OpenAI's new open-source model, gpt-oss-120b, has emerged as a strong contender in the coding space. Our evaluation shows this 120-billion parameter model achieving impressive results on coding tasks.
Key findings from our evaluation:
- New leader among open-source coding models, outperforming Kimi K2 and Qwen3 Coder
- Still behind Grok 4, Claude Sonnet 4, and Claude Opus 4
- Excels at speed with over 500 tokens per second through Cerebras
Evaluation Setup and Methodology
We tested gpt-oss-120b across five diverse coding challenges to understand its capabilities and limitations compared to current top models.
We conducted our evaluation using Cerebras as the provider via OpenRouter, which our previous analysis showed delivers consistent high-quality outputs for the gpt-oss-120b model. All tests used the default temperature settings from the provider. The model outputs were assigned a rating by a human evaluator based on the evaluation rubrics.
Each task received one attempt, except for the TypeScript narrowing challenge where we gave models two tries to account for the task's high variance in ratings.
We livestreamed the entire evaluation process on YouTube, you can check out the video here.
Individual Task Performance
gpt-oss-120b demonstrated solid performance across our five coding tasks, showing strengths in both standard programming challenges as well as more specialized tasks.
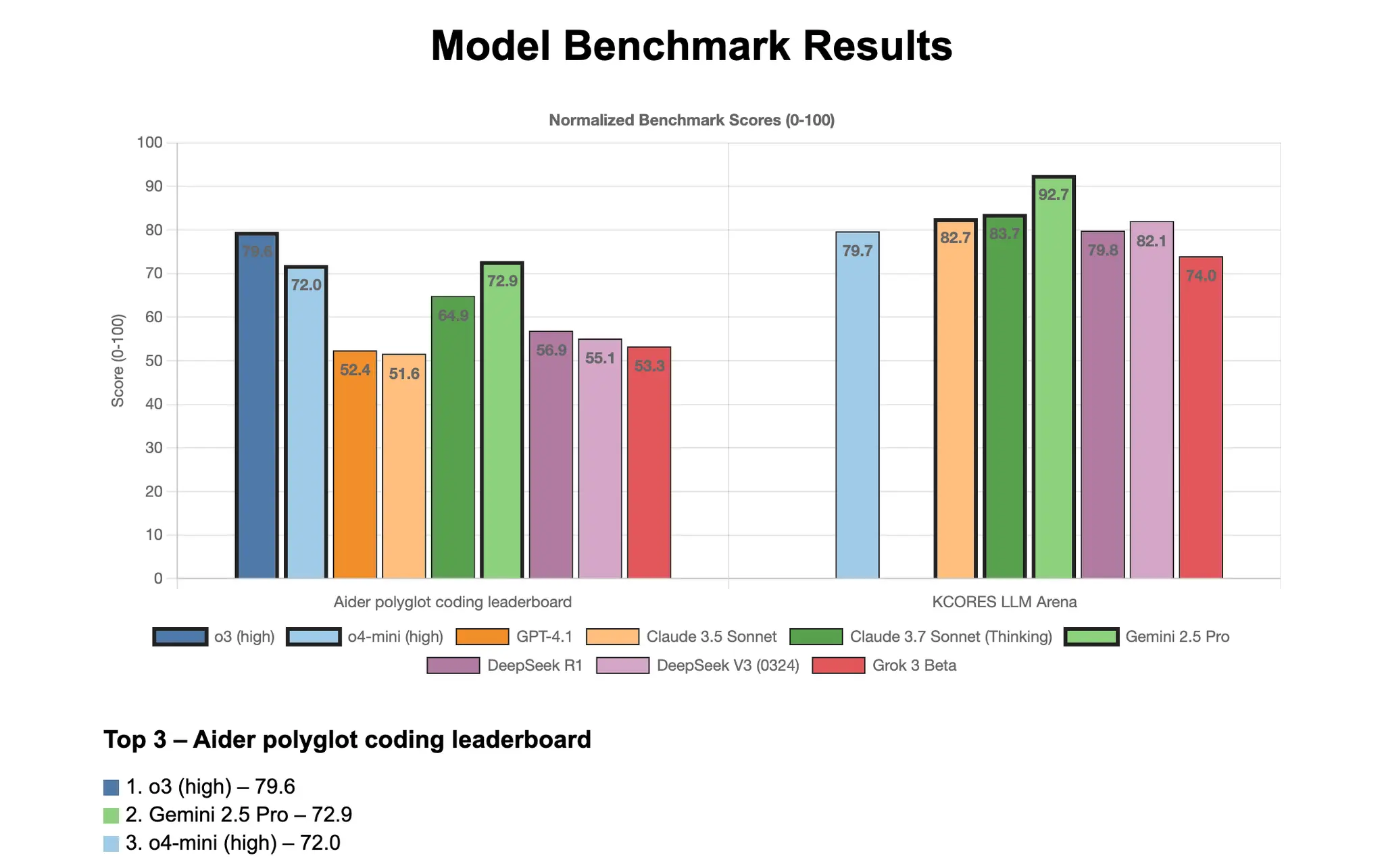
On the clean markdown task, gpt-oss-120b scored 8.5 out of 10, placing it among the solid performers. The code generated by the model resulted in a single newline issue in the output that prevented it from reaching the top tier occupied by Claude Opus 4, Kimi K2, and Qwen3 Coder (all scoring 9.25).
