reasoning effort) and Claude Code (Sonnet 4).
GPT-5 showed much better performance in real-world testing when using agentic tools, compared to our structured evaluation, which tests the model's raw coding capabilities.
Our real-world testing results showed similar performance between the two setups. Cursor and GPT-5 did better on some tasks, while Claude Code with Sonnet 4 did better on others.

For the YouTube thumbnail generator project, Claude Code with Sonnet 4 performed better. It implemented the features exactly as requested and understood the intent of the requirements better, with nice touches on UI and UX. Cursor + GPT-5 also produced a functional implementation, but lacked details and thoughtfulness on how they should work.
For the model benchmark visualization project, Cursor with GPT-5 produced a better visualization that fulfilled all the requirements and was also visually pleasing. It is also the first model to output horizontal bars instead of vertical bars, which is a nice touch. Claude Code gave a decent output but missed the requirement for labels.
It is also worth noting that Claude Code gave a faster response compared to Cursor with GPT-5 because GPT-5 had to engage in a long thinking process (30 seconds to 1 minute for complex tasks) before generating the output. This speed difference could affect developer productivity in real-world settings.
Watch the livestream video below to see the full details:
Reasons for the Performance Gap
We don't know the exact reason for the apparent performance gap between the expectations and the reality. But we have some hypotheses:
OpenAI employee Edwin suggests that GPT-5 requires different prompting methods than previous models. He notes that GPT-5 is "extremely steerable" but needs users to "be more explicit" about what they are trying to accomplish. The model may perform poorly when users apply prompting strategies that worked for previous models without adapting.
This fits with our own previous research on model-specific prompting techniques, which showed that different models need different approaches to get optimal results. GPT-4.1 worked well with simple, clear instructions. Claude models needed stronger, repeated instructions, and Gemini required explicit conciseness prompts.
Another possibility suggested by Theo in his video is that OpenAI made changes to the model between early access testing and public release. These changes could have affected performance characteristics, explaining the difference between early positive reports and more mixed real-world experiences.
Summary: Incremental, Not Revolutionary
Our evaluation shows that GPT-5 does not live up to the revolutionary claims made during its launch. While the model shows strong coding capabilities on standard tasks, it represents a small improvement at best, and in some areas, actually drops below its predecessor GPT-4.1 and the open-source version gpt-oss-120b.
The most concerning finding is GPT-5's complete failure on the TypeScript narrowing task, where it could not produce working code despite multiple attempts. This hints at significant gaps in the model's understanding of advanced programming concepts.
This could be due to the fact that we did not specifically tune the prompts for GPT-5. However, it would be the first time that a model required specific tuning for raw coding performance. We did optimize prompts for Claude and Gemini models, but that was just for style control of verbosity and formatting, not to get better coding capabilities.
Importance of Prompt Engineering
Regardless of GPT-5's performance, one thing is clear from the community feedback and OpenAI's communications:
Prompt engineering is a key component for extracting the best results from a new model. When a new model seems to underperform, it may be that the prompts, not the model, need improving.
This is especially true for a highly "steerable" model like GPT-5. Unlocking its full potential needs a change from expecting easy compatibility to using a more careful process of prompt engineering.
We recommend checking out OpenAI's official GPT-5 prompting guide for more details on how to get the most out of GPT-5.
If you are looking for a tool to test prompts and models, check out 16x Eval. 16x Eval is a desktop application built for systematic AI model evaluation and prompt engineering.
It provides powerful features to tune and perfect your prompts. You can create and test multiple prompt variations, compare outputs side by side against custom evaluation functions, and improve your prompt iteratively.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.