xAI has introduced Grok Code Fast 1, a model designed for speed and economy in agentic coding workflows. This model was previously released in stealth as Sonic. It was built from a new architecture and trained on a programming-rich corpus to handle common developer tasks efficiently.
In this post, we take a look at Grok Code Fast 1's performance on our coding evaluation set to understand its strengths and weaknesses compared to other leading proprietary and open-source models. Our tests show it is a solid performer with a few notable exceptions.
Evaluation Setup
We tested Grok Code Fast 1 across seven distinct coding tasks using the official xAI API (grok-code-fast-1). The tasks covered a range of complexities, from simple feature implementation to complex bug fixing and data visualization.
For each task, a human evaluator assigned a rating based on the predefined evaluation rubrics, including correctness, conciseness, and adherence to instructions. Some tasks allowed for multiple attempts to account for variability in model responses.
To ensure a fair comparison, we used the default temperature settings provided by xAI. We noted that Grok Code Fast 1 has a "thinking" step before generating a response, which adds to its response time.
We livestreamed the entire evaluation process on YouTube, you can check out the video here.
Overall Performance vs Top Models
Overall, Grok Code Fast 1 positions itself as a competitive model in terms of cost efficiency. It did well on several tasks, scoring a respectable 7.64 average rating. This places it behind top performers like Claude Opus 4 and Grok 4. However, its performance is comparable to some established models like Gemini 2.5 Pro.
Average Rating for Coding Tasks: Grok Code Fast 1 vs Top Models
Given the fast token throughput of Grok Code Fast 1 at around 100 tokens per second, it is safe to assume that this is a smaller model than most of the top proprietary models. Hence it makes more sense to compare it with open-source models that are typically smaller in model size.
When compared to top open-source models, Grok Code Fast 1 secures the second position, outperforming models like Qwen3 Coder and Kimi K2. It only trails gpt-oss-120b, making it a strong option in the open-source landscape.
Average Rating for Coding Tasks: Grok Code Fast 1 vs Top Open-Source Models
For those looking for the cost / performance ratio, here's a table showing the ratings and pricing for the models similar to Grok Code Fast 1.
| Model | Rating | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|---|
| GPT-4.1 | 8.21 | $2.00 | $8.00 |
| Gemini 2.5 Pro | 7.71 | $1.25 ($2.50 >200k) | $15.00 |
| Grok Code Fast 1 | 7.64 | $0.20 ($0.02 cached) | $1.50 |
| Qwen3 Coder (Fireworks) | 7.25 | $0.45 | $1.80 |
| Qwen3 Coder (Cerebras) | 7.25 | $2.00 | $2.00 |
| DeepSeek V3 (New) (Fireworks) | 6.7 | $0.90 | $0.90 |
| DeepSeek V3 (New) (Together) | 6.7 | $1.25 | $1.25 |
The input price is much cheaper than similar models, but the output price is not as attractive as DeepSeek V3 (New).
Strong Performance on Coding Tasks
Grok Code Fast 1 showed excellent performance on several tasks, often matching or exceeding top-tier models. In particular, it excelled in tasks requiring concise and correct code generation. This shows its practical utility for everyday development work.
In the folder watcher fix task, the model achieved the top score of 9.5 out of 10, tying with Claude Opus 4 and ahead of top models like Claude Sonnet 4 and GPT-4.1.
Folder watcher fix (Normal) Performance Comparison
It not only solved the primary problem but also included extra helpful logic. The response was remarkably concise, one of the shortest among all models tested, highlighting its ability to follow instructions and generate efficient code.
The model showed impressive capability on the difficult TypeScript narrowing task, scoring 8 out of 10 on its second attempt.
TypeScript narrowing (Uncommon) Performance Comparison
It correctly used a type predicate, an advanced TypeScript technique that many other models failed to apply. This ability to handle uncommon and complex programming patterns is a significant strength.
Surprising Weakness on Tailwind
Despite its strengths, Grok Code Fast 1 did surprisingly poorly on the Tailwind CSS v3 z-index task, a new task that was recently added to our evaluation set.
Grok Code Fast 1 scored just 1 out of 10. In both attempts, it failed to identify that the bug was caused by an invalid class name specific to Tailwind CSS v3.
Tailwind CSS v3 z-index Performance Comparison
This is typically an easy task for the top models. We suspect that this is because Grok Code Fast 1 has a smaller model size, or that the model was not sufficiently trained on Tailwind CSS, which makes it less capable of handling this kind of task.