Clean markdown (Medium) Performance Comparison
In the folder watcher task, gpt-oss-120b got a 8.5 out of 10 rating, tying with GPT-4.1. The output was not as concise as the top models, but it was correct.
Folder watcher fix (Normal) Performance Comparison
We updated the rubrics for the TypeScript narrowing task to give models two attempts to handle the task's inherent variance. Based on the new rubrics, gpt-oss-120b scored 7.5 out of 10 for this task.
It provided two solutions in both attempts. And in both attempts, the first solution failed while the second worked correctly. Notably, gpt-oss-120b gave two different correct solutions for two attempts.
And in one response, gpt-oss-120b suggested adding a separate kind discriminant, a novel approach that no other model proposed.
To our surprise, even with the updated rubrics that allow for two attempts, open-source models like Kimi K2 and Qwen3 Coder still scored only 1 out of 10, highlighting the difficulty of this task for most open-source models.
TypeScript narrowing (Uncommon) Performance Comparison
For the benchmark visualization task, gpt-oss-120b achieved a solid 8.5 out of 10. The model generated a functional baseline visualization with clear labels, though it lacked some of the visual polish seen in top-scoring responses from Claude Sonnet 4, Claude Opus 4, and Kimi K2 (all scoring 9.25).
Benchmark Visualization (Difficult) Performance Comparison
The Next.js TODO task showed gpt-oss-120b's inherent verbosity. Despite correctly following the instructions and outputting only code that requires changes, the output was still verbose, which earned it an 8.5 out of 10 rating.
Even with a revised prompt with explicit "Be concise" instructions, the model still gave a verbose result, suggesting this verbosity is a characteristic of the model.
This places gpt-oss-120b behind models like Claude Opus 4 and Grok 4, which achieved 9.5 ratings through more concise responses. However, it is still better than Kimi K2 (8) which did not follow the instructions.
Next.js TODO add feature (Simple) Performance Comparison
Performance Comparison with Leading Models
When we compare gpt-oss-120b's overall coding performance to top proprietary models, it is surprisingly competitive at an average rating of 8.3.
Average Rating for Coding Tasks: gpt-oss-120b vs Top Models
gpt-oss-120b is very closely behind Grok 4 (8.4), establishing itself in the upper tier of coding models as it surpasses GPT-4.1 (8.2) and substantially outperforms Gemini 2.5 Pro (7.25).
The model falls behind the Claude 4 family, with Claude Opus 4 leading at 9.2 and Claude Sonnet 4 at 8.75. However, this is expected for a smaller model of just 120 billion parameters.
Among open-source models, gpt-oss-120b outperforms both Kimi K2 (7.35) and Qwen3 Coder (6.8), establishing itself as the new top model for developers seeking capable open-source coding solutions.
Average Rating for Coding Tasks: gpt-oss-120b vs Top Open-Source Models
Fast Speed
Beyond raw performance scores, gpt-oss-120b excels in speed due to its small model size. Through the Cerebras provider, the model reaches the speed of over 500 tokens per second on some tasks, and averaging above 400 tokens per second overall*. In comparison, most other models can only go up to a maximum speed of 100 tokens per second.
