DeepSeek has released DeepSeek-V3.1, the latest iteration of its language model. This version introduces a unified model with hybrid inference, combining "Think" and "Non-Think" modes into a single API endpoint.
We put DeepSeek-V3.1 to the test on our coding evaluation set. Our findings show a mixed performance, with the model doing well in some areas but struggling significantly in others, even showing a regression compared to its predecessor.
Evaluation Methodology
We tested DeepSeek-V3.1 non-thinking mode (deepseek-chat) on seven distinct coding tasks of varying difficulty. These tasks range from simple feature implementation to complex bug fixing and data visualization. All tests were conducted directly against the official DeepSeek API to avoid any third-party intermediaries.
For all coding tasks, we set the temperature to 0.0, following the official recommendation from DeepSeek's documentation for coding and math problems.
Each model's output was rated by a human evaluator based on correctness, conciseness, and adherence to instructions, following our established evaluation rubrics.
We livestreamed the entire evaluation process on YouTube, you can check out the video here.
Performance Against Other Models
Overall, DeepSeek-V3.1's performance was underwhelming. It achieved an average rating of 5.68, which is considerably lower than top models like Claude Opus 4, Claude Sonnet 4, Grok 4 and GPT-4.1.
Average Rating for Coding Tasks: DeepSeek-V3.1 vs Top Models
How about open-source models? Not much better. If we compare DeepSeek-V3.1 against leading open-source models, it also performed worse than models like gpt-oss-120b, Qwen3 Coder and Kimi K2.
Average Rating for Coding Tasks: DeepSeek-V3.1 vs Leading Open-Source Models
More surprisingly, DeepSeek-V3.1 performed worse than its predecessor, DeepSeek-V3 (New), on some of the tasks in our evaluation.
| Task | DeepSeek-V3 (New) | DeepSeek-V3.1 |
|---|---|---|
| Clean markdown (Medium) | 8 | 9.25 |
| Folder watcher fix (Normal) | 8.5 | 8.5 |
| TypeScript narrowing (Uncommon) | 1 | 1 |
| Benchmark Visualization (Difficult) | 7 | 5.5 |
| Next.js TODO add feature (Simple) | 9 | 8 |
DeepSeek deprecated access to the DeepSeek-V3 (New) model in the API on 21 August 2025 when the new model was released. Therefore, we are unable to compare the performance of the two models directly on newly added tasks.
Individual Task Performance
DeepSeek-V3.1's performance varied greatly across different tasks. It demonstrated strong capability on a standard code generation task but failed on challenges requiring deeper logical reasoning or specialized knowledge.
The model's best performance was on the clean markdown task, where it scored an impressive 9.25 out of 10. It generated a correct and concise function that perfectly matched the requirements. This score places it at the top, alongside models like Claude Opus 4 and Qwen3 Coder, and ahead of Claude Sonnet 4, GPT-4.1 and Grok 4.
Clean markdown (Medium) Performance Comparison
However, DeepSeek-V3.1 struggled with the uncommon TypeScript narrowing task, scoring only 1 out of 10. The task requires fixing a tricky type error, and the model failed to produce a working solution in both of its attempts.
TypeScript narrowing (Uncommon) Performance Comparison
This is a common failure point for many open-source models, highlighting a gap in handling advanced or unusual programming patterns.