Here is a summary of the Grok Code Fast 1's ratings across all tasks, compared to other top models:
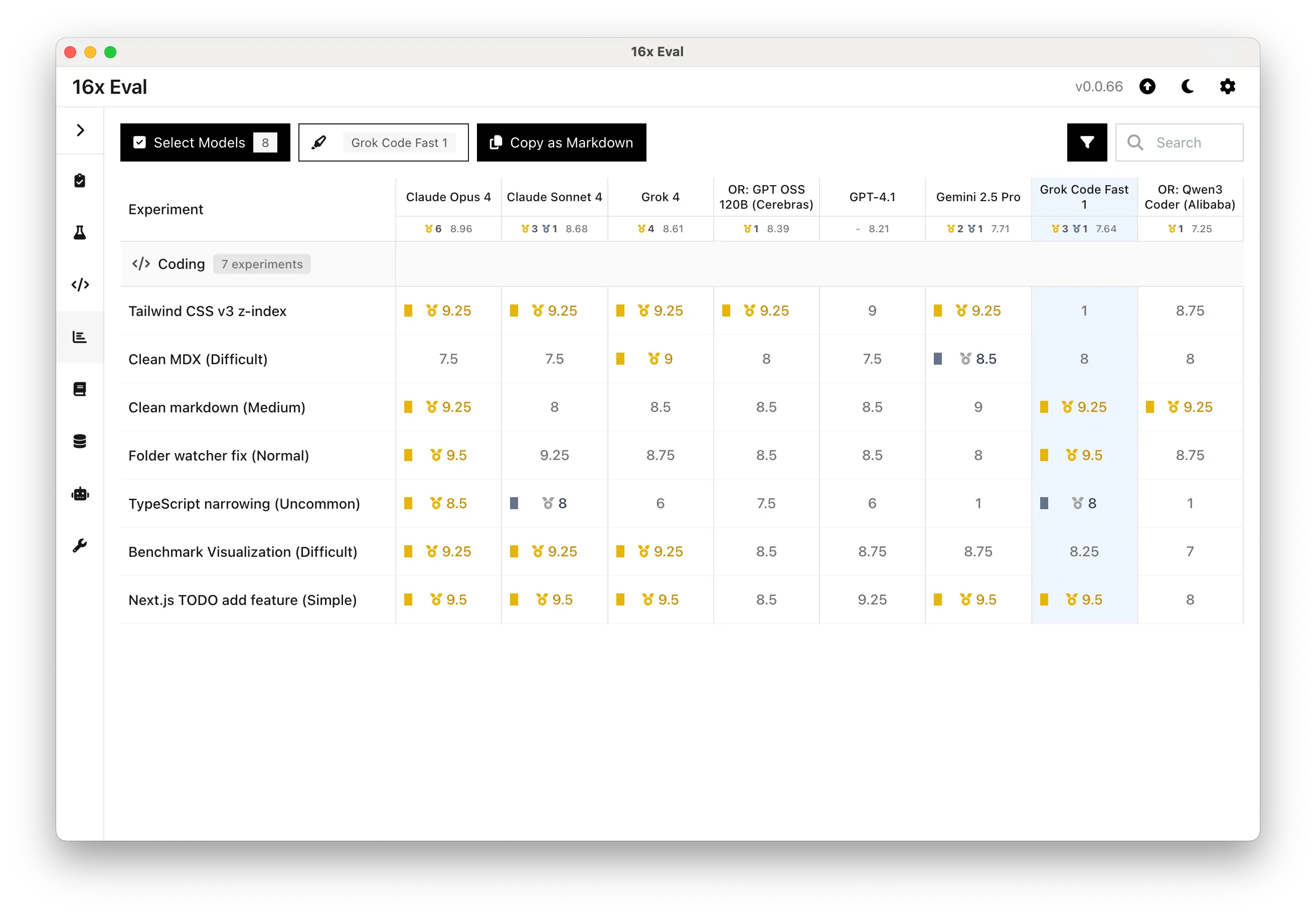
We can see that Grok Code Fast 1 did well on majority of tasks, but it struggled with the Tailwind CSS v3 z-index task.
Conclusion & Note on Reasoning
Grok Code Fast 1 showed solid performance, achieving top ratings for several tasks. One notable exception is its poor performance on the Tailwind CSS task. It is a competitive option for a cost-effective coding model.
Due to its nature as a reasoning model, it is not suitable for interactive workflows requiring fast responses despite its fast token throughput. This is because the model needs to generate a lot of reasoning tokens before outputting the final response. Large amount of reasoning tokens can also lead to higher cost.
This evaluation was conducted using 16x Eval, a desktop application that helps you systematically test and compare AI models.

16x Eval makes it easy to run standardized evaluations across multiple models and providers, analyze response quality, and understand each model's strengths and weaknesses for your specific use cases.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.