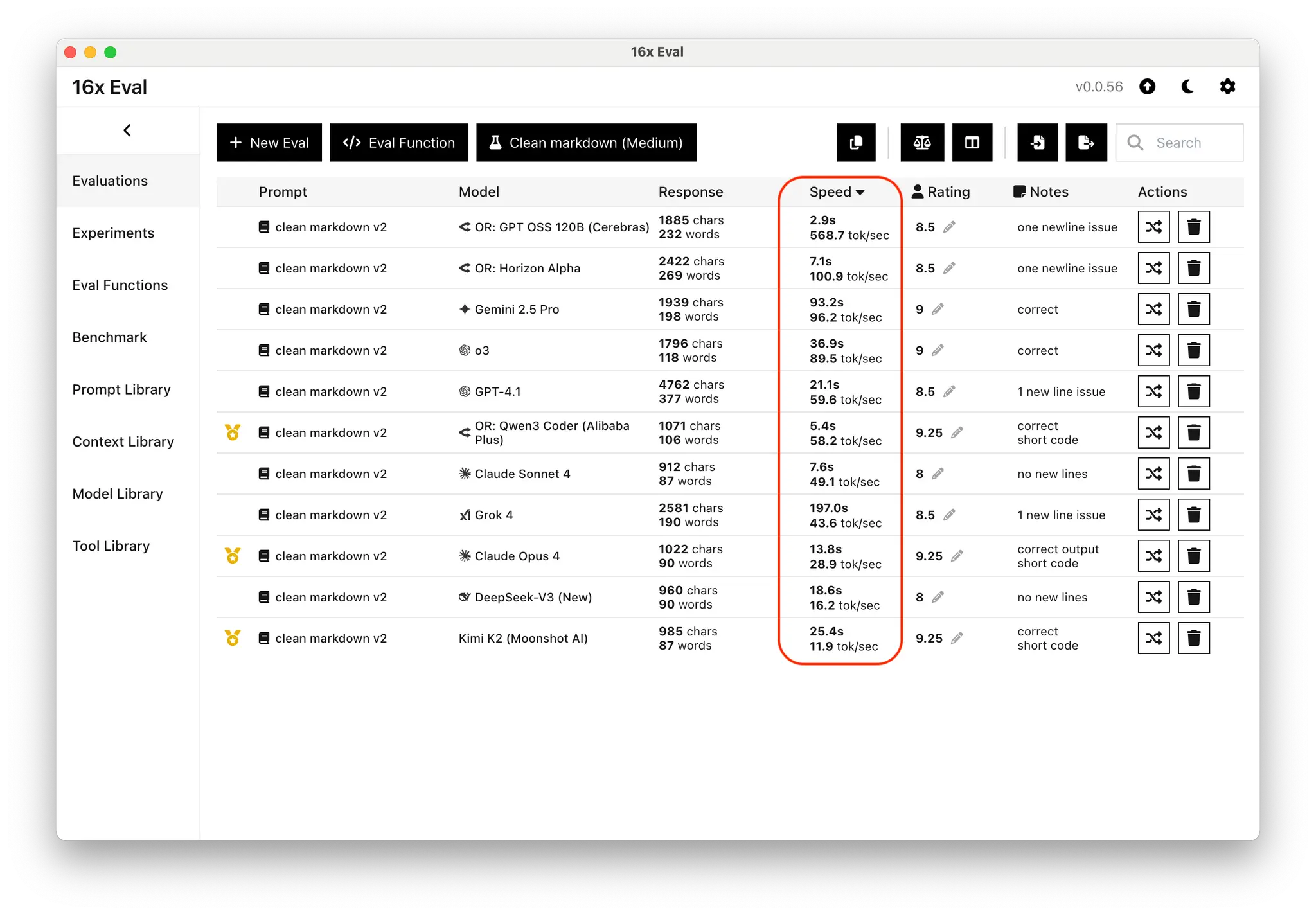
The combination of competitive performance and high speed positions gpt-oss-120b as particularly suitable for interactive development workflows where developers want rapid feedback cycles.
*: The speed is measured based on the entire request duration, including latency to first byte. Since the test is conducted in Singapore, network latency might have contributed to the lower speed than the officially reported 3000 tokens per second.
This evaluation was conducted using 16x Eval, a desktop application that helps you systematically test and compare AI models. 16x Eval makes it easy to run standardized evaluations across multiple models and providers, analyze response quality, and understand each model's strengths and weaknesses for your specific use cases.

Evaluation Methodology: All ratings in this evaluation are human ratings based on a set of criteria, including but not limited to correctness, completeness, code quality, creativity, and adherence to instructions.
Prompt variations are used on a best-effort basis to perform style control across models.