Here is a summary of the model's ratings across all tasks, compared to other top models:
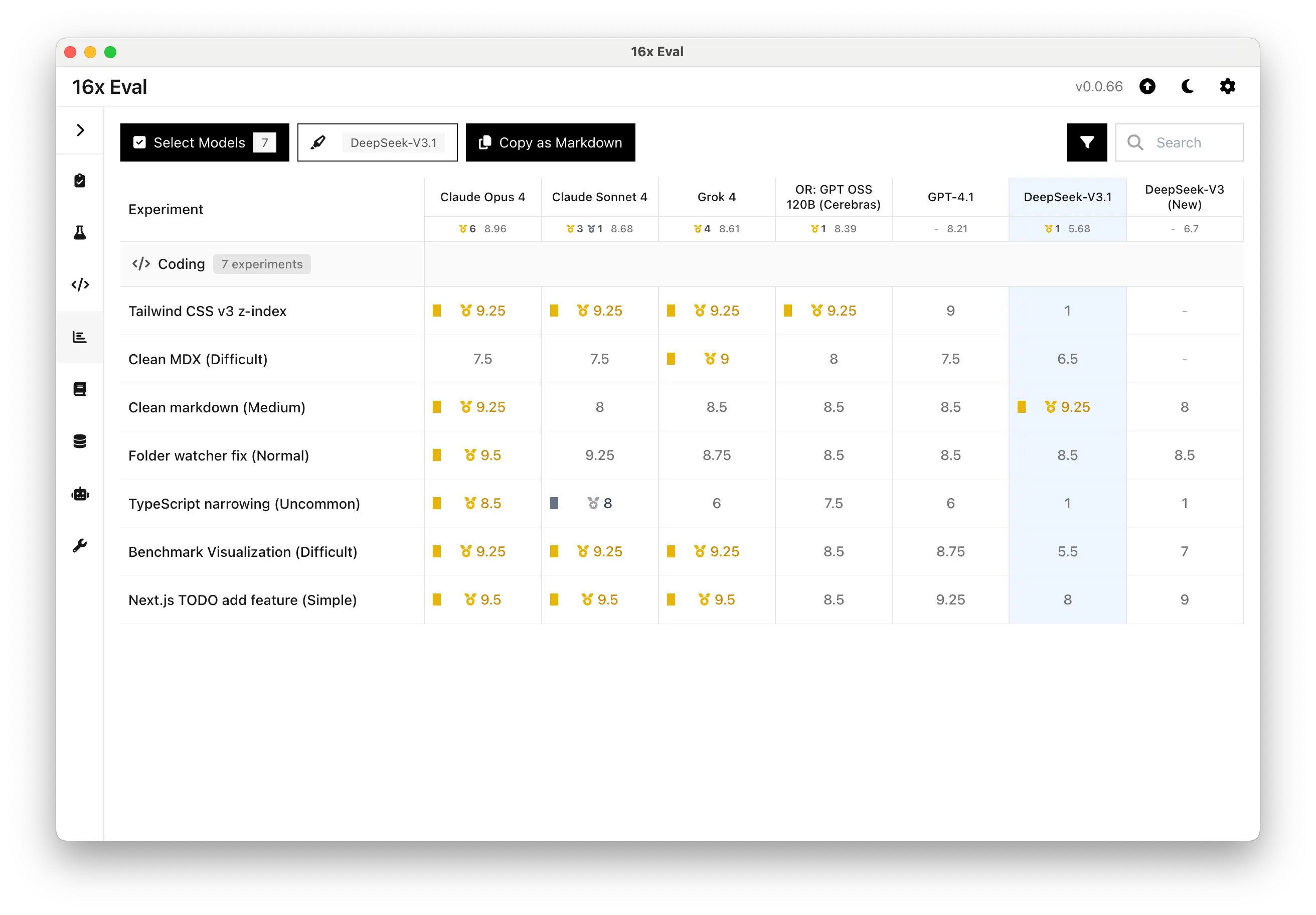
Note that we are unable to test DeepSeek V3 (New) on the new tasks since it was deprecated on 21 August 2025.
Other Notable Observations
The model's weaknesses were also apparent in other tasks. On the Tailwind CSS V3 bug-fixing challenge, it failed to identify invalid classes for z-index (z-60 and z-70), scoring just 1 out of 10. This is a task that is very easy for other top coding models.
For the benchmark visualization task, it produced a vertical line chart that is very difficult to read, earning a low score of 5.5.
It is particularly interesting that the visualization generated by the model was very close to Horizon Alpha's output:
Horizon Alpha is an early checkpoint of GPT-5 that was released as a stealth model.
Furthermore, DeepSeek-V3.1 showed poor instruction-following on a simple Next.js feature addition task. We tried 3 prompt variations, explicitly asking for only the code that needs to be changed, but the model repeatedly outputted the entire file. This stubbornness resulted in a lower score compared to its predecessor and other models that followed instructions correctly.
Conclusion
DeepSeek-V3.1's coding performance was mixed, with some areas showing strong capabilities and others struggling significantly. It is far from the best coding model we have tested, and even showed signs of regression compared to its predecessor on some tasks.
If you are looking for a good coding model, we continue to recommend using Claude Sonnet 4 (top coding model that is affordable) or Qwen3 Coder (open-source, cheap and good agentic coding capability). Check out our evaluations results for the test results for the latest coding models.
This evaluation was conducted using 16x Eval, a desktop application that helps you systematically test and compare AI models.

16x Eval makes it easy to run standardized evaluations across multiple models and providers, analyze response quality, and understand each model's strengths and weaknesses for your specific use cases.
Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.